你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于:![]() IoT Edge 1.5
IoT Edge 1.5
重要
IoT Edge 1.5 LTS 是受支持的版本。 IoT Edge 1.4 LTS 的生命周期结束日期为 2024 年 11 月 12 日。 如果你使用的是早期版本,请参阅更新 IoT Edge。
在本文中,你将了解实现可观测性维度的概念和技术: 测量和监视 和 故障排除。 你将了解以下主题:
- 定义要监视的服务性能指标
- 使用指标度量服务性能指标
- 使用 Azure Monitor 工作簿监视指标并检测问题
- 使用精心设计的工作簿排查基本问题
- 使用分布式跟踪和相关日志排查高级问题
- (可选)将示例方案部署到 Azure 以练习所学内容
场景
为了克服抽象的考虑,让我们使用一个将海洋表面温度从传感器收集到 Azure IoT 的现实方案。
拉尼尼亚
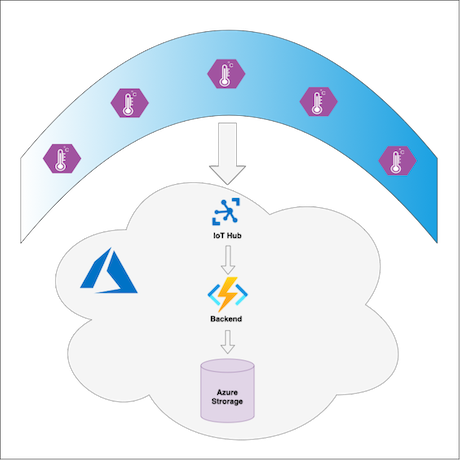
拉尼尼亚服务测量太平洋表面温度,以预测拉尼尼亚冬季。 海洋中的浮标具有 IoT Edge 设备,可将表面温度数据发送到 Azure 云。 每个 IoT Edge 设备上的自定义模块都会预处理遥测数据,然后再将其发送到云。 在云中,后端 Azure Functions 处理数据并将其保存到 Azure Blob 存储。 服务的客户端(如 ML 推理工作流、决策系统和不同的 UI)可以从 Azure Blob 存储获取具有温度数据的消息。
测量和监视
让我们构建一个测量和监视解决方案,使 La Niña 服务专注于其业务价值。
我们测量和监视的内容
要了解要监视的内容,必须先了解该服务的实际作用以及服务客户对系统有何期待。 在此方案中,常见的 La Niña 服务使用者的预期可能按以下因素进行分类:
- 覆盖率。 数据来自大多数已安装的浮标
- 时效性。 浮标传来的是最新相关数据
- 吞吐量。 浮标传递的温度数据不会出现重大延迟
- 正确性。 信息丢失(错误)的比例很小
满足以上因素意味着服务按客户预期工作。
下一步是定义用于测量上述因素值的设备。 此作业由以下服务级别指示器(SLI)完成:
| 服务级别指标 | 因素 |
|---|---|
| 联机设备与总设备的比率 | 覆盖范围 |
| 频繁进行报告的设备数与进行报告的设备数的比率 | 时效性、吞吐量 |
| 成功传递消息的设备数与总设备数的比率 | 正确性 |
| 快速传送消息的设备数与总设备数的比率 | 吞吐量 |
完成上述工作后,我们就可以针对每个指标应用滑动量表,并定义准确的阈值,以表示客户“满意”程度。 对于此应用场景,我们会选择下表中列出的具有正式服务级别目标 (SLO) 的样本阈值:
| 服务级别目标 | 因素 |
|---|---|
| 90% 的设备在观察间隔内报告指标的时间不超过 10 分钟(联机) | 覆盖范围 |
| 95% 的联机设备在观察间隔内每分钟发送 10 次温度数据 | 时效性、吞吐量 |
| 99% 的联机设备在观察间隔内成功传递消息,且错误率低于 5% | 正确性 |
| 95% 的联机设备在观察间隔的 50 毫秒内传递 90% 的消息 | 吞吐量 |
SLO 定义还必须描述测量指标值的方法:
- 观察间隔:24 小时。 过去 24 小时内,SLO 语句为 true。 这意味着,如果 SLI 出现故障并影响相应的 SLO,那么在 SLI 修复后,需要再等待 24 小时后才能评估该 SLO 是否恢复良好。
- 测量频率:5 分钟。 每隔 5 分钟进行一次测量以评估 SLI 值。
- 测量内容:IoT 设备与云之间的交互,温度数据的进一步使用不在测量范围之内。
测量方式
此刻,我们已经很清楚要测量的内容以及要使用什么阈值来确定服务是否按照预期运行。
借助“指标”来测量服务水平指标是一种常见做法(如我们定义的上述指标)。 我们通常认为此类可观测性数据的值相对较小。 它由各种系统组件生成,并在中心可观测性后端中收集,以便通过仪表板、工作簿和警报进行监视。
我们将阐明 La Niña 服务包含的组件:
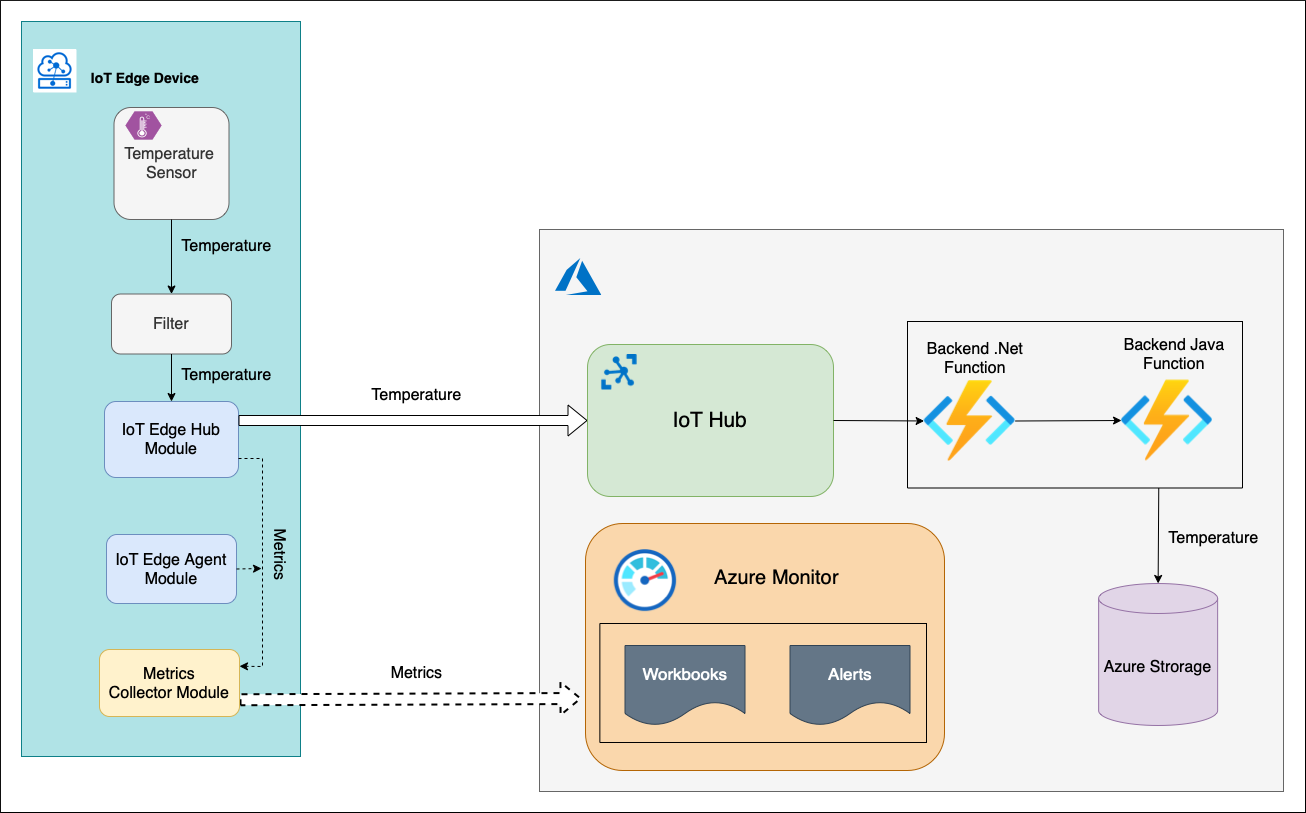
有一个具有自定义模块(C#)的 Temperature Sensor IoT Edge 设备,它生成一些温度值,并使用遥测消息将其发送到上游。 消息将会路由到另一个自定义模块 Filter (C#)。 模块会根据阈值窗口(0-100 摄氏度)检查接收到的温度数据。 如果温度在阈值范围内,FilterModule 会将遥测消息发送到云。
在云中,消息由后端处理。 后端由两个 Azure Functions 和存储帐户组成。 Azure .NET 函数从 IoT 中心事件终结点中选取遥测消息,对其进行处理,然后将其发送到 Azure Java 函数。 Java 函数将消息保存到存储帐户 Blob 容器。
IoT 中心设备附带系统模块 edgeHub 和 edgeAgent。 这些模块通过 Prometheus 终结点公开内置指标列表。 这些指标由 IoT Edge 设备上运行的指标收集器模块进行收集,然后推送到 Azure Monitor Log Analytics 服务。 除系统模块之外,Temperature Sensor 和 Filter 模块也可以使用一些特定于业务的指标进行检测。 但我们定义的服务级别指标只能使用内置指标进行测量。 因此,目前我们不需要实现任何其他内容。
在此场景中,我们有 10 个浮标。 其中一个浮标是故意设置为发生故障的,以便我们可以演示问题检测和后续故障排除。
监视方式
我们将使用 Azure Monitor 工作簿监视服务级别目标 (SLO) 和相应的服务级别指标 (SLI)。 部署此方案包括将 La Nina SLO/SLI 工作簿分配给 IoT 中心。
为了获得最佳用户体验,工作簿的设计遵循“概览”->“扫描”->“提交”概念>:
概览
在此层级,我们可概览总体情况。 对数据进行了粗略的聚合和展示:
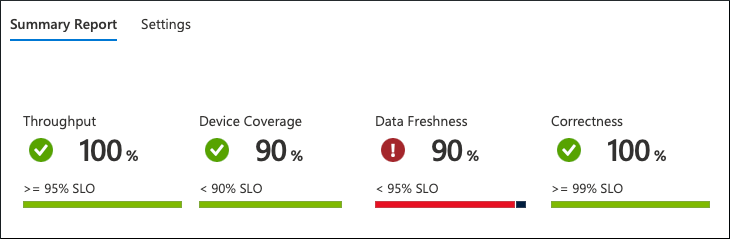
从我们所看到的情况来看,服务无法根据预期运行。 存在违反数据时效性 SLO 的情况。 只有 90% 的设备频繁发送数据,但服务客户期望达到 95%。
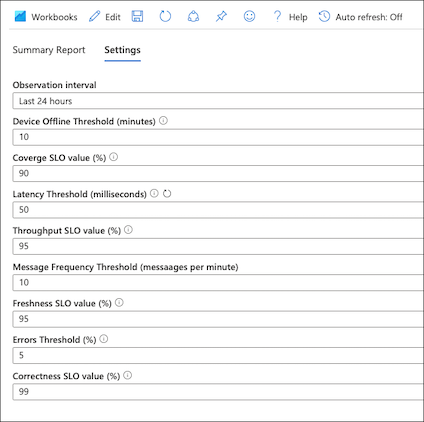
通过工作簿设置选项卡可配置所有 SLO 和阈值:
扫描
通过单击发生冲突的 SLO,我们可以进一步前往“扫描”层级,查看设备是如何聚合 SLI 值。
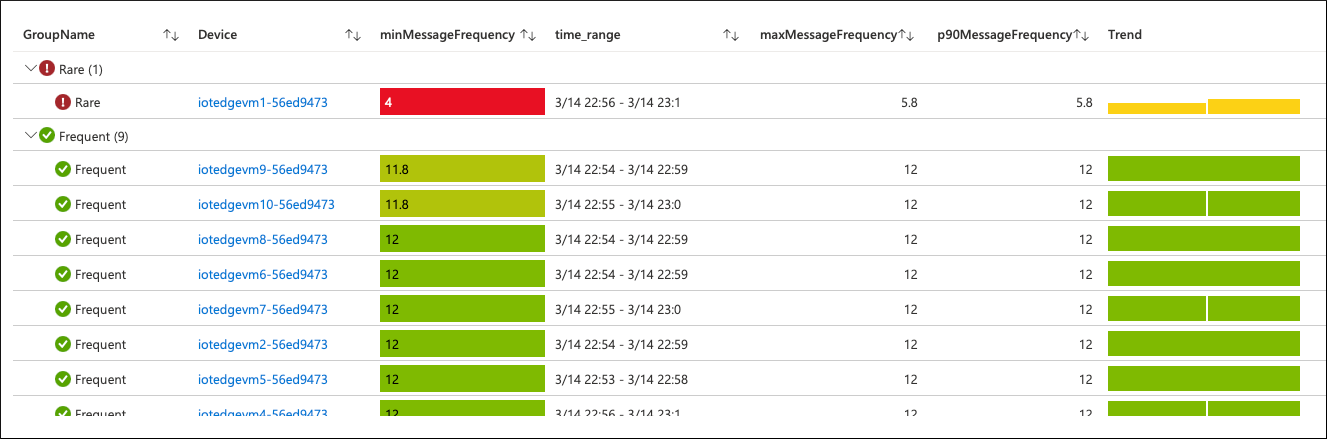
其中一个设备(共 10 个)“很少”发送遥测数据到云。 我们的 SLO 定义中指明了“频繁”是指每分钟至少发送 10 次。 此设备的发送频率远远低于该阈值。
提交
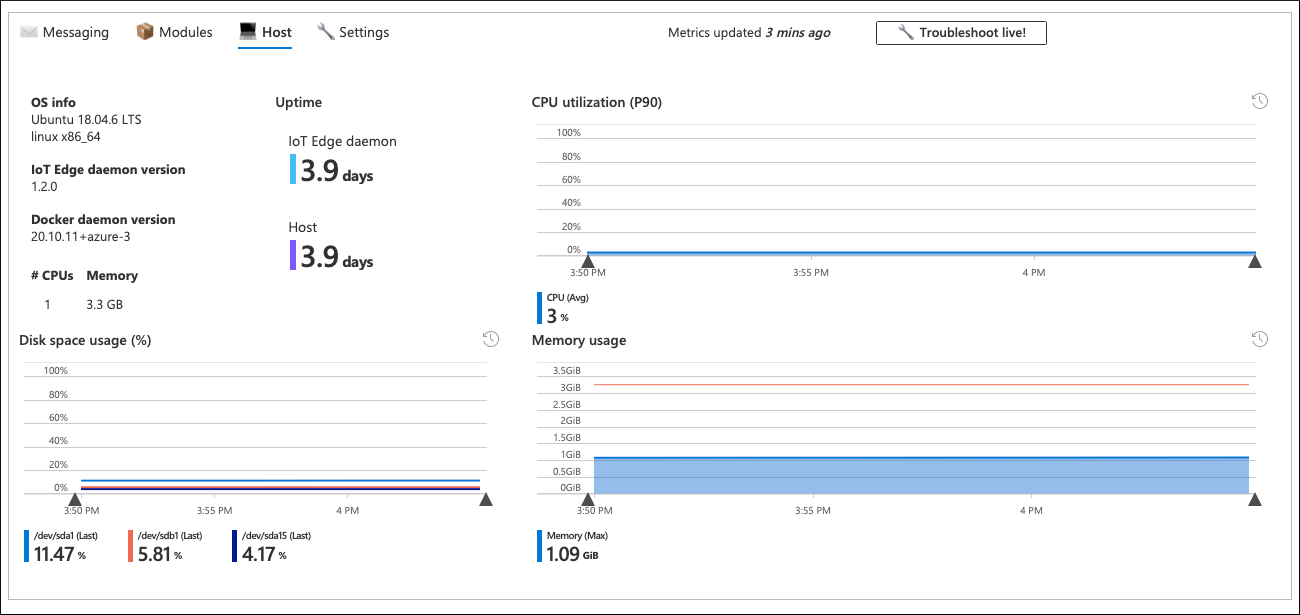
通过单击有问题的设备,可以进一步前往“提交”层级。 此层级是 IoT 中心监视产品/服务随附的一份现成“设备详细信息”精选工作簿。 La Nina SLO/SLI 工作簿对其进行重复使用,以提供特定设备性能的详细信息。
故障排除
通过测量和监视,我们可以观察和预测系统行为,将其与定义的预期行为进行比较,并最终检测现有或潜在的问题。 而通过故障排除,我们可以确定并找到问题的原因。
基本故障排除
“提交”级别的工作簿提供了有关设备运行状况的详细信息。 这包括模块和设备级别的资源消耗、消息延迟、频率、QLen 等。 在许多情况下,此信息可以帮助找到问题的根源。
在此方案中,故障设备的所有参数看起来正常,目前还不清楚设备发送消息的频率低于预期的原因。 设备级工作簿的消息选项卡也确认了这一点。
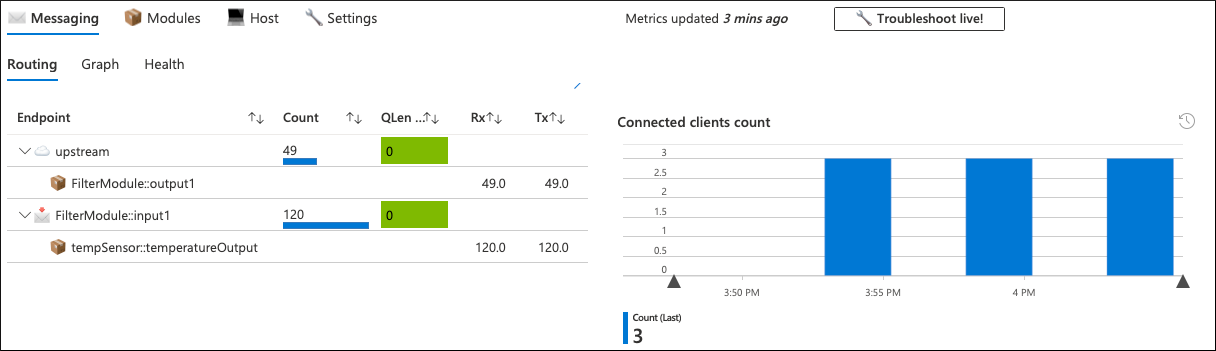
Temperature Sensor (tempSensor) 模块生成了 120 条遥测消息,但其中只有 49 条流向上游云。
首先,检查模块生成的 Filter 日志。 选择 “实时故障排除!”,然后选择该 Filter 模块。
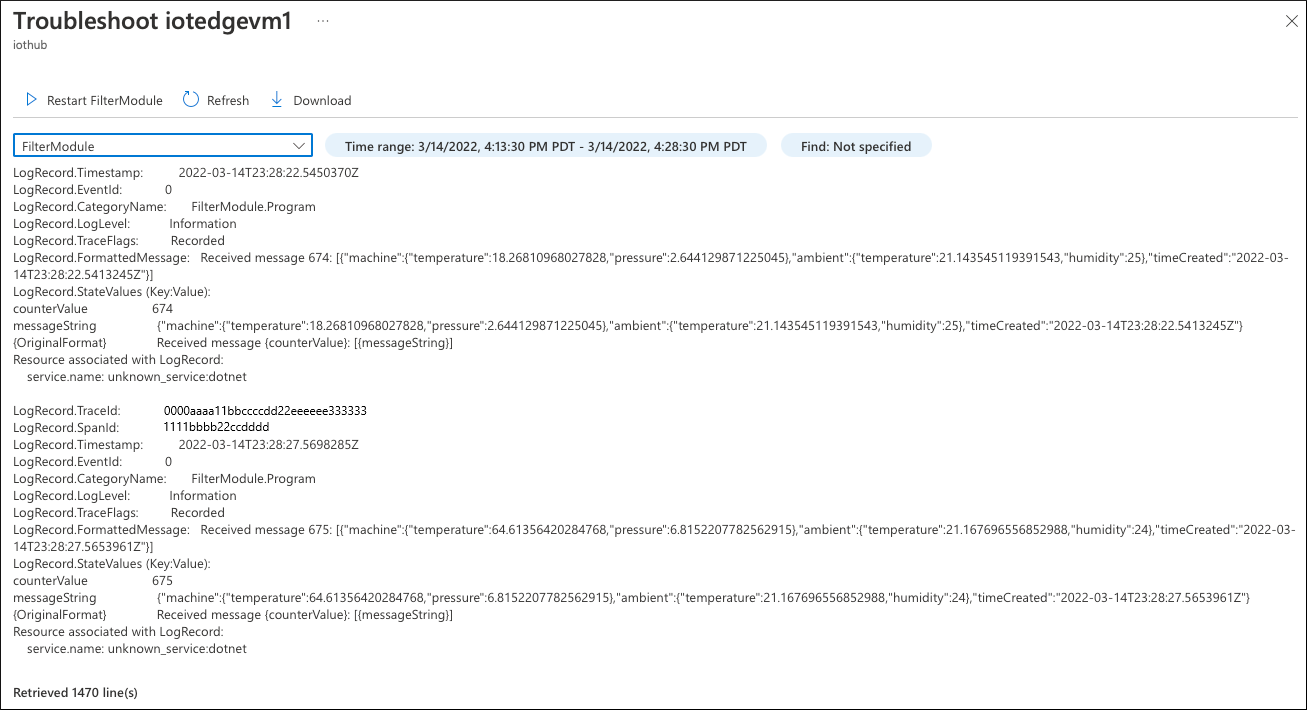
模块日志的分析不显示问题。 模块接收消息,并且没有错误。 从这里看,一切良好。
深度故障排除
两种可观测性仪器用于深入的故障排除目的: 跟踪 和 日志。 在此方案中,跟踪显示具有海洋表面温度的遥测消息如何从传感器传播到云中的存储、调用什么以及使用哪些参数。 日志显示在此过程中每个系统组件内发生的情况。 结合使用“跟踪”和“日志”可以实现更强大的功能。 通过此设置,可以在处理特定遥测消息时读取特定系统组件的日志,例如 IoT 设备上的模块或后端函数。
La Niña 服务使用 OpenTelemetry 在 Azure Monitor 中生成和收集跟踪和日志。
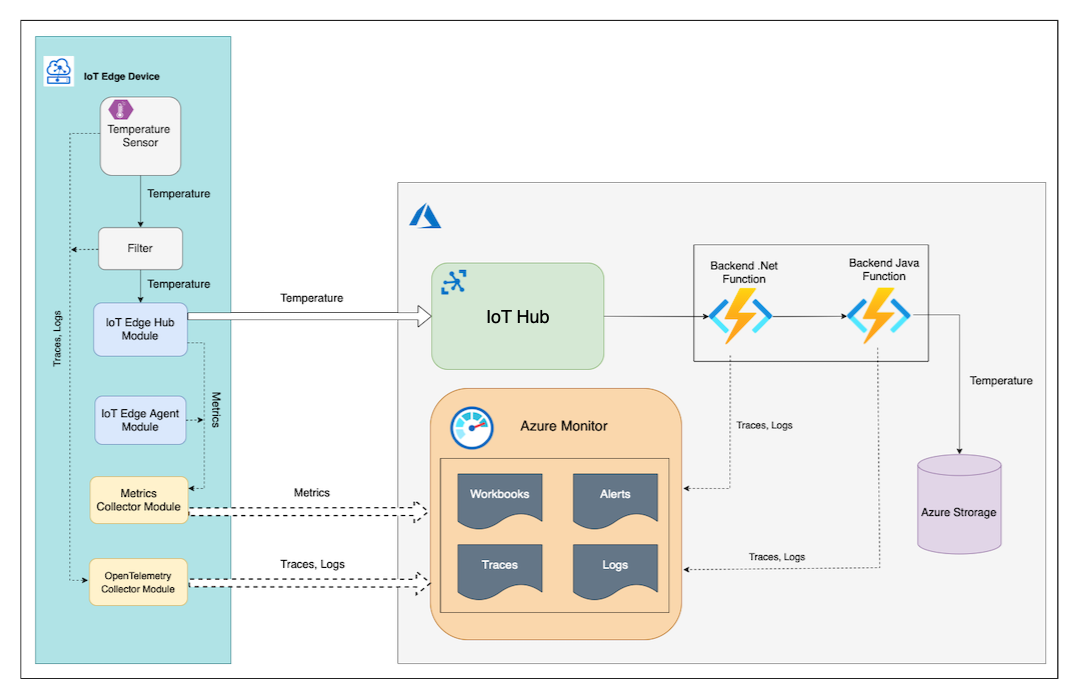
IoT Edge 模块 Temperature Sensor 和 Filter 使用 OTLP(OpenTelemetry 协议)将日志和跟踪数据导出到在同一边缘设备上运行的 OpenTelemetryCollector 模块。 然后,该模块会将 OpenTelemetryCollector 日志和跟踪导出到 Azure Monitor Application Insights。
Azure .NET 函数使用 Azure Monitor 开放遥测直接导出程序将跟踪数据发送到 Application Insights。 它还使用配置的 ILogger 实例将相关日志直接发送到 Application Insights。
Java 后端函数使用 OpenTelemetry 自动检测 Java 代理来生成跟踪数据和关联日志,并将其导出到 Application Insights 实例。
默认情况下,La Niña 服务的设备上的 IoT Edge 模块不会设置为生成任何跟踪数据, 日志记录级别 设置为 Information。 跟踪数据量由 基于比率的采样器控制。 为采样器设置了给定活动包含在跟踪中的概率。 默认情况下,概率为 0。 通过此设置,若无需详细的可观测性数据,设备不会向 Azure Monitor 发送过多信息。
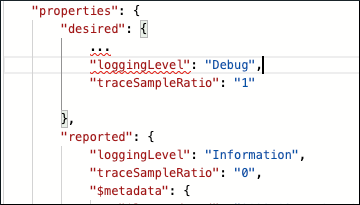
分析 Information 模块的 Filter 级别日志后,需要更深入地了解问题的原因。 更新 Temperature Sensor 和 Filter 模块孪生中的属性,将 loggingLevel 上升为 Debug 并将 traceSampleRatio 从 0 更改为 1:
进行这些更改后,重启 Temperature Sensor 和 Filter 模块:
几分钟后,跟踪和详细日志会从故障设备到达 Azure Monitor。 可以使用 Application Insights 中的 应用程序映射 监视从设备上的传感器到云存储的整个端到端消息流。
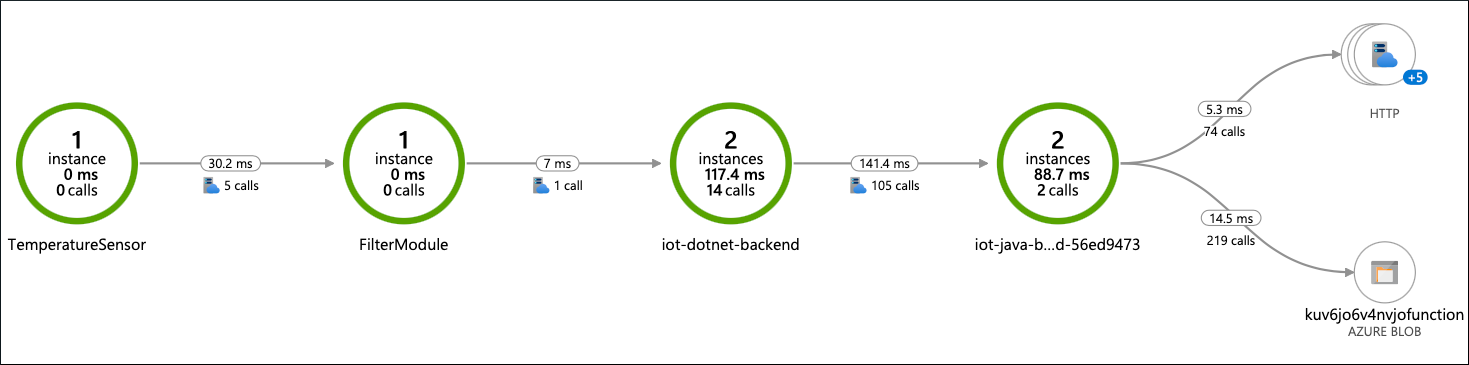
在此映射中,可以向下钻取到跟踪。 某些行迹看起来正常,包含流程的所有步骤,但有些较短,因此在 Filter 模块之后不会有任何后续动作。
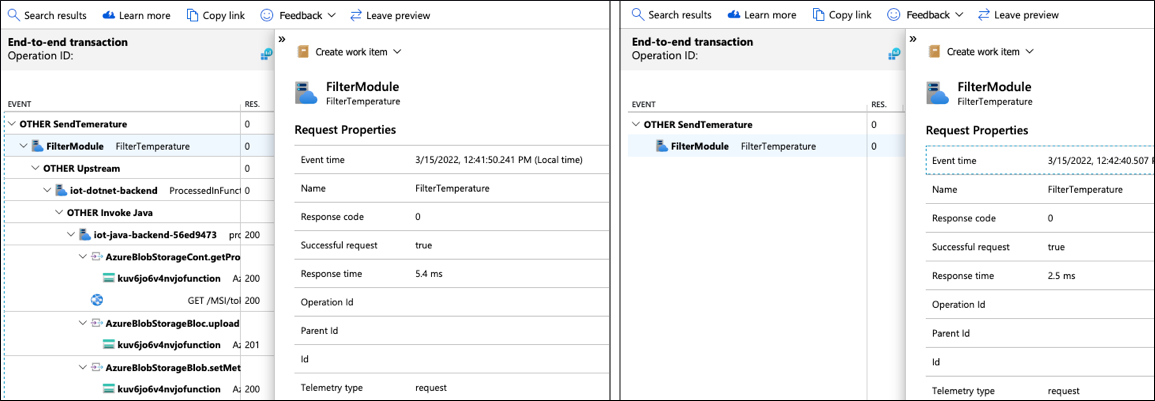
分析其中一条短跟踪,找出模块中 Filter 发生的情况,以及它为何未将消息上游发送到云。
由于日志与跟踪相关,因此可以通过指定TraceId和SpanId来查询日志,从而检索Filter模块此执行实例的日志。
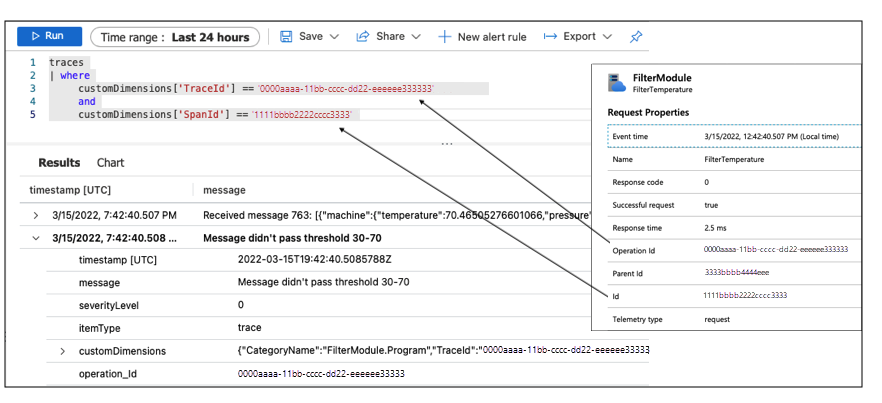
日志显示模块收到温度为 70.465 度的消息。 但在此设备上设置的筛选阈值为 30 到 70。 因此消息未通过阈值。 此设备设置不正确。 此配置是使用工作簿监视 La Niña 服务性能时检测到问题的原因。
通过更新模块孪生中的属性,修复此设备上的 Filter 模块配置。 此外,请将loggingLevel减至Information并将traceSampleRatio设置为0。

进行这些更改后,请重启模块。 几分钟后,设备会将新的指标值报告给 Azure Monitor。 工作簿图表反映以下更新:
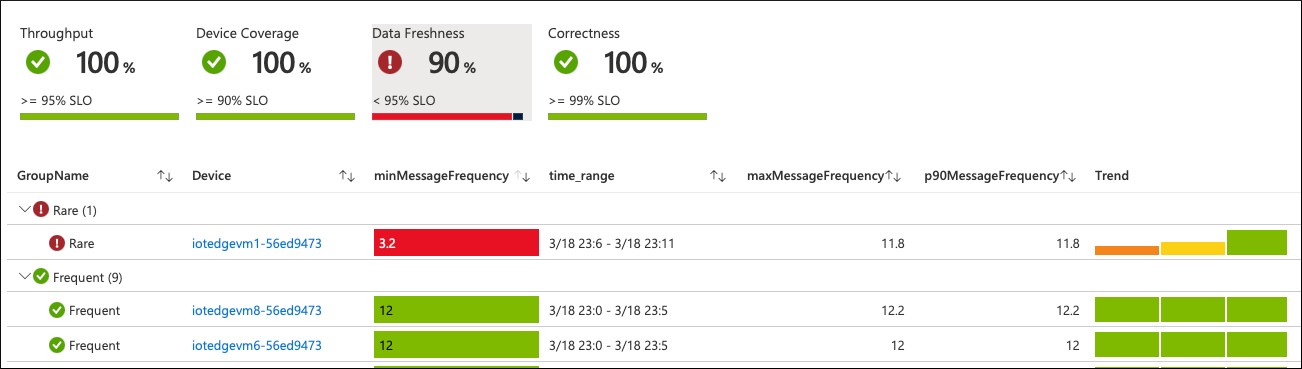
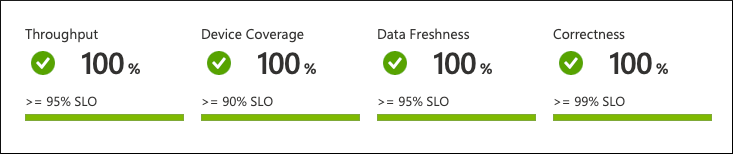
有问题的设备上的消息频率将恢复正常。 如果配置观察间隔期间没有任何其他情况发生,则整个 SLO 值将再次变为绿色:
尝试使用示例
此时,可以将方案示例部署到 Azure,以执行步骤并尝试自己的用例。
若要部署此解决方案,需要:
- PowerShell
- Azure CLI
- 具有活动订阅的 Azure 帐户。 免费创建一个。
克隆 IoT ELM 存储库。
git clone https://github.com/Azure-Samples/iotedge-logging-and-monitoring-solution.git打开 PowerShell 控制台并运行
deploy-e2e-tutorial.ps1脚本。./Scripts/deploy-e2e-tutorial.ps1
后续步骤
在本文中,你将设置一个解决方案,其中包含用于监视和故障排除的端到端可观测性功能。 这些 IoT 系统解决方案中的一个常见挑战是将可观测性数据从设备发送到云。 此方案中的设备应处于联机状态,并且与 Azure Monitor 建立稳定的连接,但情况并非总是如此。
转到后续文章,如 使用 IoT Edge 进行分布式跟踪 ,获取建议和技术来处理设备通常处于脱机状态或与云中可观测性后端的连接受限或受限的情况。