你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure Managed Instance for Apache Cassandra 为托管的开源 Apache Cassandra 数据中心提供自动部署和缩放操作。 此功能可加速混合方案,并帮助减少持续维护。
本快速入门演示如何使用 Azure 门户在 Azure 托管实例 for Apache Cassandra 群集的 Azure 虚拟网络中创建完全托管的 Apache Spark 群集。 你在 Azure Databricks 中创建 Spark 群集。 之后,你可创建笔记本或将其附加到群集、从不同的数据源读取数据,还可分析见解。
还可以详细了解如何在 Azure 虚拟网络(虚拟网络注入)中部署 Azure Databricks。
Prerequisites
如果没有 Azure 订阅,请在开始之前创建一个免费帐户。
创建 Azure Databricks 群集
按照以下步骤在虚拟网络中创建具有 Azure Managed Instance for Apache Cassandra 的 Azure Databricks 群集:
登录 Azure 门户。
在左窗格中,找到 资源组。 转到部署托管实例的虚拟网络所在的资源组。
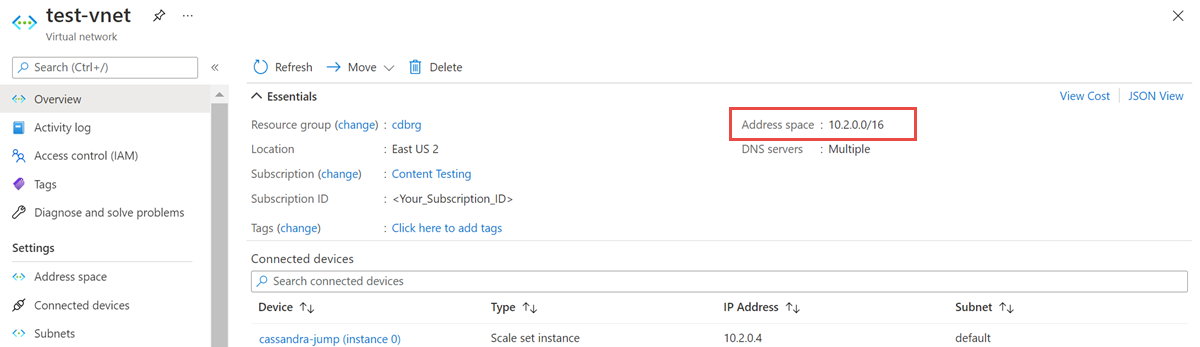
打开 虚拟网络 资源,并记下 地址空间。
在资源组中,选择“ 添加 ”并在搜索字段中搜索 Azure Databricks 。
选择 “创建 ”以创建 Azure Databricks 帐户。
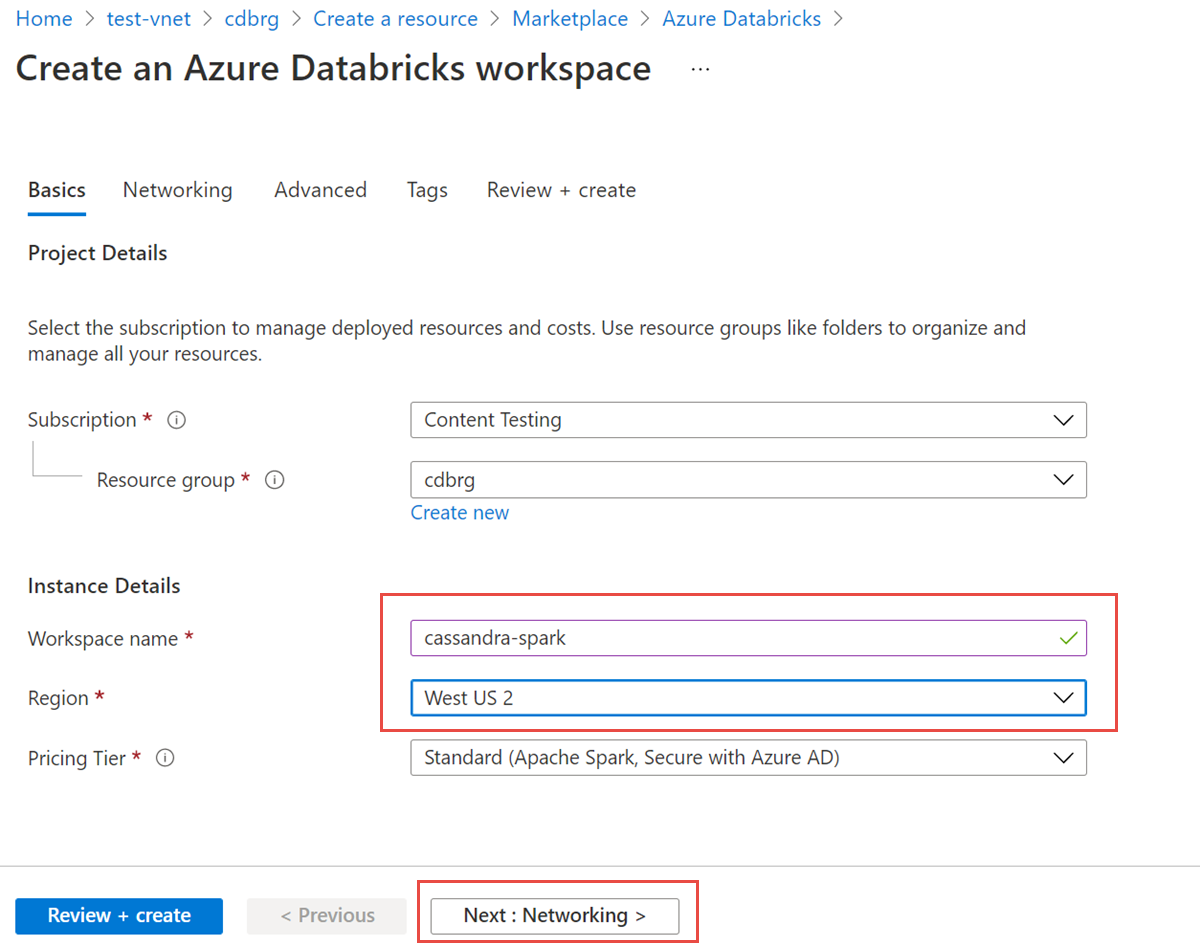
输入以下值:
- 工作区名称:提供 Azure Databricks 工作区的名称。
- 区域:请确保选择与虚拟网络相同的区域。
- 定价层:选择“标准”、“高级”或“试用版”。 有关这些层的详细信息,请参阅 Azure Databricks 定价页。
选择“ 网络 ”选项卡,并输入以下详细信息:
- 在虚拟网络(VNet)中部署 Azure Databricks 工作区:选择 “是”。
- 虚拟网络:从下拉列表中,选择托管实例所在的虚拟网络。
- 公共子网名称:输入公共子网的名称。
- 公共子网 CIDR 范围:输入公共子网的 IP 范围。
- 专用子网名称:输入专用子网的名称。
- 专用子网 CIDR 范围:输入专用子网的 IP 范围。
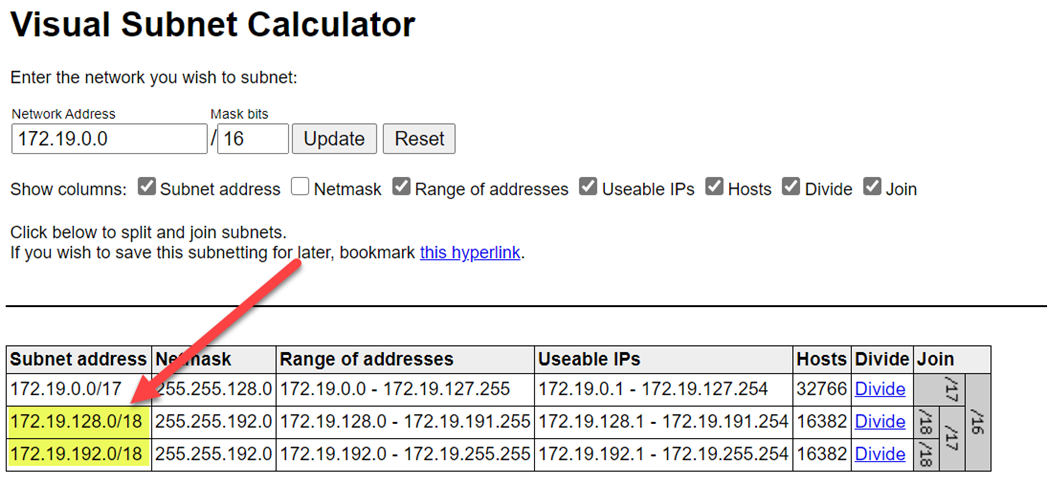
为避免范围冲突,请确保选择更高的范围。 如有必要,请使用 可视子网计算器 来划分范围。
以下屏幕截图显示了网络窗格中的示例详细信息。
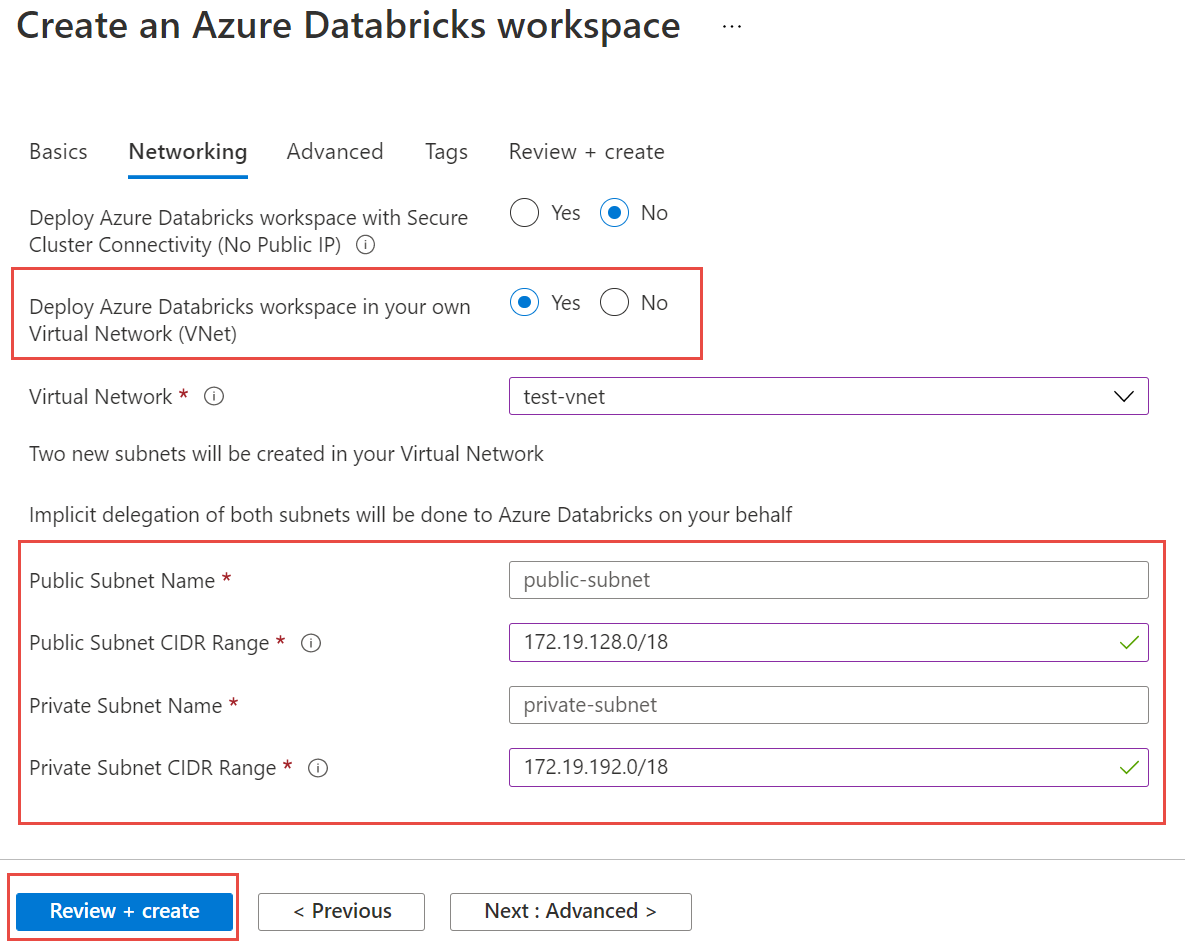
选择 “查看 + 创建”,然后选择“ 创建 ”以部署工作区。
创建好工作区后打开它。
系统随后会将你重定向到 Azure Databricks 门户。 在门户中选择“新建群集”。
在 “新建群集 ”窗格中,接受除以下字段以外的所有字段的默认值:
- 群集名称:输入群集的名称。
- Databricks Runtime 版本:建议为 Spark 3.x 支持选择 Azure Databricks 运行时版本 7.5 或更高版本。
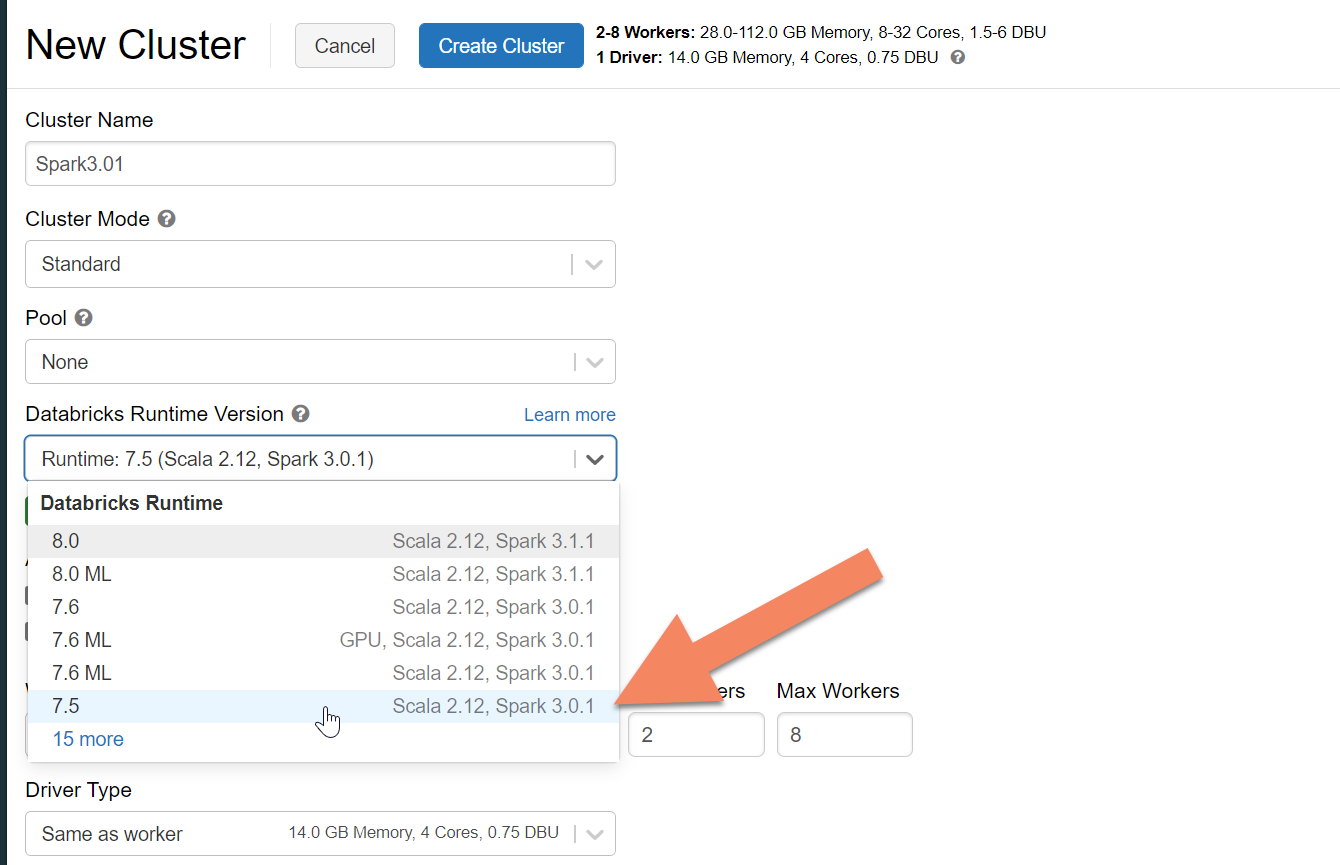
展开 “高级选项”,并添加以下配置。 请确保替换节点 IP 和凭据。
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled true将 Apache Spark Cassandra 连接器库添加到群集,以便连接到原生终结点和 Azure Cosmos DB Cassandra 终结点。 在群集中,选择“库>安装新>Maven”,然后在“Maven
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0”字段中添加。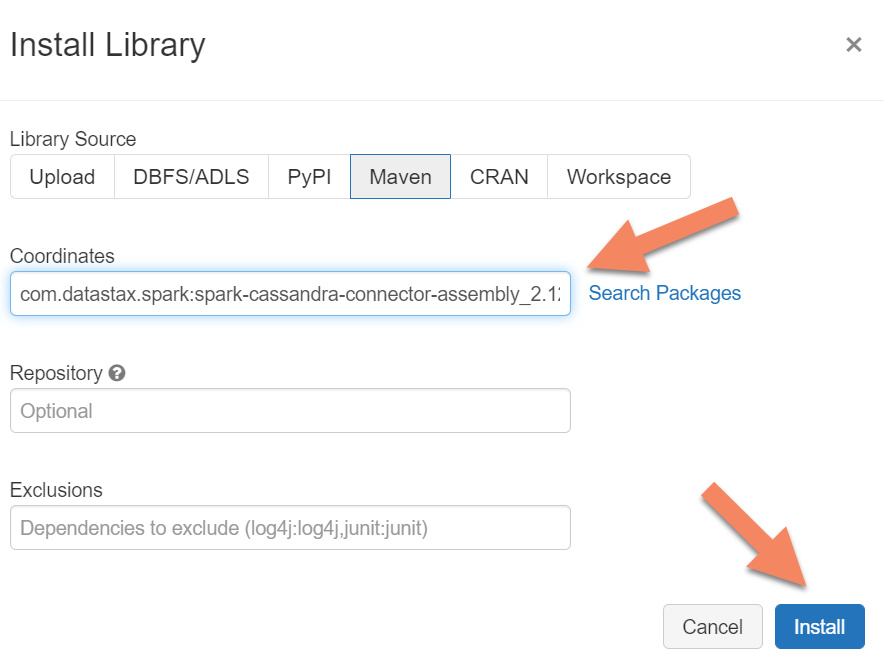
选择“安装”。
清理资源
如果不打算继续使用此托管实例群集,请执行以下步骤将其删除:
- 在 Azure 门户的左侧菜单上选择“资源组” 。
- 从列表中选择为本快速入门创建的资源组。
- 在资源组的“概述”窗格上,选择“删除资源组”。
- 在下一个窗格中,输入要删除的资源组的名称,然后选择“ 删除”。
后续步骤
本快速入门介绍了如何在 Azure 托管实例 for Apache Cassandra 群集的虚拟网络中创建完全托管的 Apache Spark 群集。 接下来,了解如何管理群集和数据中心资源。