你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
可以使用 MLflow 查询 Azure 机器学习中的试验和作业(或运行)。 无需安装任何特定的 SDK 即可管理训练作业内部发生的情况,通过删除特定于云的依赖项,在本地运行和云之间创建更无缝的过渡。 本文将介绍如何使用 Azure 机器学习和采用 Python 语言的 MLflow SDK 在工作区中查询和比较试验与运行。
使用 MLflow 可以:
- 在工作区中创建、查询、删除和搜索试验。
- 在工作区中查询、删除和搜索运行。
- 跟踪和检索运行中的指标、参数、项目和模型。
有关在连接到 Azure 机器学习时 MLflow 开源和 MLflow 之间的详细比较,请参阅在 Azure 机器学习中查询运行和试验的支持矩阵。
注意
Azure 机器学习 Python SDK v2 不提供本机日志记录或跟踪功能。 这不仅适用于日志记录,也适用于查询记录的指标。 相反,请使用 MLflow 来管理试验和运行。 本文介绍如何使用 MLflow 来管理 Azure 机器学习中的试验和运行。
还可以使用 MLflow REST API 查询和搜索试验与运行。 请参阅将 MLflow REST 与 Azure 机器学习配合使用,获取使用示例。
先决条件
如下所示,安装 MLflow SDK
mlflow包和适用于 MLflow 的 Azure 机器学习azureml-mlflow插件。pip install mlflow azureml-mlflow提示
可以使用
mlflow-skinny包,它是一个不带 SQL 存储、服务器、UI 或数据科学依赖项的轻型 MLflow 包。 对于主要需要 MLflow 的跟踪和记录功能但不需要导入整个功能套件(包括部署)的用户,建议使用此包。创建 Azure 机器学习工作区。 若要创建工作区,请参阅创建入门所需的资源。 查看在工作区中执行 MLflow 操作所需的访问权限。
若要执行远程跟踪,或者跟踪在 Azure 机器学习外部运行的试验,请将 MLflow 配置为指向 Azure 机器学习工作区的跟踪 URI。 有关如何将 MLflow 连接到工作区的详细信息,请参阅为 Azure 机器学习配置 MLflow。
查询和搜索试验
使用 MLflow 在工作区内搜索试验。 请看以下示例:
获取所有活动的试验:
mlflow.search_experiments()注意
在旧版本的 MLflow (<2.0) 中,请改用
mlflow.list_experiments()方法。获取所有试验,包括存档的:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)按名称获取特定试验:
mlflow.get_experiment_by_name(experiment_name)按 ID 获取特定试验:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
搜索试验
自 Mlflow 2.0 起提供的 search_experiments() 方法允许使用 filter_string 来搜索与条件匹配的试验。
根据 ID 检索多个试验:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )检索在给定时间后创建的所有试验:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")检索具有给定标记的所有试验:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
查询和搜索运行
MLflow 允许搜索任何试验中的运行,包括同时进行的多个试验。 方法 mlflow.search_runs() 接受参数 experiment_ids 和 experiment_name 以指示要搜索的试验。 如果你想要搜索工作区中的所有试验,也可以指示 search_all_experiments=True:
按试验名称:
mlflow.search_runs(experiment_names=[ "my_experiment" ])按试验 ID:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])搜索工作区中的所有试验:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
请注意,experiment_ids 支持提供试验数组,因此你可以根据需要搜索多个试验中的运行。 如果你想要比较记录在不同试验中(例如,按不同的人员、不同的项目迭代)的同一模型的运行,此方法可能会很有用。
重要
如果未指定 experiment_ids、experiment_names 或 search_all_experiments,则 MLflow 默认在当前活动试验中搜索。 可以使用 mlflow.set_experiment() 设置活动试验。
默认情况下,MLflow 以 Pandas Dataframe 格式返回数据,在进一步处理运行分析时,这种格式非常方便。 返回的数据包括具有以下内容的列:
- 有关运行的基本信息。
- 列名称为
params.<parameter-name>的参数。 - 列名称为
metrics.<metric-name>的指标(每个指标的上次记录值)。
查询运行时也会返回所有指标和参数。 但是,对于包含多个值的指标(例如损失曲线或 PR 曲线),只会返回最后一个指标值。 如果你想要检索给定指标的所有值,请使用 mlflow.get_metric_history 方法。 如需示例,请参阅从运行中获取参数和指标。
将运行排序
默认情况下,试验按 start_time(试验在 Azure 机器学习中排队的时间)降序排序。 但是,可以使用参数 order_by 更改此默认设置。
按属性对运行排序,如
start_time:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])对运行进行排序并限制结果。 以下示例返回试验中的最后一次运行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])按特性
duration为运行排序:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])提示
attributes.duration在 MLflow OSS 中不存在,但为方便起见,Azure 机器学习中提供了它。按指标值为运行排序:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)警告
目前不支持对参数
order_by中包含metrics.*、params.*或tags.*的表达式使用order_by。 请在 Pandas 中改用sort_values方法,如示例中所示。
筛选运行
还可以使用参数 filter_string 通过超参数的特定组合查找运行。 使用 params 访问运行的参数、使用 metrics 访问在运行中记录的指标,使用 attributes 访问运行详细信息。 MLflow 支持由 AND 关键字联接的表达式(该语法不支持 OR):
基于参数值搜索运行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")警告
仅运算符
=、like、!=支持筛选parameters。基于指标值搜索运行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")搜索具有给定标记的运行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")搜索由给定用户创建的运行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")搜索失败的运行。 要查看可能的值,请参阅按状态筛选运行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")搜索在给定时间后创建的运行:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")提示
对于键
attributes,值应始终为字符串,所以应在引号之间编码。搜索花费了一小时以上的运行:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")提示
attributes.duration在 MLflow OSS 中不存在,但为方便起见,Azure 机器学习中提供了它。搜索在给定集中具有 ID 的运行:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
按状态筛选运行
按状态筛选运行时,MLflow 会使用不同于 Azure 机器学习的约定来命名运行的不同的可能状态。 下表列出了可能的值:
| Azure 机器学习作业状态 | MLFlow 的 attributes.status |
含义 |
|---|---|---|
| 未开始 | Scheduled |
作业/运行由 Azure 机器学习收到。 |
| 队列 | Scheduled |
作业/运行已计划运行,但尚未开始。 |
| 备餐中 | Scheduled |
作业/运行尚未启动,但已为其执行分配了计算,并且正在准备环境及其输入。 |
| 正在运行 | Running |
作业/运行当前正在执行。 |
| 已完成 | Finished |
作业/运行已完成且未出错。 |
| 已失败 | Failed |
作业/运行已完成但出错。 |
| 已取消 | Killed |
作业/运行已被用户取消或被系统终止。 |
示例:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
获取指标、参数、项目和模型
默认情况下,search_runs 方法返回包含有限数量信息的 Pandas Dataframe。 如果需要,可以获取 Python 对象,这可能有助于获取有关它们的详细信息。 使用 output_format 参数控制输出的返回方式:
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
然后可以从 info 成员访问详细信息。 以下示例演示如何获取 run_id:
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
获取运行中的参数和指标
使用 output_format="list" 返回运行后,可以使用键 data 轻松访问参数:
last_run.data.params
可以采用同样的方式查询指标:
last_run.data.metrics
对于包含多个值的指标(例如损失曲线或 PR 曲线),只会返回上次记录的指标值。 如果你想要检索给定指标的所有值,请使用 mlflow.get_metric_history 方法。 此方法要求使用 MlflowClient:
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
获取运行中的项目
MLflow 可以查询某个运行所记录的任何项目。 无法使用运行对象本身访问项目,应改用 MLflow 客户端:
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
上述方法会列出运行中记录的所有项目,但这些项目仍然存储在项目存储(Azure 机器学习存储)中。 若要下载其中任何一个项目,请使用方法 download_artifact:
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
注意
在旧版本的 MLflow (<2.0) 中,请改用 MlflowClient.download_artifacts() 方法。
获取运行中的模型
模型也可以记录在运行中,然后直接从运行中检索。 若要检索模型,需要知道其存储所在的项目的路径。 可以使用方法 list_artifacts 查找表示模型的项目,因为 MLflow 模型始终是文件夹。 可以使用 download_artifact 方法并指定模型的存储路径来下载模型:
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
然后,可以使用特定风格命名空间中的典型函数 load_model 从下载的项目中加载模型。 下面的示例使用 xgboost:
model = mlflow.xgboost.load_model(model_local_path)
MLflow 还允许通过一条指令中同时执行这两项操作:下载和加载模型。 MLflow 将模型下载到临时文件夹,并从中加载它。 方法 load_model 使用 URI 格式来指示必须从何处检索模型。 加载运行中的模型时,URI 结构如下:
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
提示
若要查询和加载在模型注册表中注册的模型,请参阅使用 MLflow 管理 Azure 机器学习中的模型注册表。
获取子(嵌套)运行
MLflow 支持子(嵌套)运行的概念。 如果你需要衍生训练例程,而这些例程必须独立于主训练进程进行跟踪,则这些运行非常有用。 超参数优化优化过程或 Azure 机器学习管道是生成多个子运行的作业的典型示例。 可以使用属性标记 mlflow.parentRunId(包含父运行的运行 ID)查询特定运行的所有子运行。
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
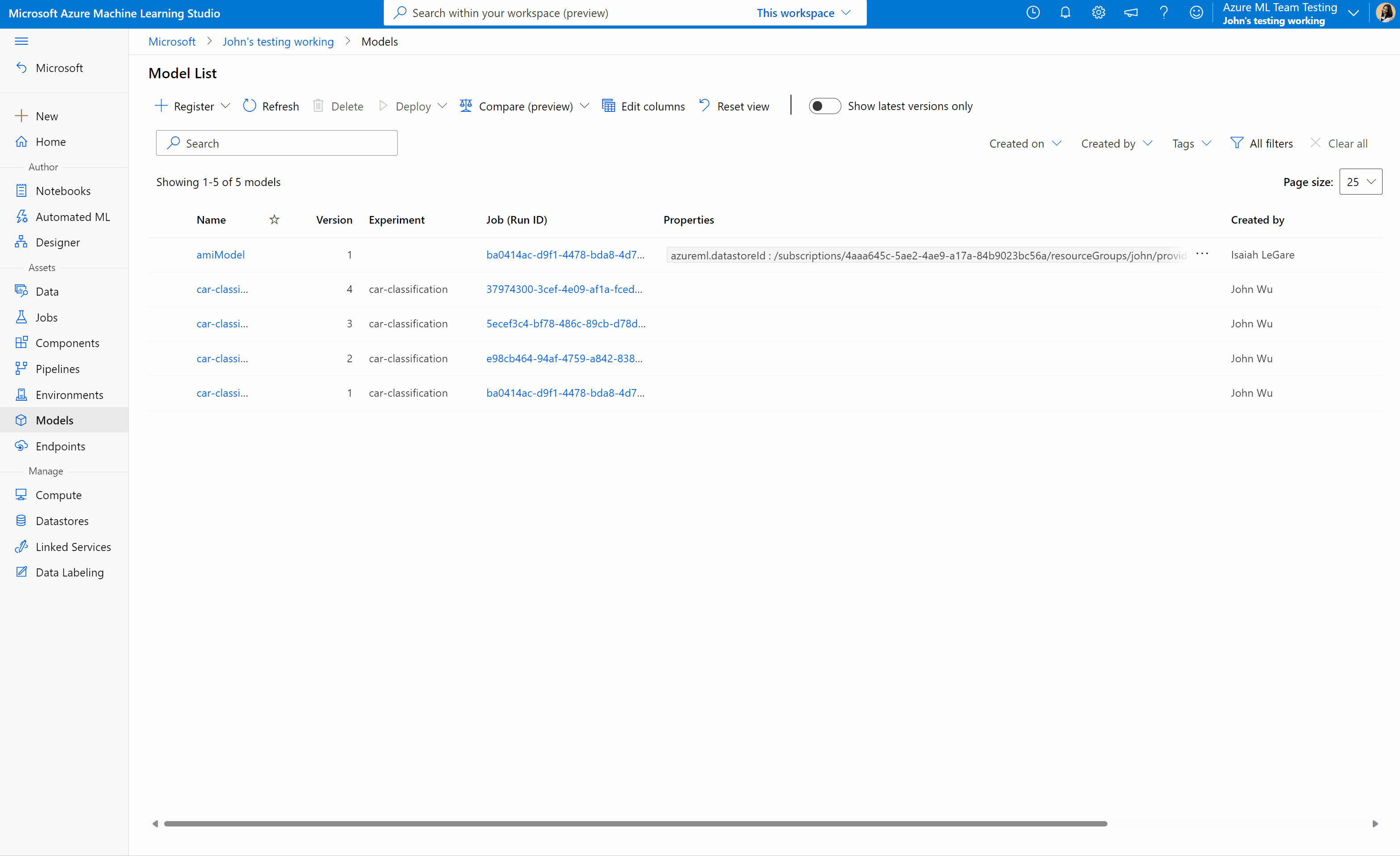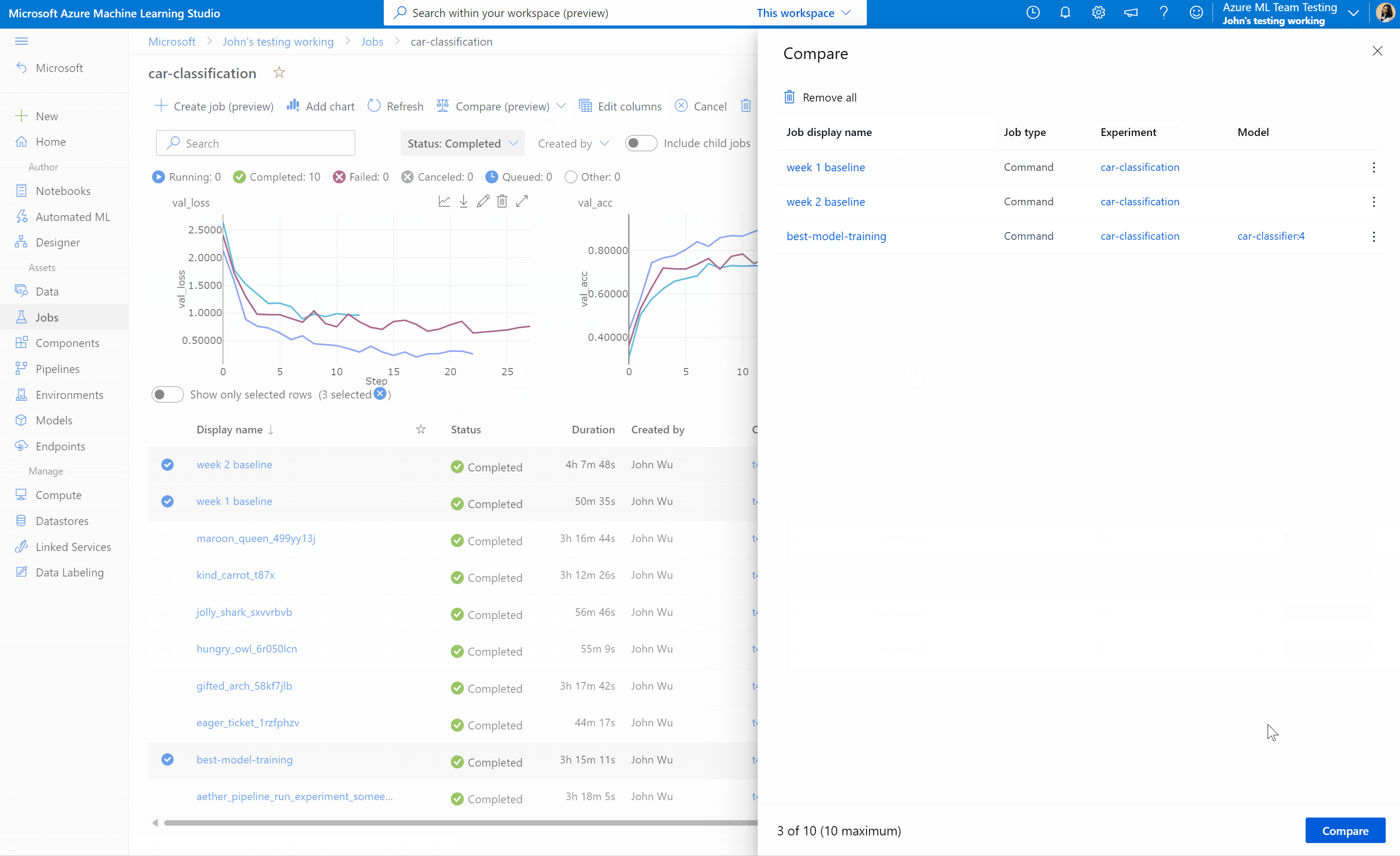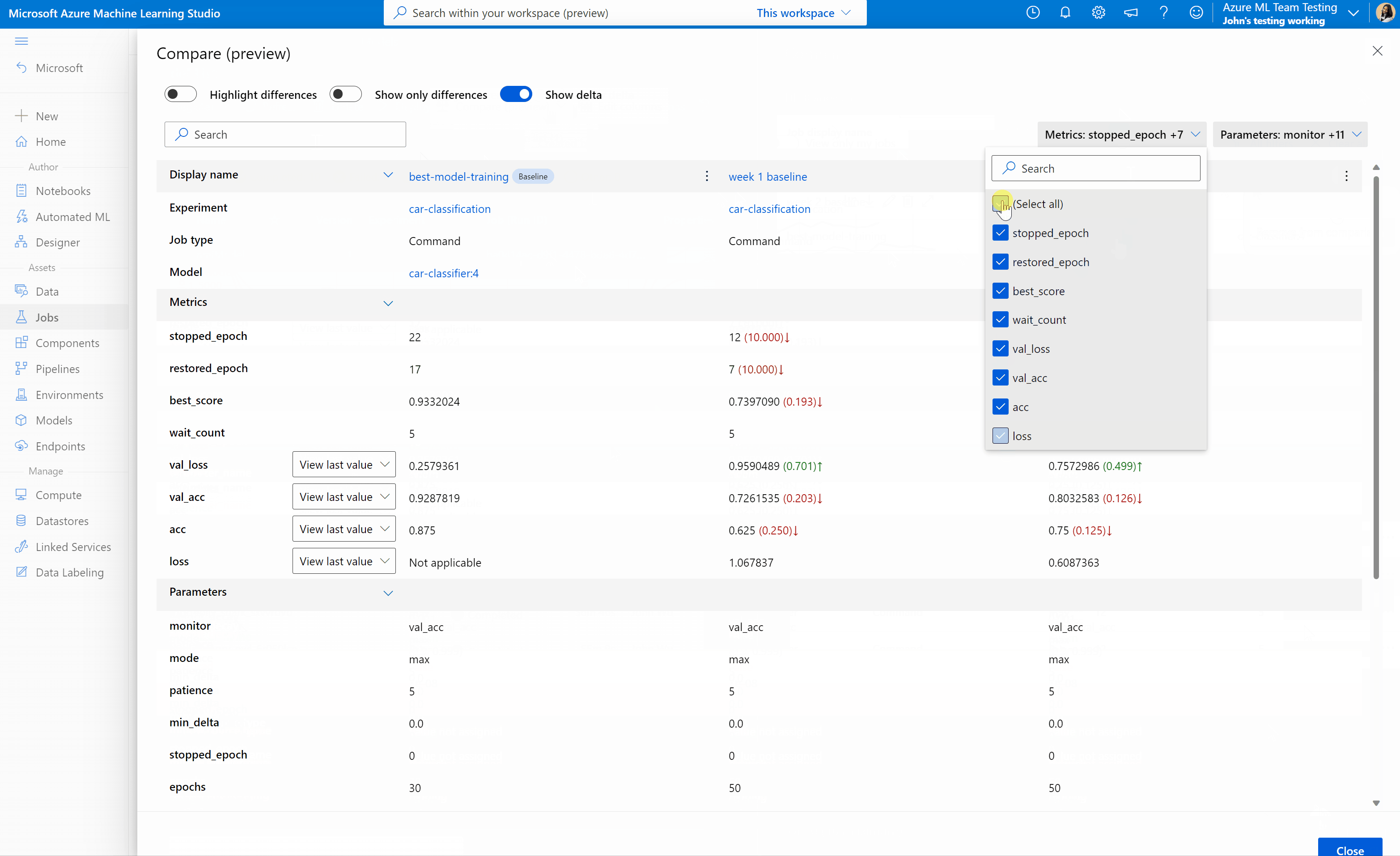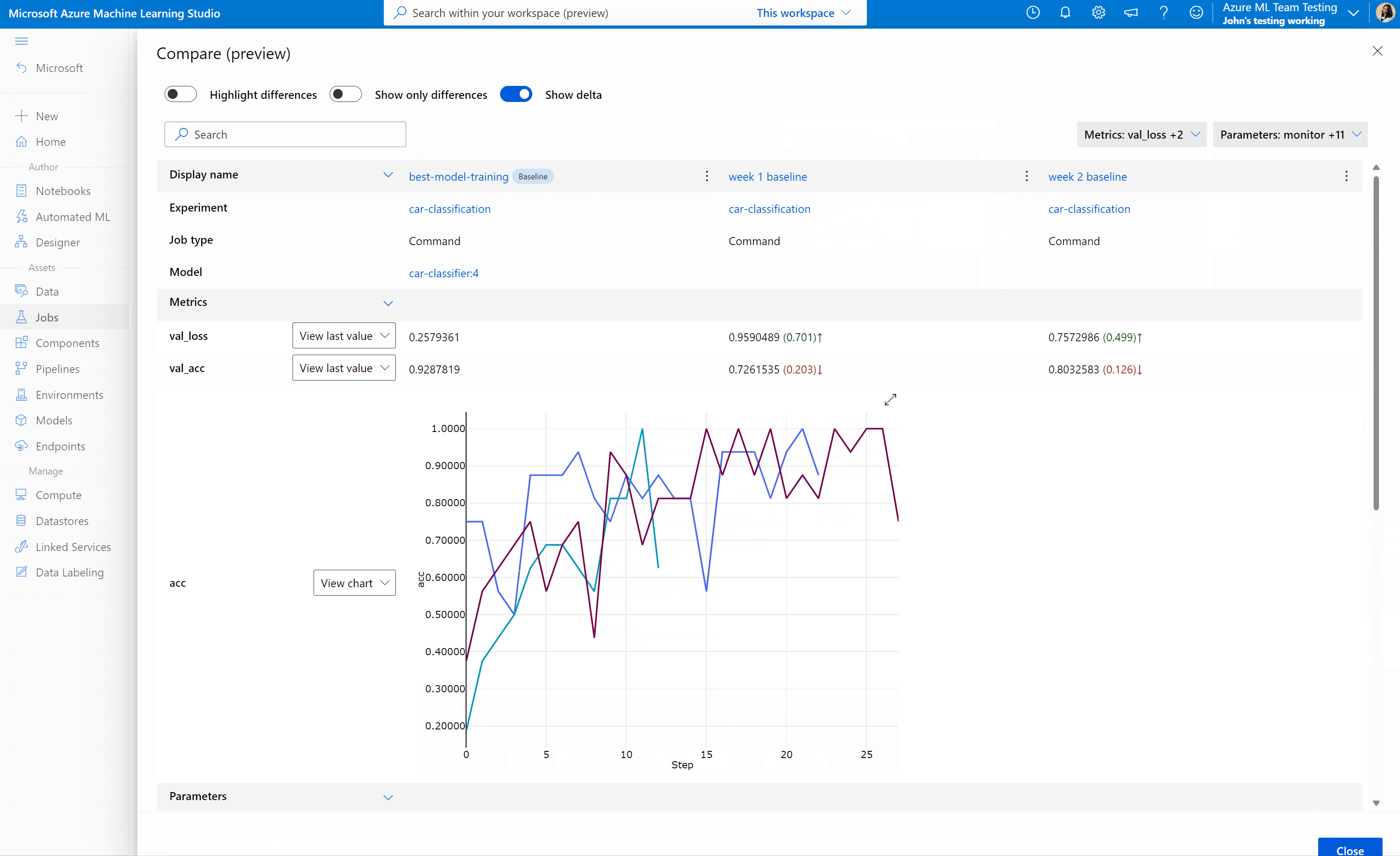
比较 Azure 机器学习工作室中的作业和模型(预览)
若要在 Azure 机器学习工作室中比较和评估作业和模型的质量,请使用预览面板启用该功能。 启用之后,你可以在所选作业和/或模型之间比较参数、指标和标记。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 该预览版在提供时没有附带服务级别协议,建议不要将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
将 MLflow 与 Azure 机器学习笔记本配合使用演示了本文中所述的概念,并在这些概念的基础上有所延伸。
- 使用 MLflow 训练和跟踪分类器:演示如何使用 MLflow 跟踪试验、记录模型并将多种风格组合到管道中。
- 使用 MLflow 管理试验和运行:演示如何使用 MLflow 从 Azure 机器学习查询试验、运行、指标、参数和项目。
运行和试验查询支持矩阵
MLflow SDK 公开了多种检索运行的方法,包括用于控制返回内容和返回方式的选项。 使用下表来了解在连接到 Azure 机器学习后 MLflow 当前支持其中的哪些方法:
| 功能 / 特点 | 受 MLflow 支持 | 受 Azure 机器学习支持 |
|---|---|---|
| 按属性将运行排序 | ✓ | ✓ |
| 按指标将运行排序 | ✓ | 1 |
| 按参数将运行排序 | ✓ | 1 |
| 按标记将运行排序 | ✓ | 1 |
| 按属性筛选运行 | ✓ | ✓ |
| 按指标筛选运行 | ✓ | ✓ |
| 按包含特殊字符(已转义)的指标筛选运行 | ✓ | |
| 按参数筛选运行 | ✓ | ✓ |
| 按标记筛选运行 | ✓ | ✓ |
使用数字比较运算符(指标)筛选运行,运算符包括 =、!=、>、>=、< 和 <= |
✓ | ✓ |
使用字符串比较运算符(参数、标记和属性)筛选运行:= 和 != |
✓ | ✓2 |
使用字符串比较运算符(参数、标记和属性)筛选运行:LIKE/ILIKE |
✓ | ✓ |
使用比较运算符 AND 筛选运行 |
✓ | ✓ |
使用比较运算符 OR 筛选运行 |
||
| 重命名试验 | ✓ |
注意
- 1 查看为运行排序部分,获取有关如何在 Azure 机器学习中实现相同功能的说明和示例。
- 2 不支持标记的
!=。