你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用变体调整提示
想要编写出好的提示并非易事,需要拥有丰富的创造力、条理要十分清晰,且相关性要很强。 好的提示可以从预先训练的语言模型中获得所需的输出,而不好的提示则会导致不准确、不相关或无意义的输出。 因此,有必要调整提示,来优化不同任务和域的性能和可靠性。
为此,我们引入了变体这一概念,可帮助你在不同条件下(例如不同的措词、格式设置、上下文、温度或 top-k)测试模型的行为,比较并找出能够最大限度保证模型的准确性、多样性或一致性的最佳提示和配置。
在本文中,我们将会演示如何使用变体调整提示,并评估不同变体的性能。
先决条件
在阅读本文之前,建议先参阅以下内容:
如何使用变体调整提示?
本文中,我们将使用 Web 分类示例流作为示例。
打开示例流后,首先删除 prepare_examples 节点。
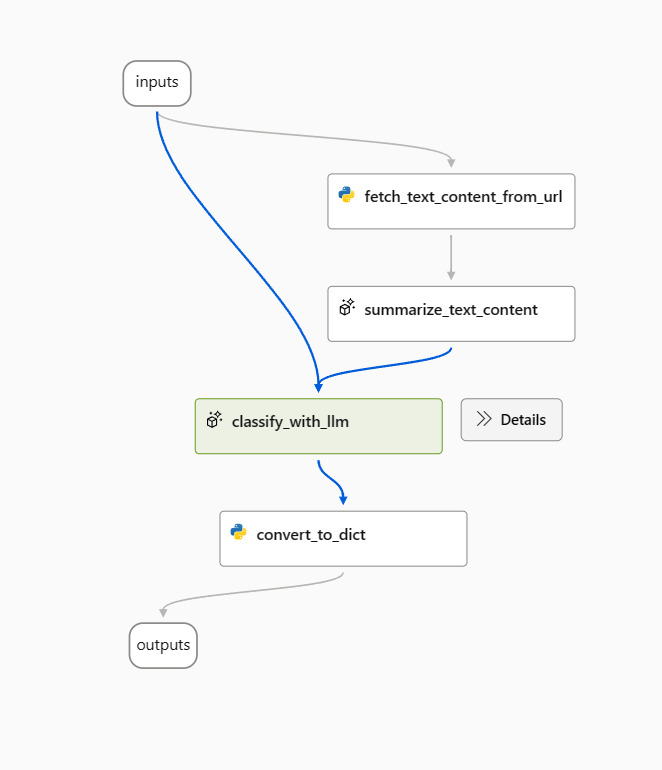
使用以下提示作为 classify_with_llm 节点中的基线提示。

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
可以用多种方法来优化此流,以下是两个优化方向:
如果使用的是 classify_with_llm 节点:我从社区和论文中了解到,降低温度会提高精准率,但创造力和惊喜会随之降低,因为更低的温度适合于处理分类任务,而且少样本提示可以提高 LLM 性能。 因此,我想测试当温度从 1 变为 0 时,以及提示包含示样本示例时,流的行为方式。
如果使用的是 summarize_text_content 节点:我还想测试当我将 100 个字的摘要更改为 300 个字时,流的行为方式,验证更多文本内容是否有助于提高性能。
创建变体
- 选择 LLM 节点右上角的“显示变体”按钮。 现有 LLM 节点是“variant_0”,为默认变体。
- 选择 variant_0 上的“克隆”按钮以生成 variant_1,然后可以将参数配置为不同的值,或者更新 variant_1 上的提示。
- 重复这一步,创建更多变体。
- 选择“隐藏变体”,停止添加更多变体。 所有变体均折叠。 将显示节点的默认变体。
对于基于“variant_0”的 classify_with_llm 节点:
- 创建 variant_1,其中温度从 1 更改为 0。
- 创建 variant_2,其中温度为 0,你可以使用以下提示,其中包括少样本示例。
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
对于基于“variant_0”的 summarize_text_content 节点,可以创建“variant_1”,其中提示中的 100 words 更改为 300 个字。
现在,流如下所示,summarize_text_content 节点有 2 个变体,classify_with_llm 节点有 3 个变体。
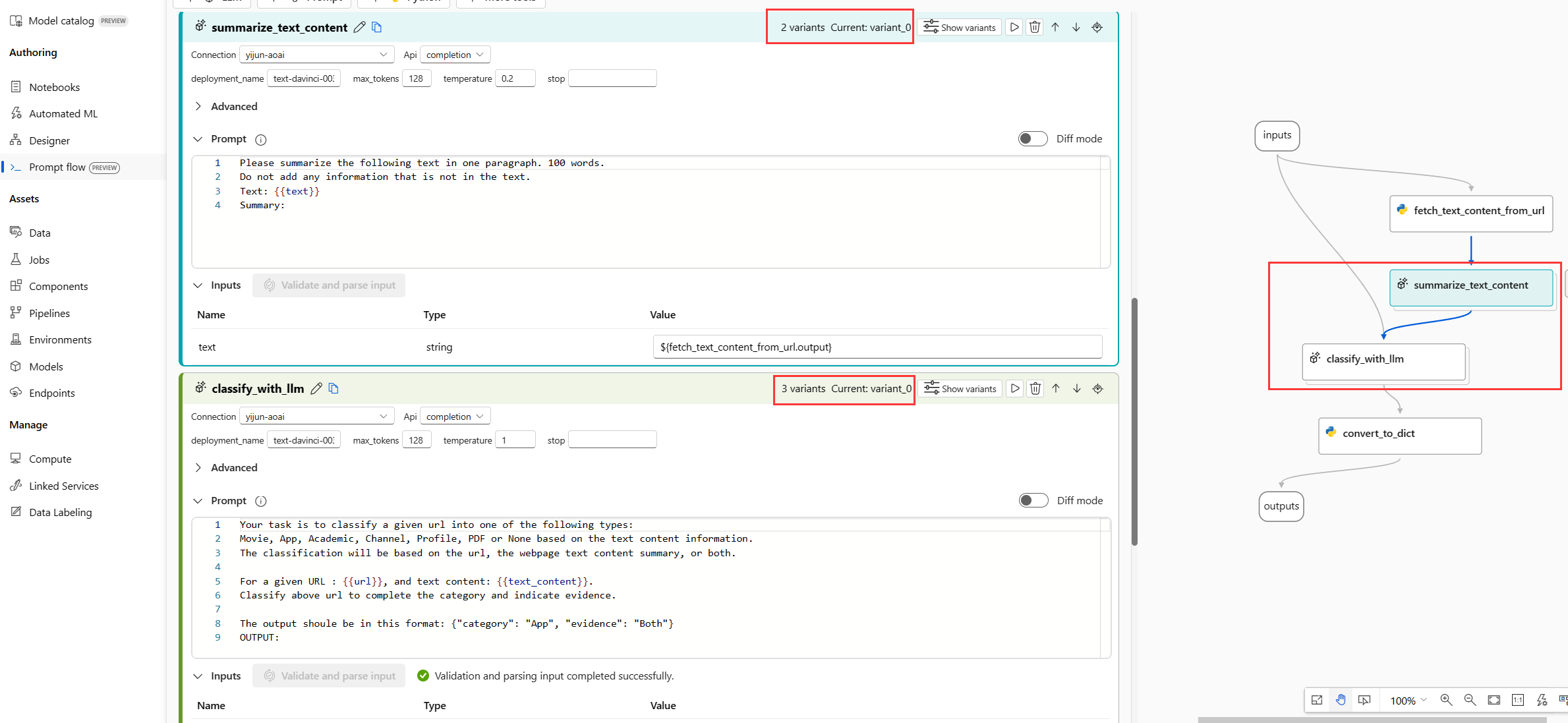
运行只包含一行数据的所有变体并查看输出
可以运行只包含一行数据的流进行测试,确保所有变体都可以成功运行并按预期工作。
注意
每次只能选择一个 LLM 节点使用多个变体运行,而其他 LLM 节点则会使用默认变体。
在此示例中,我们同时为 summarize_text_content 节点和 classify_with_llm 节点配置变体,因此要运行两次才能测试所有变体。
- 选择右上角的“运行”按钮。
- 选择一个具有变体的 LLM 节点。 其他 LLM 节点将使用默认变体。
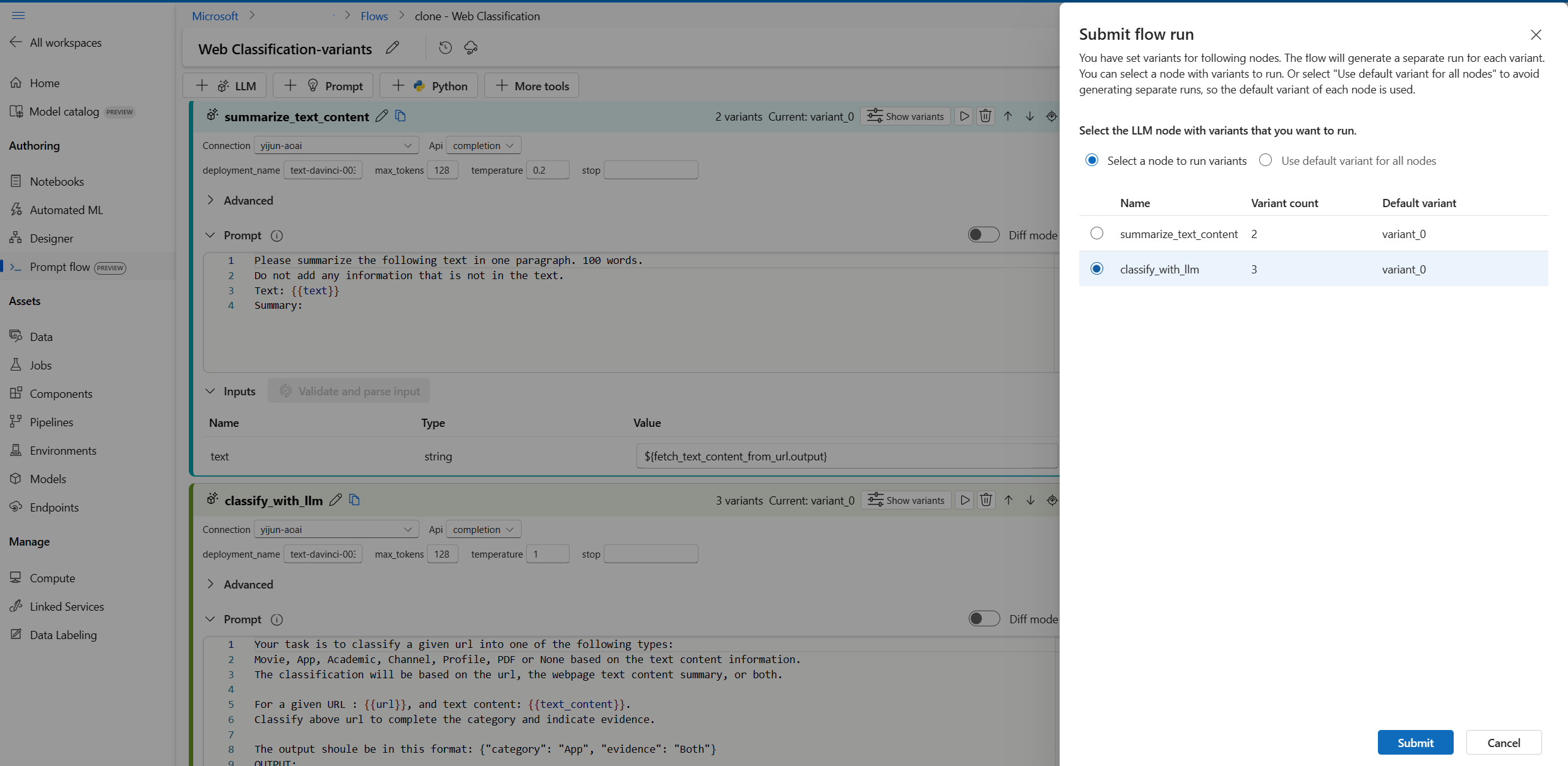
- 提交流运行。
- 流运行完成后,可以查看每个变体相应的结果。
- 提交另一个使用具有变体的另一个 LLM 节点的流运行,并查看输出。
- 可以更改另一个输入数据(例如,使用维基百科页面 URL)并重复上述步骤测试不同数据的变体。

评估变体
当你运行只包含当量数据的变体并用肉眼查看结果时,无法反映现实世界数据的复杂性和多样性,同时也不能量化输出,因此很难比较不同变体的有效性,然后选出最佳变体。
你可以提交批运行,它让你能够测试包含大量数据的变体,并利用指标对其进行评估,帮助你找到最适合的变体。
首先,需要准备一个数据集,足以代表你希望利用提示流解决的现实世界的问题。 在此示例中,数据集是一份 URL 列表及其分类基本事实。 我们将会使用准确度来评估变体的性能。
选择页面右上角的“评估”。
此时会出现“批处理运行和评估”向导。 第一步:选择一个节点来运行其所有变体。
要测试流中每个节点运行不同变体时变体的性能表现,则需要逐一为具有变体的每个节点运行批运行。 这样做有助于避免其他节点中的变体造成的影响,并且专注于此节点的变体的运行结果。 此方法遵循受控试验的规则,也就是说一次只更改一个变量,其他变量保持不变。
例如,可以选择 classify_with_llm 节点来运行所有变体,summarize_text_content 节点则会使用其默认变体进行本次批运行。
接下来,在“批运行设置”中,可以设置批运行名称、选择运行时、上传准备好的数据。
接下来,在“评估设置”中,选择一个评估方法。
由于此流用于进行分类,因此可以选择“分类准确度评估”方法来评估准确度。
准确度的计算方式如下:将流(预测)分配的预测标签与数据(基本事实)的实际标签进行比较,并计算出两者之间有多少匹配项。
在“评估输入映射”部分中,需要指定来自输入数据集类别列的基本事实,以及来自其中一个流输出的预测:类别。
检查好所有设置后,就可以提交批运行了。
提交运行后,选择链接,转到运行详细信息页。
注意
运行可能需要几分钟才能完成。
可视化输出
- 批运行和评估运行完成后,在运行详细信息页中,为每个变体多选批运行,然后选择“可视化输出”。 你将看到 classify_with_llm 节点的 3 个变体的指标,以及每个数据记录的 LLM 预测输出。
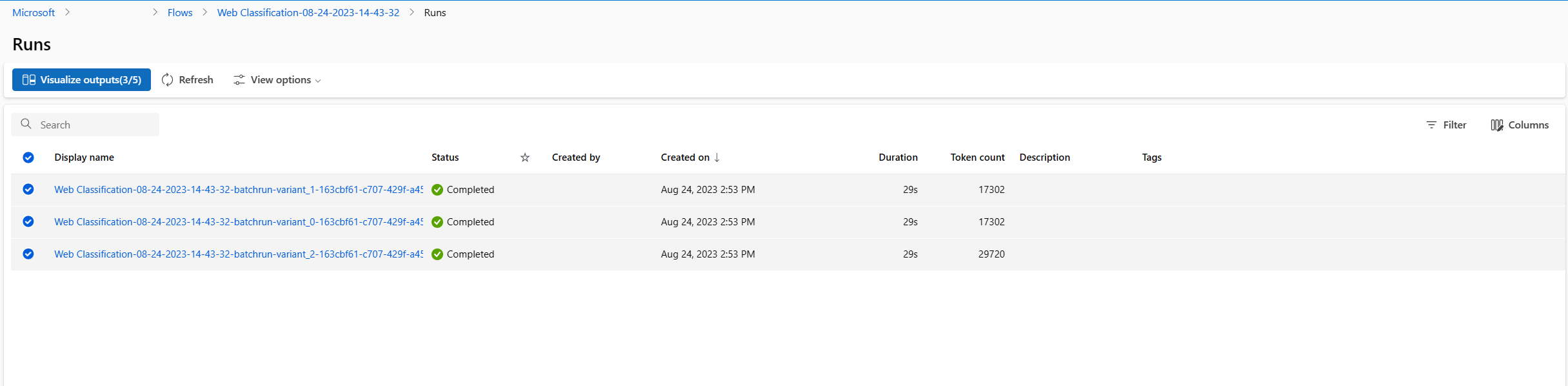
- 确定哪个变体是最佳变体后,可以返回到流创建页面,将该变体设置为节点的默认变体
- 也可以重复上述步骤评估 summarize_text_content 节点的变体。
现在,你已完成了使用变体调整提示的流程。 可以将此技巧应用于自己的提示流,找到 LLM 节点的最佳变体。