你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
了解如何使用 Apache Spark MLlib 创建机器学习应用程序。 应用程序会对开放数据集执行预测分析。 本示例摘自 Spark 的内置机器学习库,它通过逻辑回归使用分类。
MLlib 是一个核心 Spark 库,它为以下机器学习任务提供了许多有用的实用程序:
- 分类
- 回归
- 群集功能
- 建模
- 单值分解 (SVD) 和主体组件分析 (PCA)
- 假设测试和计算示例统计信息
了解分类和逻辑回归
“分类”是一种很常见的机器学习任务,是将输入数据归入各类别的过程。 分类算法的作用是确定如何为你提供的输入数据分配“标签”。 例如,可以考虑一个接受股票信息作为输入的机器学习算法。 然后将股票分为两类:应该出售的股票和应该保留的股票。
逻辑回归是用于分类的算法。 Spark 的逻辑回归 API 可用于“二元分类” ,或将输入数据分类为两个组之一。 有关逻辑回归的详细信息,请参阅 维基百科。
总而言之,逻辑回归过程会生成一个逻辑函数。 使用该函数可预测某个输入向量属于一个组或另一个组的概率。
食品检测数据的预测分析示例
在此示例中,我们使用 Spark 对食品检测数据 (Food_Inspections1.csv) 进行一些预测分析。 通过芝加哥市数据门户获取的数据。 此数据集包含有关在芝加哥执行的食品企业检测的信息。 包括每家企业的相关信息、发现的违规行为(若有)以及检测结果。 CSV 数据文件在与群集(位于 /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv)关联的存储帐户中可用。
在以下步骤中,将开发一个模型以查看如何通过食物检测或为何失败。
创建 Apache Spark MLlib 机器学习应用
使用 PySpark 内核创建 Jupyter Notebook。 有关说明,请参阅创建 Jupyter Notebook 文件。
导入此应用程序所需的类型。 将以下代码复制并粘贴到空白单元格中,然后按 SHIFT + ENTER。
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *由于使用的是 PySpark 内核,因此不需要显式创建任何上下文。 当你运行第一个代码单元时,系统会自动创建 Spark 和 Hive 上下文。
构造输入数据帧
使用 Spark 上下文将原始 CSV 数据作为非结构化文本拉取到内存。 然后使用 Python 的 CSV 库分析每一行数据。
运行以下命令行,通过导入并分析输入数据来创建弹性分布式数据集 (RDD)。
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)运行以下代码检索 RDD 中的一行,以便可以查看数据架构:
inspections.take(1)输出为:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]通过这些输出可以了解输入文件的架构。 它包括每个机构的名称和机构类型。 此外,还包括地址、检测数据和位置等。
运行以下代码创建数据帧 (df) 和临时表 (CountResults),其中包含一些可用于预测分析的列。
sqlContext用于对结构化数据进行转换。schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')数据帧中的四个相关列为“ID”、“name”、“results”和“violations” 。
运行以下代码获取数据小样本:
df.show(5)输出为:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
了解数据
让我们开始了解数据集包含的内容。
运行以下代码,显示 results 列中的非重复值:
df.select('results').distinct().show()输出为:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+运行以下代码来可视化这些结果的分布:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY results后接
-o countResultsdf的%%sqlmagic 可确保查询输出本地保存在 Jupyter 服务器上(通常在群集的头节点)。 输出将保存为具有指定名称 countResultsdf 的 Pandas数据帧。 有关%%sqlmagic 以及可在 PySpark 内核中使用的其他 magic 的详细信息,请参阅包含 Apache Spark HDInsight 群集的 Jupyter Notebook 上可用的内核。输出为:
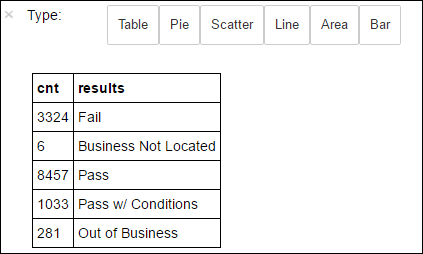
还可以使用 Matplotlib(用于构建数据可视化效果的库)创建绘图。 因为必须从本地保存的 countResultsdf 数据帧中创建绘图,所以代码片段必须以
%%localmagic 开头。 此操作可确保代码在 Jupyter 服务器上本地运行。%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')若要预测食物检测结果,需要基于违规行为开发一个模型。 由于逻辑回归是二元分类方法,因此有必要将结果数据分为两个类别:“失败”和“通过”:
通过
- 通过
- 有条件通过
失败
- 失败
弃用
- 未找到企业
- 停业
附带其他结果(“未找到企业”或“停业”)的数据没有作用,不过它们在结果中所占的比例很小。
运行以下代码,将现有数据帧 (
df) 转换为新的数据帧,其中每个检测以“违规行为标签对”表示。 在本例中,0.0标签表示失败,1.0标签表示成功,-1.0标签表示除了这两个结果以外的结果。def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')运行以下代码显示一行带有标签的数据:
labeledData.take(1)输出为:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
从输入数据帧创建逻辑回归模型
最终任务是转换带标签的数据。 将该数据转换为通过逻辑回归进行分析的格式。 逻辑回归算法的输入需要一组标签特征向量对。 其中的“特征向量”是表示输入点的数字向量。 因此,需要转换“违规行为”列(半结构化,包含许多自由文本格式的注释)。 将该列转换为可以通过机器轻松识别的实数数组。
处理自然语言的一种标准机器学习方法是为每个不同的单词分配一个索引。 然后向机器学习算法传递一个向量。 这样,每个索引的值都包含该单词在文本字符串中的相对频率。
MLlib 提供了执行此操作的一种简单方法。 首先,“标记”每个违规字符串以获取每个字符串中的各个单词。 然后使用 HashingTF 将每组标记转换为特征向量,随后可将其传递给逻辑回归算法以构建模型。 利用管道按序列执行上述所有步骤。
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
使用另一个数据集评估模型
可以使用先前创建的模型来预测新检测的结果。 预测基于所观察到的违规行为。 通过数据集 Food_Inspections1.csv 来训练此模型。 可以使用另一个数据集 Food_Inspections2.csv 来评估此模型对新数据的功能性。 第二个数据集 (Food_Inspections2.csv) 位于与群集关联的默认存储容器中。
运行以下代码创建新的数据帧 predictionsDf,其中包含由模型生成的预测。 该代码段还基于数据帧创建名为 Predictions 的临时表。
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columns应该看到输出类似于以下文本:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']查看其中的一个预测。 运行此代码段:
predictionsDf.take(1)将显示针对测试数据集中第一项的预测。
model.transform()方法对具有相同架构的任何新数据应用相同的转换,并得出如何对数据进行分类的预测。 可以进行一些统计以了解预测的具体情况:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")输出类似于以下文本:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rate将逻辑回归与 Spark 配合使用即可获得一个模型,了解违规行为说明(英语) 与给定企业是通过还是未通过食物检测之间的关系。
创建预测的可视化表示形式
现在可以构造一个最终可视化效果,以帮助推理此测试的结果。
首先,提取之前创建的“Predictions”临时表中的不同预测和结果。 以下查询将输出分为 true_positive、false_positive、true_negative 和 false_negative。 在以下查询中,使用
-q关闭可视化,同时使用-o将输出保存为随后可用于%%local幻数的数据帧。%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')最后,使用以下代码段通过 Matplotlib生成绘图。
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')应会看到以下输出:
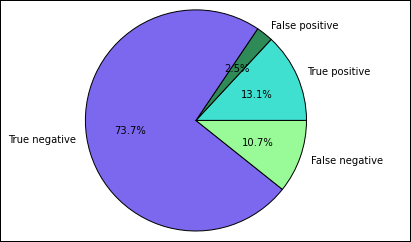
在该图中,“正”的结果指未通过食品检验,而“负”的结果指通过检验。
关闭笔记本
运行应用程序后,应该关闭笔记本以释放资源。 为此,请在 Notebook 的“文件”菜单中选择“关闭并停止” 。 此操作会关闭 Notebook。