你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
本文介绍了如何在 Azure 机器学习管道中使用 CLI v2 和 Python SDK v2 运行并行作业。 并行作业可通过在强大的多节点计算群集上分配重复任务来加速作业执行。
机器学习工程师始终需要在其训练或推理任务中满足规模要求。 例如,当数据科学家提供单个脚本来训练销售预测模型时,机器学习工程师需要将此训练任务应用于每个数据存储。 此横向扩展过程的挑战包括导致延迟的长时间执行,以及需要手动干预才能使任务保持运行的意外问题。
Azure 机器学习并行化的核心作业是将单个串行任务拆分为微批,并将这些微批分派到多个计算以并行执行。 并行作业显著减少端到端执行时间,并自动处理错误。 请考虑使用 Azure 机器学习并行作业基于分区数据训练多个模型,或提高大规模批处理推理任务的速度。
例如,在大量映像上运行对象检测模型的情况下,使用 Azure 机器学习并行作业,可以轻松分发映像,以在特定计算群集上并行运行自定义代码。 并行化可以大幅降低时间成本。 Azure 机器学习并行作业还可以简化和自动化流程,从而提高效率。
先决条件
- 有一个 Azure 机器学习帐户和工作区。
- 了解 Azure 机器学习管道。
- 安装 Azure CLI 和
ml扩展。 有关详细信息,请参阅安装、设置和使用 CLI (v2)。 首次运行ml命令时,会自动安装az ml扩展。 - 了解如何使用 CLI v2 创建并运行 Azure 机器学习管道和组件。
使用并行作业步骤创建和运行管道
Azure 机器学习并行作业只能用作管道作业中的一个步骤。
以下示例来自 Azure 机器学习示例存储库中的在管道中使用并行作业运行管道作业。
准备并行化
此并行作业步骤需要准备。 需要一个可实现预定义函数的入口脚本。 还需要在并行作业定义中设置属性:
- 定义并绑定输入数据。
- 设置数据分割方法。
- 配置计算资源。
- 调用入口脚本。
以下各节介绍如何准备并行作业。
声明输入和数据分割设置
并行作业需要拆分然后并行处理一个主要输入。 主要输入数据格式可以是表格数据或文件列表。
不同的数据格式具有不同的输入类型、输入模式和数据分割方法。 下表对这些选项进行说明:
| 数据格式 | 输入类型 | 输入模式 | 数据分割方法 |
|---|---|---|---|
| 文件列表 | mltable 或 uri_folder |
ro_mount 或 download |
按大小(文件数)或分区 |
| 表格数据 | mltable |
direct |
按大小(估计物理大小)或分区 |
注意
如果使用表格 mltable 作为主要输入数据,则需要:
可以使用并行作业 YAML 或 Python 中的 input_data 属性声明主要输入数据,并使用 input 将数据与并行作业的定义 ${{inputs.<input name>}} 绑定。 然后,根据数据分割方法为主要输入定义数据分割属性。
| 数据分割方法 | 特性名 | 属性类型 | 作业示例 |
|---|---|---|---|
| 按大小 | mini_batch_size |
字符串 | Iris 批量预测 |
| 按分区 | partition_keys |
字符串列表 | 橙汁销售预测 |
为并行化配置计算资源
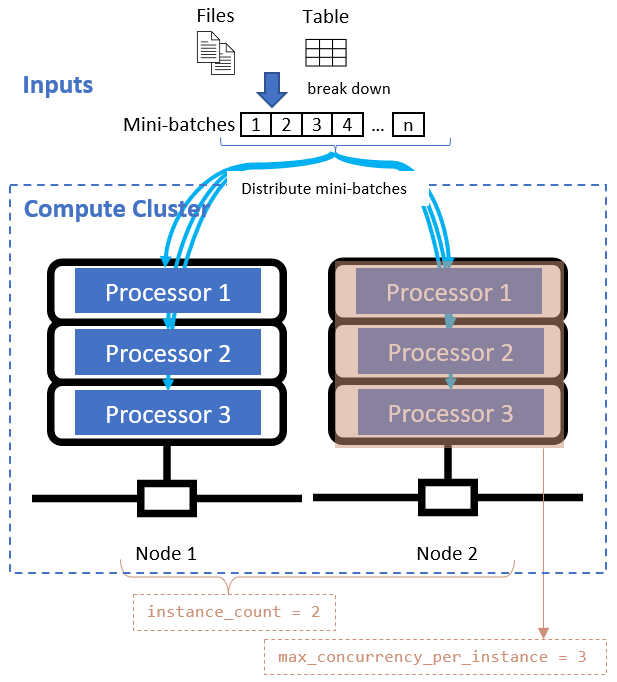
定义数据分割属性后,通过设置 instance_count 和 max_concurrency_per_instance 属性为并行化配置计算资源。
| 特性名 | 类型 | 说明 | 默认值 |
|---|---|---|---|
instance_count |
整型 | 用于作业的节点数。 | 1 |
max_concurrency_per_instance |
整型 | 每个节点上的处理器数量。 | 对于 GPU 计算:1。 对于 CPU 计算:核心数。 |
这些属性与指定的计算群集一起使用,如下图所示:
调用入口脚本
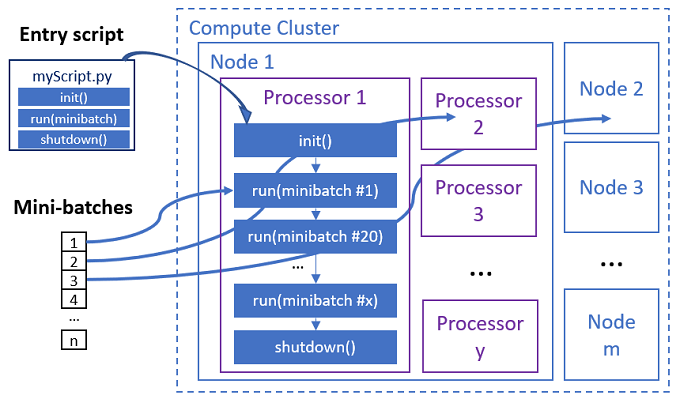
入口脚本是一个单独的 Python 文件,它可使用自定义代码实现以下三个预定义函数。
| 函数名称 | 必须 | 说明 | 输入 | 返回 |
|---|---|---|---|---|
Init() |
Y | 在开始运行微批之前进行常规准备。 例如,使用此函数将模型加载到全局对象。 | -- | -- |
Run(mini_batch) |
Y | 实现微批的主要执行逻辑。 | 如果输入数据是表格数据,则 mini_batch 是 Pandas 数据帧;如果输入数据是目录,则为文件路径列表。 |
数据帧、列表或元组。 |
Shutdown() |
N | 用于在将计算返回到池之前执行自定义清理的可选函数。 | -- | -- |
重要
若要避免在分析 Init() 或 Run(mini_batch) 函数中的参数时出现异常,请使用 parse_known_args 而不是 parse_args。 请参阅包含参数分析程序的入口脚本的 iris_score 示例。
重要
Run(mini_batch) 函数需要数据帧、列表或元组项的返回值。 并行作业使用该返回值的计数来度量该微批下的成功项。 如果处理了所有项,则微批计数应等于返回列表计数。
并行作业在每个处理器中执行函数,如下图所示。
请参阅以下入口脚本示例:
若要调用入口脚本,请在并行作业定义中设置以下两个属性:
| 特性名 | 类型 | 说明 |
|---|---|---|
code |
字符串 | 要上传并用于作业的源代码目录的本地路径。 |
entry_script |
字符串 | 包含预定义并行函数的实现的 Python 文件。 |
并行作业步骤示例
以下并行作业步骤声明输入类型、模式和数据分割方法,绑定输入和配置计算以及调用入口脚本。
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
考虑自动化设置
Azure 机器学习并行作业公开了许多可选设置,可用于自动控制作业,而无需人工干预。 下表对这些设置进行了说明。
| 密钥 | 类型 | 说明 | 允许的值 | 默认值 | 在属性或程序参数中设置 |
|---|---|---|---|---|---|
mini_batch_error_threshold |
整型 | 要在此并行作业中忽略的失败微批数。 如果失败的微批计数高于此阈值,则并行作业将标记为失败。 如果出现以下情况,微批将标记为失败: - run() 的返回计数小于微批输入计数。- 在自定义 run() 代码中捕获到异常。 |
[-1, int.max] |
-1,表示忽略所有失败的微批 |
属性 mini_batch_error_threshold |
mini_batch_max_retries |
整型 | 微批失败或超时时的重试次数。如果所有重试均失败,则根据 mini_batch_error_threshold 计算将微批标记为失败。 |
[0, int.max] |
2 |
属性 retry_settings.max_retries |
mini_batch_timeout |
整型 | 执行自定义 run() 函数所要遵循的超时(以秒为单位)。 如果执行时间高于此阈值,则微批将会中止并标记为失败,以触发重试。 |
(0, 259200] |
60 |
属性 retry_settings.timeout |
item_error_threshold |
整型 | 失败项的阈值。 失败的项是按照每个微批中的输入和返回数量差距统计的。 如果失败的项数之和高于此阈值,则并行作业将标记为失败。 | [-1, int.max] |
-1,表示忽略并行作业期间的所有失败 |
程序参数--error_threshold |
allowed_failed_percent |
整型 | 与 mini_batch_error_threshold 类似,但使用失败的微批数百分比而不是计数。 |
[0, 100] |
100 |
程序参数--allowed_failed_percent |
overhead_timeout |
整型 | 初始化每个微批所要遵循的超时(以秒为单位)。 例如,加载微批数据并将其传递给 run() 函数。 |
(0, 259200] |
600 |
程序参数--task_overhead_timeout |
progress_update_timeout |
整型 | 监视微批执行进度所要遵循的超时(以秒为单位)。 如果在此超时设置内未收到进度更新,则并行作业将标记为失败。 | (0, 259200] |
由其他设置动态计算 | 程序参数--progress_update_timeout |
first_task_creation_timeout |
整型 | 监视从启动作业到运行第一个微批的间隔时间所要遵循的超时(以秒为单位)。 | (0, 259200] |
600 |
程序参数--first_task_creation_timeout |
logging_level |
字符串 | 要转储到用户日志文件的日志级别。 | INFO、WARNING 或 DEBUG |
INFO |
属性 logging_level |
append_row_to |
字符串 | 聚合每次运行微批后的所有返回值并将其输出到此文件中。 可以使用表达式 ${{outputs.<output_name>}} 引用并行作业的输出之一 |
属性 task.append_row_to |
||
copy_logs_to_parent |
字符串 | 指示是否将作业进度、概述和日志复制到父管道作业的布尔选项。 | True 或 False |
False |
程序参数--copy_logs_to_parent |
resource_monitor_interval |
整型 | 将节点资源使用情况(例如 CPU 或内存)转储到“logs/sys/perf”路径下的 log 文件夹的时间间隔(以秒为单位)。 注意:频繁的转储资源日志的执行速度略慢。 将此值设置为“ 0”可停止转储资源使用情况。 |
[0, int.max] |
600 |
程序参数--resource_monitor_interval |
以下示例代码更新了这些设置:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
使用并行作业步骤创建管道
以下示例显示了包含并行作业步骤内联的完整管道作业:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
提交管道作业
在工作室 UI 中检查并行步骤
提交管道作业后,SDK 或 CLI 小组件会提供指向 Azure 机器学习工作室 UI 中的管道图的 Web URL 链接。
若要查看并行作业结果,请双击管道图中的并行步骤,在详细信息面板中,选择“设置”选项卡,展开“运行设置”,然后展开“并行”部分。

若要调试并行作业失败,请选择“输出 + 日志”选项卡,展开“日志”文件夹,并检查“job_result.txt”以了解并行作业失败的原因。 有关并行作业的日志记录结构的信息,请参阅同一文件夹中“readme.txt”。
