你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
评估流是一种特殊类型的提示流,用于计算指标,以评估运行的输出符合特定标准和目标的程度。 可以创建或自定义针对任务和目标定制的评估流和指标,并使用其评估其他提示流。 本文介绍评估流、如何开发和自定义评估流,以及如何在提示流批处理运行中使用评估流来评估流性能。
了解评估流
提示流是处理输入并生成输出的节点序列。 评估流还使用所需的输入并生成相应的输出,这些输出通常是分数或指标。 评估流与其创作体验和使用情况中的标准流不同。
评估流通常在其测试的运行后运行,通过接收其输出并使用输出来计算分数和指标来测试。 评估流使用提示流 SDK log_metric() 函数记录指标。
评估流的输出是衡量所测试流性能的结果。 评估流可能具有一个聚合节点,该节点会计算测试数据集中要测试的流的总体性能。
后续部分将介绍如何在评估流中定义输入和输出。
输入
评估流通过获取要测试的运行输出来计算批处理运行的指标或分数。 例如,如果所测试的流是一个 QnA 流,该流会根据问题生成答案,则可以将评估输入命名为 answer。 如果所测试的流是将文本分类为类别的分类流,则可以将评估输入命名为 category。
可能需要其他输入作为基本事实。 例如,如果要计算分类流的准确度,则需要将数据集的 category 列作为基本事实提供。 如果要计算 QnA 流的准确度,则需要将数据集的 answer 列作为基本事实提供。 可能需要一些其他输入来计算指标,例如 QnA 或检索增强生成 (RAG) 场景中的 question 和 context。
可以像定义标准流的输入一样定义评估流的输入。 默认情况下,评估与要测试的运行使用同一数据集。 但如果相应的标签或目标基准真值位于不同的数据集中,则可以轻松切换到该数据集。
输入说明
若要描述计算指标所需的输入,可以添加说明。 在批处理运行提交中映射输入源时,将显示说明。
若要为每个输入添加说明,请在开发评估方法时在输入部分选择“显示说明”,然后输入说明。

若要隐藏输入窗体中的说明,请选择“隐藏说明”。

输出和指标
评估的输出是显示所测试流性能的结果。 输出通常包含分数等指标,还可能包含用于推理和建议的文本。
输出分数
提示流一次处理一行数据,并生成输出记录。 同样,评估流可以计算每一行数据的分数,因此你可以检查流对每个单个数据点的性能。
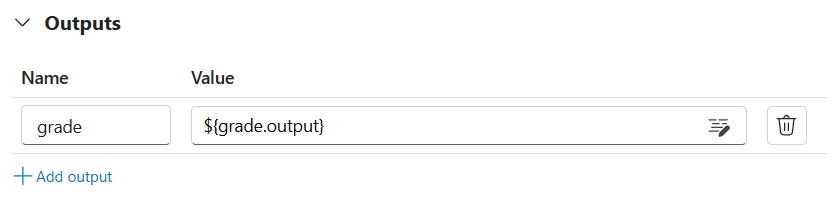
可以通过在评估流的输出部分指定每个数据实例的分数,将其记录为评估流输出。 此创作体验与定义标准流输出相同。
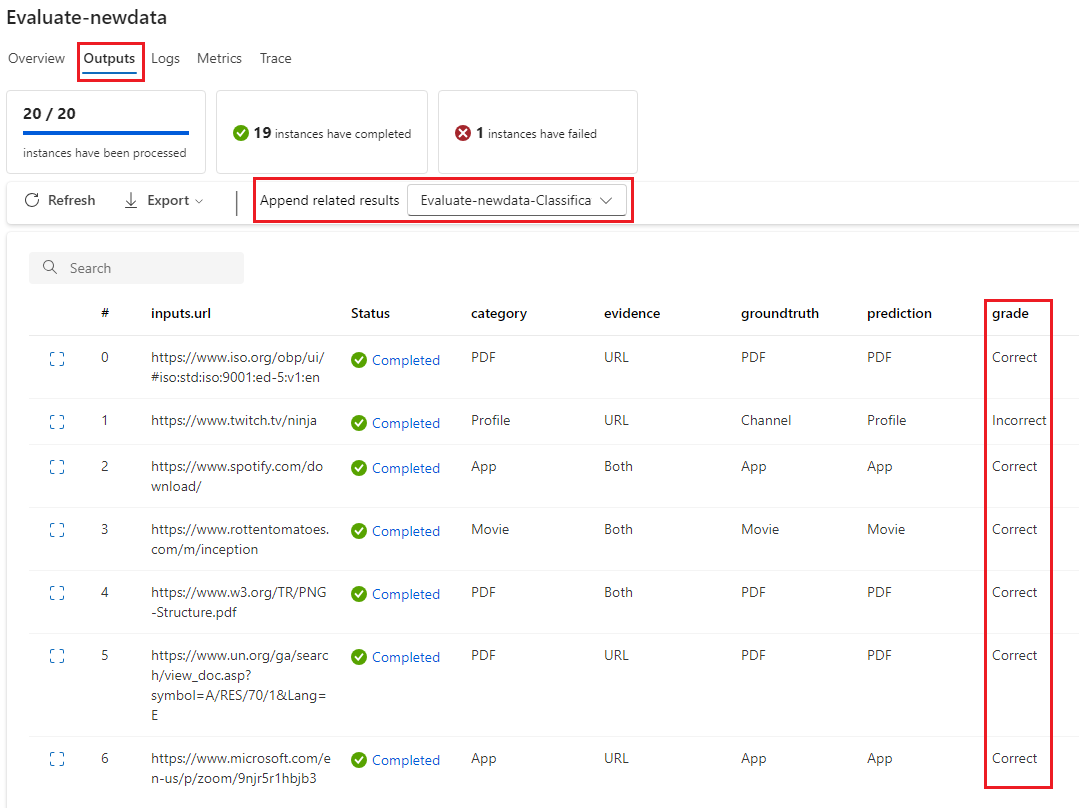
选择“查看输出”时,可以在“输出”选项卡中查看各个分数,这与查看标准流批处理运行的输出相同。 可以将这些实例级分数追加到测试流的输出。
聚合和指标日志记录
评估流还提供针对运行的总体评估。 为了区分单个输出分数的总体结果,这些总体运行性能值称为“指标”。
若要根据单个分数计算总体评估值,请在评估流中的 Python 节点上选中“聚合”复选框,将其转换为“化简”节点。 然后,该节点将以列表的形式接受输入并批量处理。

通过使用聚合,可以计算和处理每个流输出的所有分数,并使用每个分数计算总体结果。 例如,若要计算分类流的准确度,可以计算每个分数输出的准确度,然后计算所有分数输出的平均准确度。 然后,你可以使用 promptflow_sdk.log_metric() 将平均准确度记录为指标。 指标必须为数字,例如 float 或 int。 不支持字符串类型指标日志记录。
以下代码片段是一个示例,展示通过平均所有数据点的准确度分数 grades 来计算总体准确度。 使用 promptflow_sdk.log_metric() 将总体准确度记录为指标。
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
由于在 Python 节点中调用此函数,因此无需在其他地方分配它,并且稍后可以查看指标。 在批处理运行中使用此评估方法后,可以通过在查看输出时选择“指标”选项卡来查看显示总体性能的指标。

开发评估流
若要开发自己的评估流,请在 Azure 机器学习工作室的“提示流”页上选择“创建”。 在“创建新流”页上,可以:
在“按类型创建”下的“评估流”卡上选择“创建”。 此选择可提供用于开发新评估方法的模板。
在“浏览库”中选择“评估流”,然后从中选择一个可用的内置流。 选择“查看详细信息”以获取每个流的摘要,然后选择“克隆”以打开和自定义流。 流创建向导可帮助你根据自己的场景修改流。

计算每个数据点的分数
评估流计算数据集上运行的流的分数和指标。 评估流的第一步是计算每个单独数据输出的分数。
例如,在内置的分类准确度评估流中,grade 在“成绩”Python 节点中计算,衡量的是每个流生成的输出与相应的基本事实相比的准确度。
如果使用评估流模板,可在line_process Python 节点中计算此分数。 还可以将 line_process python 节点替换为大型语言模型 (LLM) 节点,以使用 LLM 计算分数,或使用多个节点执行计算。

将此节点的输出指定为评估流的输出,这表示输出就是为每个数据样本计算的分数。 还可以将推理输出为更多信息,这与在标准流中定义输出的体验相同。
计算和记录指标
评估的下一步是计算用于评估运行的总体指标。 在已选择“聚合”选项的 Python 节点中计算指标。 此节点接受上一个计算节点的分数,并将其组织到列表中,然后计算总体值。
如果使用评估模板,则会在“聚合”节点中计算此分数。 以下代码片段显示了聚合节点的模板。
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
可以使用自己的聚合逻辑,例如计算分数的平均值、中值或标准偏差。
使用 promptflow.log_metric() 函数记录指标。 可以在单个评估流中记录多个指标。 指标必须为数字 (float/int)。
使用评估流
创建自己的评估流和指标后,可以使用此流来评估标准流的性能。 例如,可以评估 QnA 流以测试其在处理大型数据集时的性能。
在 Azure 机器学习工作室中,打开要评估的流,然后选择顶部菜单栏中的“评估”。

在“批处理运行和评估”向导中,完成“基本设置”和“批处理运行设置”,加载数据集以测试和配置输入映射。 有关详细信息,请参阅提交批处理运行和评估流。
在“选择评估”步骤中,可以选择一个或多个要运行的自定义评估或内置评估。 “自定义评估”列出了创建、克隆或自定义的所有评估流。 处理同一项目的其他人创建的评估流不会显示在本节中。
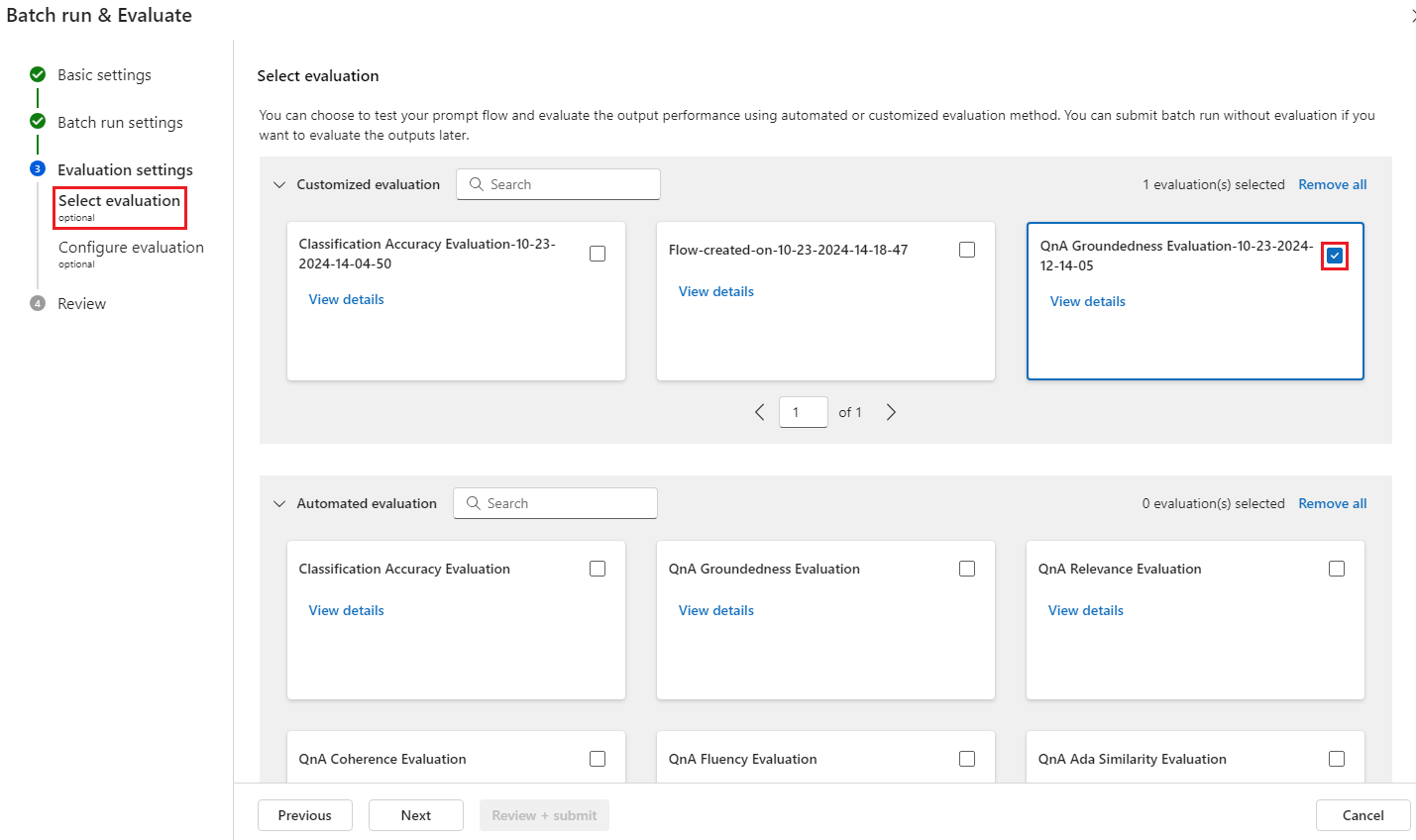
在“配置评估”屏幕上,指定评估方法所需的任何输入数据的源。 例如,基本事实列可能来自数据集。 如果评估方法不需要数据集中的数据,则无需选择数据集,也不需要引用输入映射部分中的任何数据集列。
在“评估输入映射”部分中,可以指示评估所需的输入的源。 如果数据源来自运行输出,则将源设置为
${run.outputs.[OutputName]}如果数据来自测试数据集,则将源设置为${data.[ColumnName]}。 为数据输入设置的任何说明也会在此处显示。 有关详细信息,请参阅提交批处理运行和评估流。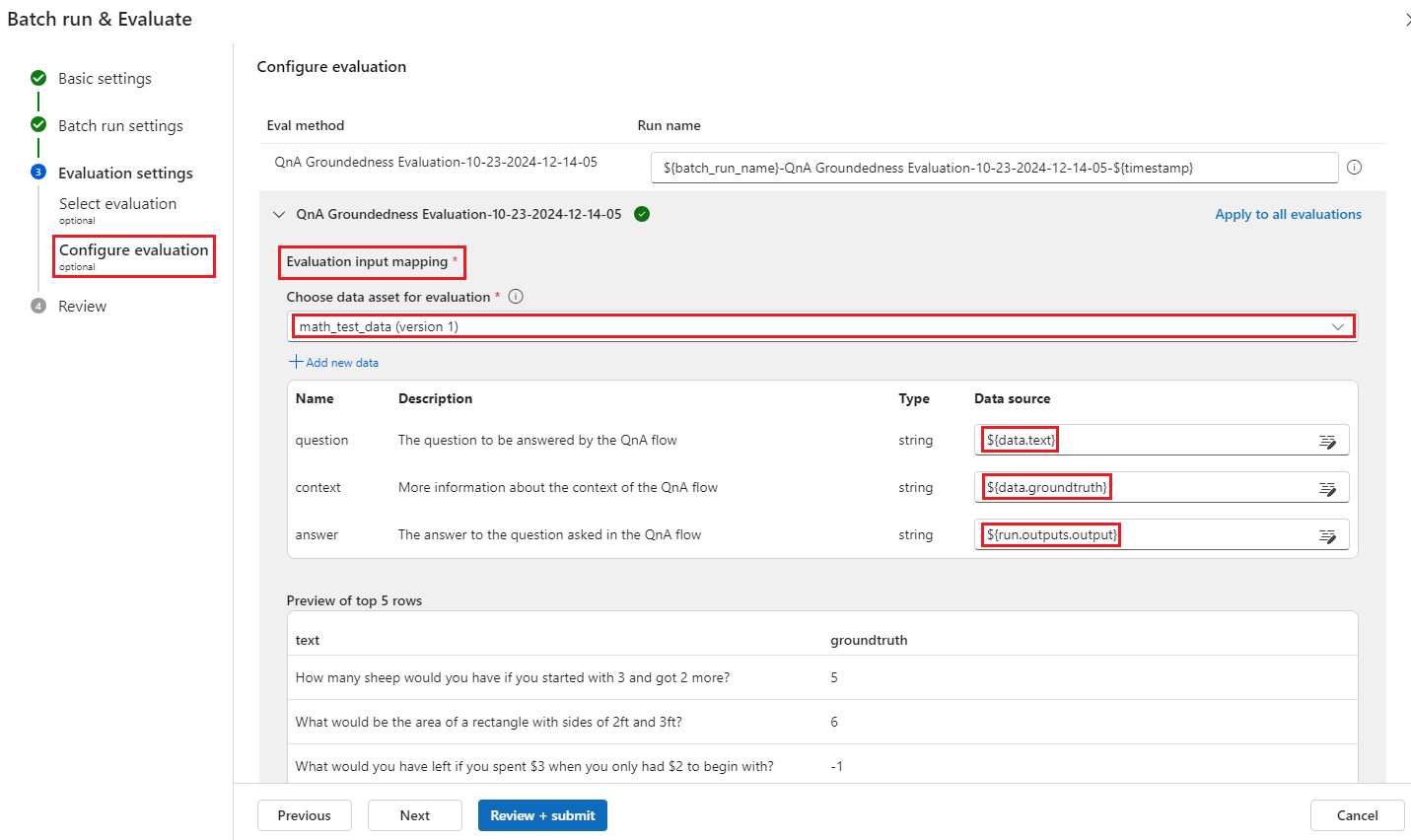
重要
如果评估流具有 LLM 节点或需要连接才能使用凭据或其他密钥,则必须在此屏幕的“连接”部分中输入连接数据才能使用评估流。
选择“查看 + 提交”,然后选择“提交”以运行评估流。
评估流完成后,可以通过选择评估流顶部的“查看批处理运行”>“查看最新的批处理运行输出”来查看实例级分数输出。 从“追加相关结果”下拉列表中选择评估运行,以查看每个数据行的“成绩”。