你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Windows Data Science Virtual Machine (DSVM) 是一个功能强大的数据科学开发环境,支持数据探索和建模任务。 该环境预置和捆绑了多款热门数据分析工具,便于针对本地、云或混合部署开始分析。
DSVM 与 Azure 服务紧密协同工作。 它可以读取并处理已存储在 Azure、Azure Synapse(以前称为 SQL DW)、Azure Data Lake、Azure 存储或 Azure Cosmos DB 中的数据。 它还可以利用其他分析工具,例如 Azure 机器学习。
本文介绍如何使用 DSVM 处理数据科学任务,以及如何与其他 Azure 服务交互。 这是 DSVM 可以完成的任务的示例:
- 使用 Jupyter Notebook 在浏览器中借助 Python 2、Python 3 和 Microsoft R 试验数据。(Microsoft R 是面向企业的高性能 R 版本。)
- 使用 Microsoft Machine Learning Server 和 Python 在 DSVM 上本地探索数据和开发模型。
- 使用 Azure 门户或 PowerShell 管理 Azure 资源。
- 通过将 Azure 文件存储共享作为可在 DSVM 上装载的驱动器,扩展存储空间并跨整个团队共享大型数据集/代码。
- 通过 GitHub 与团队共享代码。 使用预安装的 Git 客户端访问存储库:Git Bash 和 Git GUI。
- 访问 Azure 数据和分析服务:
- Azure Blob 存储
- Azure Cosmos DB(Azure 宇宙数据库)
- Azure Synapse(前身为 SQL DW)
- Azure SQL 数据库
- 使用 DSVM 上预安装的 Power BI Desktop 实例生成报表和仪表板,然后将它们部署到云中。
- 在虚拟机上安装更多工具。
注意
本文中列出的许多数据存储和分析服务将收取额外的使用费用。 有关详细信息,请访问 Azure 定价页面。
先决条件
注意
建议使用 Azure Az PowerShell 模块与 Azure 交互。 若要开始,请参阅安装 Azure PowerShell。 若要了解如何迁移到 Az PowerShell 模块,请参阅 将 Azure PowerShell 从 AzureRM 迁移到 Az。
使用 Jupyter Notebook
Jupyter Notebook 提供基于浏览器的 IDE,用于数据探索和建模。 可以在 Jupyter Notebook 中使用 Python 2、Python 3 或 R。
若要启动 Jupyter Notebook,请在“开始”菜单或桌面上选择“Jupyter Notebook”图标。 在 DSVM 命令提示符处,还可以从承载现有笔记本或要在其中创建新笔记本的目录中运行 jupyter notebook 命令。
启动 Jupyter 后,导航到 /notebooks 目录。 此目录承载着预打包到 DSVM 中的示例笔记本。 您可以:
- 单击笔记本以查看代码。
- 选择“Shift”“Enter”以运行每个单元格。+
- 选择“单元格”“运行”以运行整个笔记本。>
- 创建新笔记本,选择 Jupyter 图标(左上角),选择“新建”按钮,然后选择笔记本语言(也称为内核)。
注意
Jupyter 当前支持 Python 2.7、Python 3.6、R、Julia 和 PySpark 内核。 R 内核支持在开源 R 和 Microsoft R 中进行编程。在笔记本中,可以使用你任选的库浏览数据、生成模型并测试该模型。
使用 Microsoft Machine Learning Server 探索数据和开发模型
注意
对 Machine Learning Server 独立版的支持已于 2021 年 7 月 1 日结束。 我们在 2021 年 6 月 30 日之后从 DSVM 映像中移除了它。 现有部署仍可访问该软件,但支持在 2021 年 7 月 1 日之后结束。
可以直接在 DSVM 上使用 R 和 Python 进行数据分析。
对于 R,可使用针对 Visual Studio 的 R 工具。 除了开源 CRAN R 资源之外,Microsoft 还提供其他库。 这些库既支持可缩放的分析,又能够分析超出并行分块分析的内存大小限制的数据量。
对于 Python,可以使用已预安装针对 Visual Studio 的 Python 工具 (PTVS) 扩展的 IDE,例如 Visual Studio Community Edition。 默认情况下,PTVS 上仅配置了根 Conda 环境 Python 3.6。 若要启用 Anaconda Python 2.7,请执行以下操作:
- 为每个版本创建自定义环境。 选择“工具”“Python 工具”>“Python 环境”,然后在 Visual Studio Community Edition 中选择“+ 自定义”。>
- 提供描述并将环境前缀路径设置为 c:\anaconda\envs\python2(适用于 Anaconda Python 2.7)。
- 选择“自动检测”“应用”以保存环境。
有关如何创建 Python 环境的详细信息,请访问 PTVS 文档资源。
现在可以创建新的 Python 项目。 选择“文件”“新建”>“项目”“Python”,然后选择要生成的 Python 应用程序的类型。>> 可以将当前项目的 Python 环境设置为所需版本(Python 2.7 或 3.6),方法是右键单击“Python 环境”,然后选择“添加/删除 Python 环境”。 要详细了解如何使用 PTVS,请参阅产品文档。
管理 Azure 资源
DSVM 让你可以在虚拟机上本地生成分析解决方案。 它还允许访问 Azure 云平台上的服务。 Azure 提供多种服务,包括计算、存储、数据分析等,可以通过 DSVM 管理并访问这些服务。
可选用两种方法管理 Azure 订阅和云资源:
在浏览器中访问 Azure 门户。
使用 PowerShell 脚本。 从桌面快捷方式或“开始”菜单运行 Azure PowerShell。 有关详细信息,请访问 Microsoft Azure PowerShell 文档资源。
使用共享文件系统扩展存储
数据科学家可以在团队内共享大型数据集、代码或其他资源。 DSVM 约有 45 GB 的可用空间。 要扩展存储,可以使用 Azure 文件存储,将它装载到一个或多个 DSVM 实例或通过 REST API 访问它。 还可以使用 Azure 门户或 Azure PowerShell 添加额外的专用数据磁盘。
注意
Azure 文件存储共享的最大空间为 5 TB。 每个文件的大小上限为 1 TB。
此 Azure PowerShell 脚本会创建 Azure 文件存储共享:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
可以在 Azure 中的任何虚拟机中装载 Azure 文件存储共享。 建议将 VM 和存储帐户放置在同一个 Azure 数据中心,以避免延迟和数据传输费用。 这些 Azure PowerShell 命令会在 DSVM 上装载驱动器:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
可以像访问 VM 上的任何正常驱动器一样访问此驱动器。
在 GitHub 中共享代码
GitHub 代码存储库托管了开发人员社区共享的许多工具的代码示例和代码源。 它使用 Git 作为跟踪和存储代码文件版本的技术。 GitHub 还充当着用于创建你自己的存储库的平台。 你自己的存储库可以存储团队的共享代码和文档,实现版本控制,并控制想要查看和贡献代码的利益干系人的访问权限。 GitHub 支持团队中的协作、社区开发的代码的使用以及代码对社区的贡献。 有关 Git 的详细信息,请访问 GitHub 帮助页。
DSVM 包含用于访问 GitHub 存储库的客户端工具,可通过命令行和 GUI 使用。 Git Bash 命令行工具通过 Git 和 GitHub 工作。 DSVM 上安装了 Visual Studio 且有 Git 扩展。 “开始”菜单和桌面都有这些工具的图标。
使用 git clone 命令从 GitHub 存储库下载代码。 例如,要将 Microsoft 发布的数据科学存储库下载到当前目录,请在 Git Bash 中运行以下命令:
git clone https://github.com/Azure/DataScienceVM.git
Visual Studio 可以处理相同的克隆操作。 此屏幕截图演示了如何在 Visual Studio 中访问 Git 和 GitHub 工具:

可以使用 GitHub 存储库中可用的 github.com 资源。 有关详细信息,请访问 GitHub 速查表资源。
访问 Azure 数据和分析服务
Azure Blob 存储
Azure Blob 存储是一项可靠的经济型云存储服务,适用于大型和小型数据资源。 本部分介绍如何将数据移动到 Blob 存储以及如何访问 Azure Blob 中存储的数据。
先决条件
在 Azure 门户中创建的 Azure Blob 存储帐户。
使用此命令确认命令行 AzCopy 工具已预安装:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exe承载 azcopy.exe 的目录已在 PATH 环境变量中,因此运行此工具时不用键入完整命令路径。 有关 AzCopy 工具的详细信息,请阅读 AzCopy 文档。
启动 Azure 存储资源管理器工具。 可从存储资源管理器网页下载它。


将数据从 VM 移动到 Azure blob:AzCopy
若要在本地文件和 Blob 存储之间移动数据,可以在命令行或 PowerShell 中使用 AzCopy:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- 将 C:\myfolder 替换为承载你的文件的目录路径
- 将 mystorageaccount 替换为你的 Blob 存储帐户名称
- 将 mycontainer 替换为容器名称
- 将“存储帐户密钥”替换为你的 Blob 存储访问密钥
可以在 Azure 门户中找到存储帐户凭据。
在 PowerShell 中或从命令提示符下运行 AzCopy 命令。 下面是 AzCopy 命令示例:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
运行 AzCopy 命令以将文件复制到 Azure blob 后,文件会显示在 Azure 存储资源管理器中。

将数据从 VM 移动到 Azure blob:Azure 存储资源管理器
还可以在 VM 中使用 Azure 存储资源管理器上传本地文件中的数据:
要将数据上传到容器,请选择目标容器,然后选择“上传”按钮。
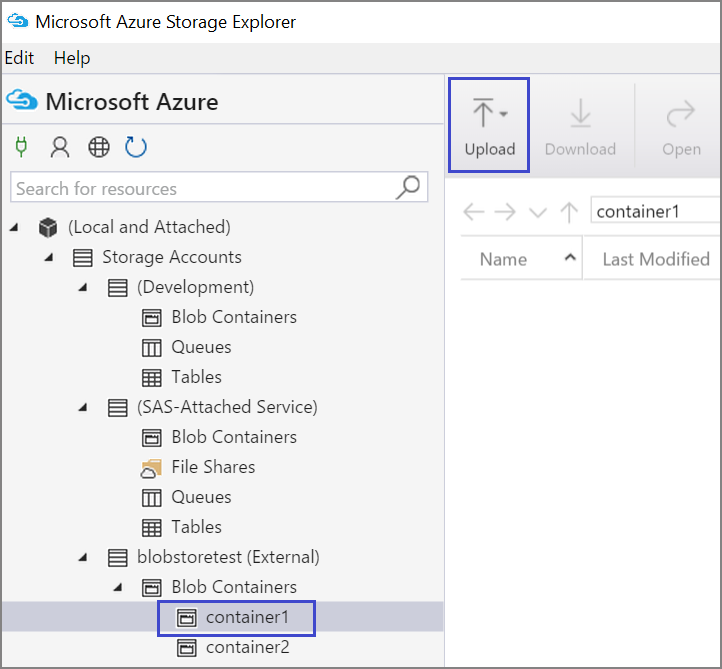
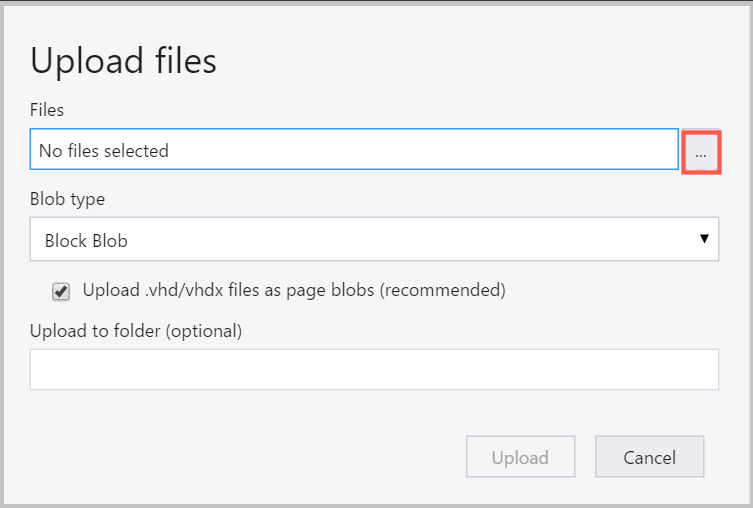
在“文件”框右侧,选择省略号 (...),选择要从文件系统上传的一个或多个文件,然后选择“上传”以开始上传文件。


读取 Azure blob 中的数据:Python ODBC
BlobService 库可以直接读取位于 Jupyter Notebook 或 Python 程序中的 blob 内的数据。 首先,导入所需的包:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
插入你的 Blob 存储帐户凭据,然后读取 blob 中的数据:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
以数据帧的形式读取数据:

Azure Synapse Analytics 和数据库
Azure Synapse Analytics 是一项弹性数据“仓库即服务”,具有企业级 SQL Server 体验。 此资源介绍如何预配 Azure Synapse Analytics。 预配了 Azure Synapse Analytics 后,此演练介绍了如何使用 Azure Synapse Analytics 中的数据处理数据上传、探索和建模。
Azure Cosmos DB(Azure 宇宙数据库)
Azure Cosmos DB 是基于云的 NoSQL 数据库。 例如,它可以处理 JSON 文档,并且可以存储和查询文档。 以下示例步骤演示了如何从 DSVM 访问 Azure Cosmos DB:
DSVM 上已安装 Azure Cosmos DB Python SDK。 若要更新它,请在命令提示符下运行
pip install pydocumentdb --upgrade。从 Azure 门户创建 Azure Cosmos DB 帐户和数据库。
从 Microsoft 下载中心下载 Azure Cosmos DB 数据迁移工具,并将其提取到你选择的目录。
在迁移工具中使用以下命令参数,将存储在 公共 blob 中的 JSON 数据(Volcano 数据)导入 Azure Cosmos DB。 (使用安装了 Azure Cosmos DB 数据迁移工具的目录中的 dtui.exe。)通过以下参数输入源和目标位置:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
导入数据后,可转到 Jupyter 并打开名为“DocumentDBSample”的笔记本。 它包含用于访问 Azure Cosmos DB 和处理某些基本查询所需的 Python 代码。 有关 Azure Cosmos DB 的详细信息,请访问 Azure Cosmos DB 服务文档页。
使用 Power BI 报告和仪表板
可在 Power BI Desktop 中对上一个 Azure Cosmos DB 示例中介绍的 Volcano JSON 文件进行可视化,以获得有关该数据本身的直观见解。 这篇 Power BI 文章提供了详细步骤。 这些步骤大致如下:
- 打开 Power BI Desktop 并选择“获取数据”。 指定此 URL:
https://cahandson.blob.core.windows.net/samples/volcano.json。 - 作为列表导入的 JSON 记录应变为可见。 将此列表转换为表,使 Power BI 可以处理它。
- 选择展开(箭头)图标以展开列。
- 位置为“记录”字段。 展开记录并仅选择坐标。 坐标是列表中的一列。
- 添加新列,将列表的坐标列转换为逗号分隔的 LatLong 列。 使用公式
Text.From([coordinates]{1})&","&Text.From([coordinates]{0})连接坐标列表字段中的两个元素。 - 将“海拔”列转换为十进制,并选择“关闭”和“应用”按钮。
可以使用以下代码作为上述步骤的替代方法。 它将 Power BI 中“高级编辑器”中的步骤编写为脚本,以查询语言编写数据转换:
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
现在,Power BI 数据模型中有数据。 你的 Power BI Desktop 实例应如下所示:

可以使用数据模型开始生成报表和可视化效果。 这篇 Power BI 文章介绍了如何生成报表。
动态缩放 DSVM
可以纵向扩展和缩减 DSVM 以满足项目的需求。 如果晚上或周末不需要使用 VM ,可从 Azure 门户关闭 VM。
注意
如果只使用 VM 操作系统中的关机按钮,则会产生计算费用。 应改为使用 Azure 门户或 Cloud Shell 来解除分配 DSVM。
对于大规模分析项目,可能需要更多 CPU、内存或磁盘容量。 如果是这样,你可以找到不同数量的 CPU 核心、内存容量、磁盘类型(包括固态驱动器)和基于 GPU 的实例的 VM,以满足计算和预算需求。 Azure 虚拟机定价页展示了 VM 及其每小时计算定价的完整列表。
添加更多工具
DSVM 提供预生成工具,可满足许多常见的数据分析需求。 它们节省时间,因为无需单独安装和配置环境。 它们还能节约成本,因为你只需为使用的资源付费。
可以使用本文中介绍的其他 Azure 数据和分析服务改进你的分析环境。 在某些情况下,你可能需要其他工具,包括特定的专有合作伙伴工具。 你拥有虚拟机上的完全管理访问权限,可安装必要的工具。 还可以在 Python 和 R 中安装其他未预安装的包。 对于 Python,可以使用 conda 或 pip。 对于 R,可以在 R 控制台中使用 install.packages()或使用 IDE 并选择“包”“安装包”。
深度学习
除基于框架的示例外,还可获取在 DSVM 上经过验证的一组内容全面的演练。 这些演练可帮助你快速开始开发图像和文本/语言分析领域的深度学习应用程序。
在不同的框架中运行神经网络:本演练展示如何在框架之间迁移代码。 它还演示了如何跨框架比较模型和运行时性能。
构建端到端解决方案以检测图像中的产品的操作指南:图像检测是一种在图像中查找对象并对其进行分类的技术。 这项技术有望在许多现实商业领域带来巨大回报。 例如,零售商可以使用此技术确定客户从货架上选取了哪个产品。 此信息可帮助零售店管理产品库存。
音频深度学习:此教程展示如何使用城市声音数据集训练用于音频事件检测的深度学习模型。 它还提供有关如何处理音频数据的概述。
文本文档分类:本演练展示如何生成和训练两种神经网络架构:分层注意网络和长短期记忆 (LSTM) 网络。 这些神经网络使用 Keras API 进行深度学习,从而对文本文档进行分类。
总结
本文仅介绍了可在 Microsoft Data Science Virtual Machine 上执行的部分操作。 你还可以执行很多其他操作,使 DSVM 成为有效的分析环境。