你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在本文中,你将了解如何使用 Azure 机器学习数据集和 Azure 开放数据集将精选的扩充数据引入本地或远程机器学习实验中。
准备好 Azure 机器学习数据集后,可以创建对数据源位置的引用及其元数据的副本。 由于数据集是延迟计算的,并且数据仍保留在其现有位置,因此
- 不会冒无意中更改原始数据源的风险
- 不会产生额外的存储成本
- 会提高 ML 工作流性能速度
有关数据集如何适应 Azure 机器学习的整体数据访问工作流的详细信息,请访问安全访问数据一文。
Azure 开放数据集是精选的公共数据集,可用于添加方案特定的功能,以扩充预测性解决方案并提高其准确度。 请访问开放数据集目录资源,了解可帮助训练机器学习模型的公共领域数据 - 例如:
开放数据集托管在 Microsoft Azure 云中。 Azure 机器学习 Python SDK 和 Azure 机器学习工作室均包含开放数据集。
先决条件
需要:
Azure 订阅。 如果没有订阅,请在开始之前创建一个免费帐户。 试用免费版或付费版 Azure 机器学习。
一个 Azure 机器学习工作区。
已安装适用于 Python 的 Azure 机器学习 SDK,其中包含
azureml-datasets包。- 创建一个 Azure 机器学习计算实例,它是一个完全配置且托管的开发环境,其中包括集成的笔记本和已安装的 SDK。
或
- 在自己的 Python 环境中,按照这些说明自行安装 SDK。
注意
某些数据集类依赖于 azureml-dataprep 包。 此包仅与 64 位 Python 兼容。 对于 Linux 用户,只有以下 Linux 发行版支持这些类:
- Debian(8、9)
- Fedora(27、28)
- Red Hat Enterprise Linux(7、8)
- Ubuntu(14.04、16.04、18.04)
使用 SDK 创建数据集
若要在 Python SDK 中通过 Azure 开放数据集类创建 Azure 机器学习数据集,请确保已使用 pip install azureml-opendatasets 安装包。 在 SDK 中,每个离散数据集的类代表该类,某些类可用作 Azure 机器学习 FileDataset 数据类型和/或 Azure 机器学习 TabularDataset 数据类型。 有关 opendatasets 类的完整列表,请访问参考文档。
可以将某些 opendatasets 类作为 TabularDataset 或 FileDataset 资源进行检索。 然后可以直接操作和/或下载文件。 其他类只能使用 Python SDK 中 Dataset 类的 get_tabular_dataset() 或 get_file_dataset() 函数来检索数据集。
以下代码显示 MNIST opendatasets 类可返回 TabularDataset 或 FileDataset:
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
在此示例中,糖尿病 opendatasets 类仅可用作 TabularDataset。 这需要使用 get_tabular_dataset()。
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
注册数据集
在工作区中注册 Azure 机器学习数据集,以便可与其他人共享并可在工作区中的各实验中重复使用该数据集。 注册从开放数据集创建的 Azure 机器学习数据集时,不会立即下载数据,但在请求时(例如在训练期间)将从集中存储位置访问数据。
若要在工作区中注册数据集,请使用 register() 方法。
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
使用工作室创建数据集
还可以使用 Azure 机器学习工作室基于 Azure 开放数据集创建 Azure 机器学习数据集。 这个整合的 Web 界面包括机器学习工具,所有技能级别的数据科学专业人员均可利用这些工具实现数据科学方案。
注意
通过 Azure 机器学习工作室创建的数据集会自动注册到工作区。
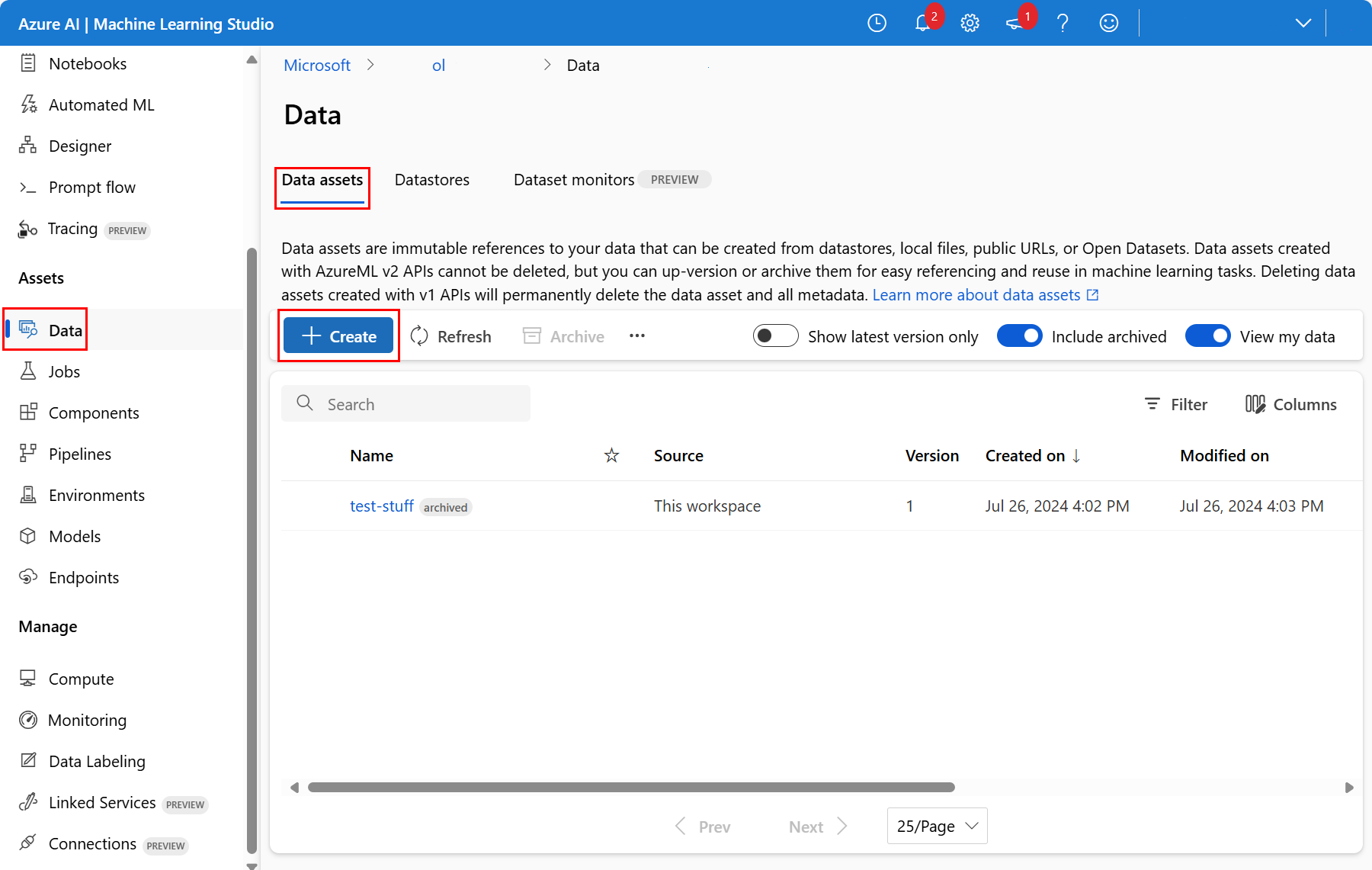
在工作区中,选择左侧导航栏中的“数据”。 在“数据资产”选项卡上选择“创建”,如以下屏幕截图所示:
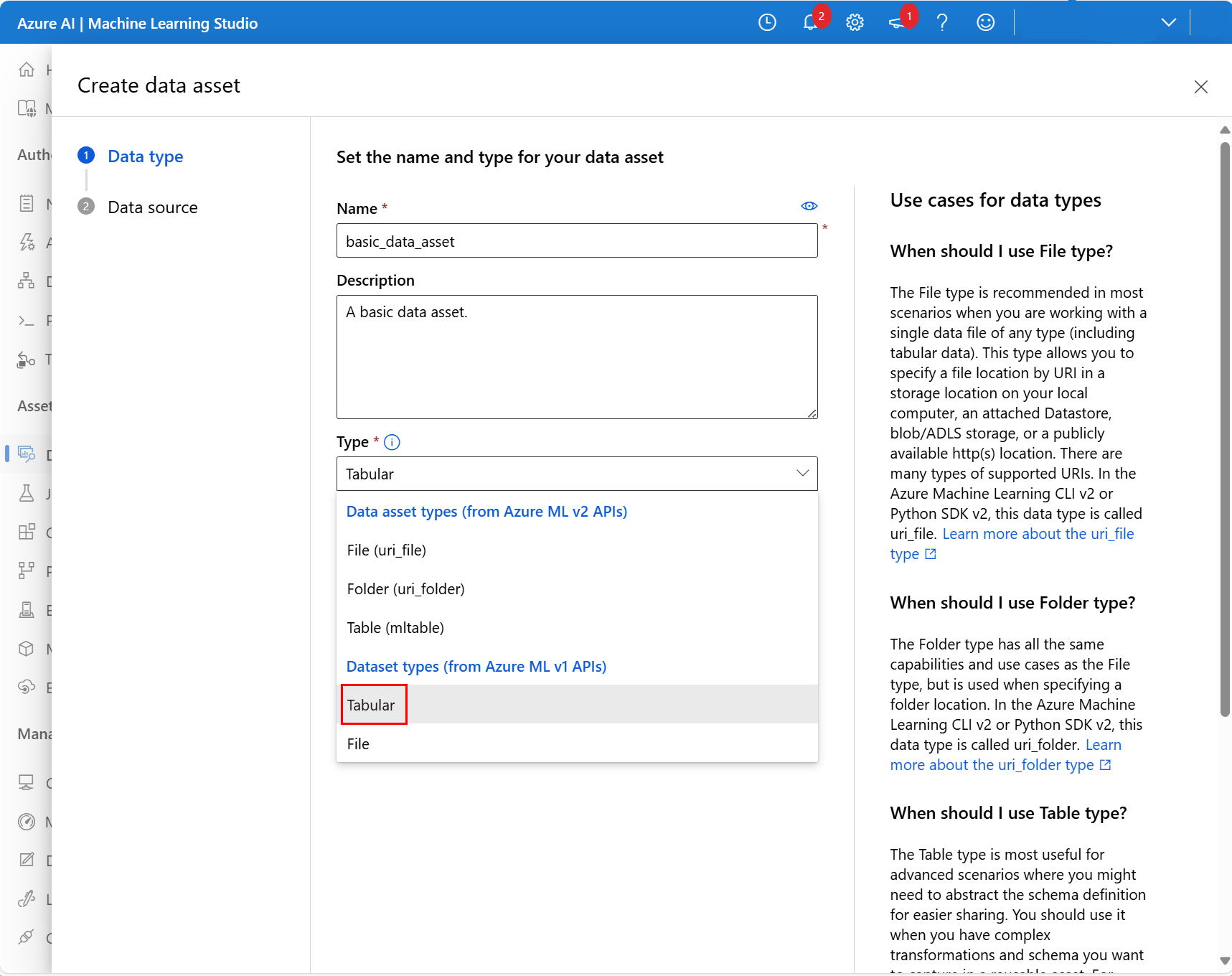
在下一个屏幕中,为新数据资产添加名称和可选的说明。 然后,在“类型”下拉列表中选择“表格”,如以下屏幕截图所示:
在下一个屏幕中,选择“从 Azure 开放数据集”,然后选择“下一步”,如以下屏幕截图所示:

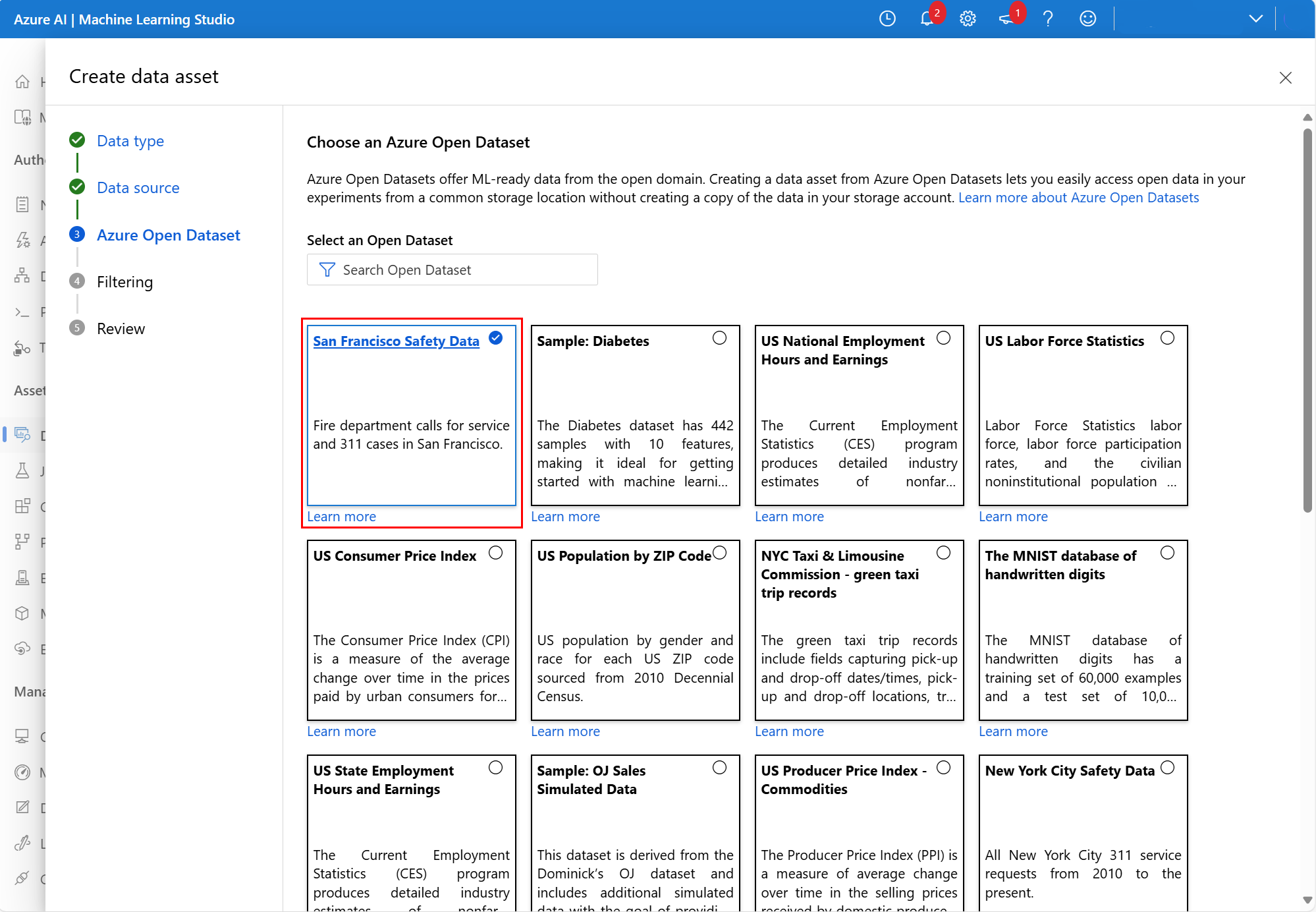
在下一个屏幕中,选择可用的 Azure 开放数据集。 在此屏幕截图中,我们选择了“旧金山安全数据”数据集:
如有必要,请向下滚动并选择“下一步”,如以下屏幕截图所示:

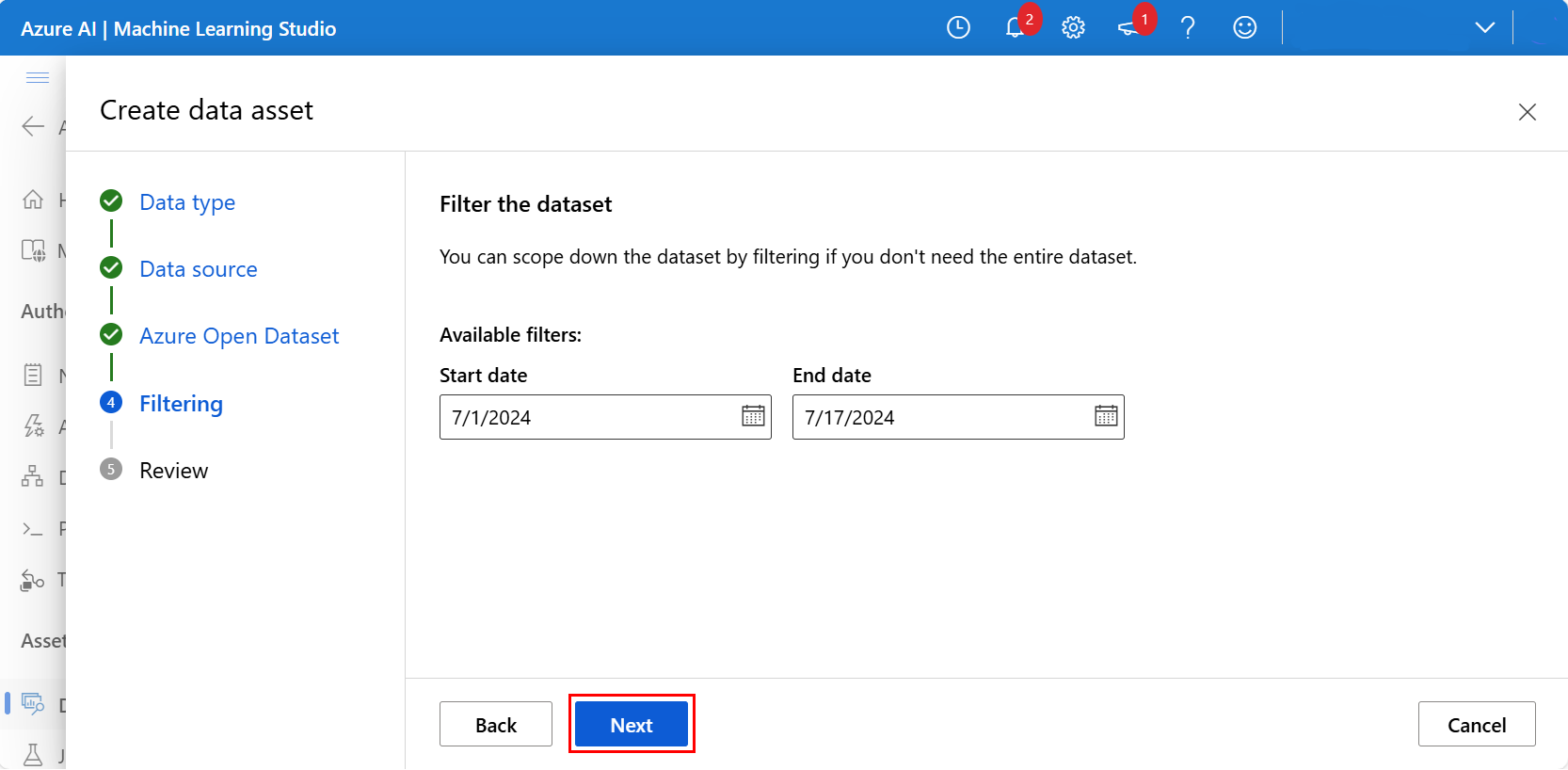
(可选)使用适用于所选数据集的可用筛选器筛选数据。 对于“旧金山安全数据”数据集,我们将筛选日期范围设置为开始日期“2024 年 7 月 1 日”、结束日期“2024 年 7 月 17 日”。 选择“下一步”,如以下屏幕截图所示:
在下一个屏幕中检查新数据资产的设置,并进行任何必要的更改。 如果设置合适,请选择“创建”,如以下屏幕截图所示:
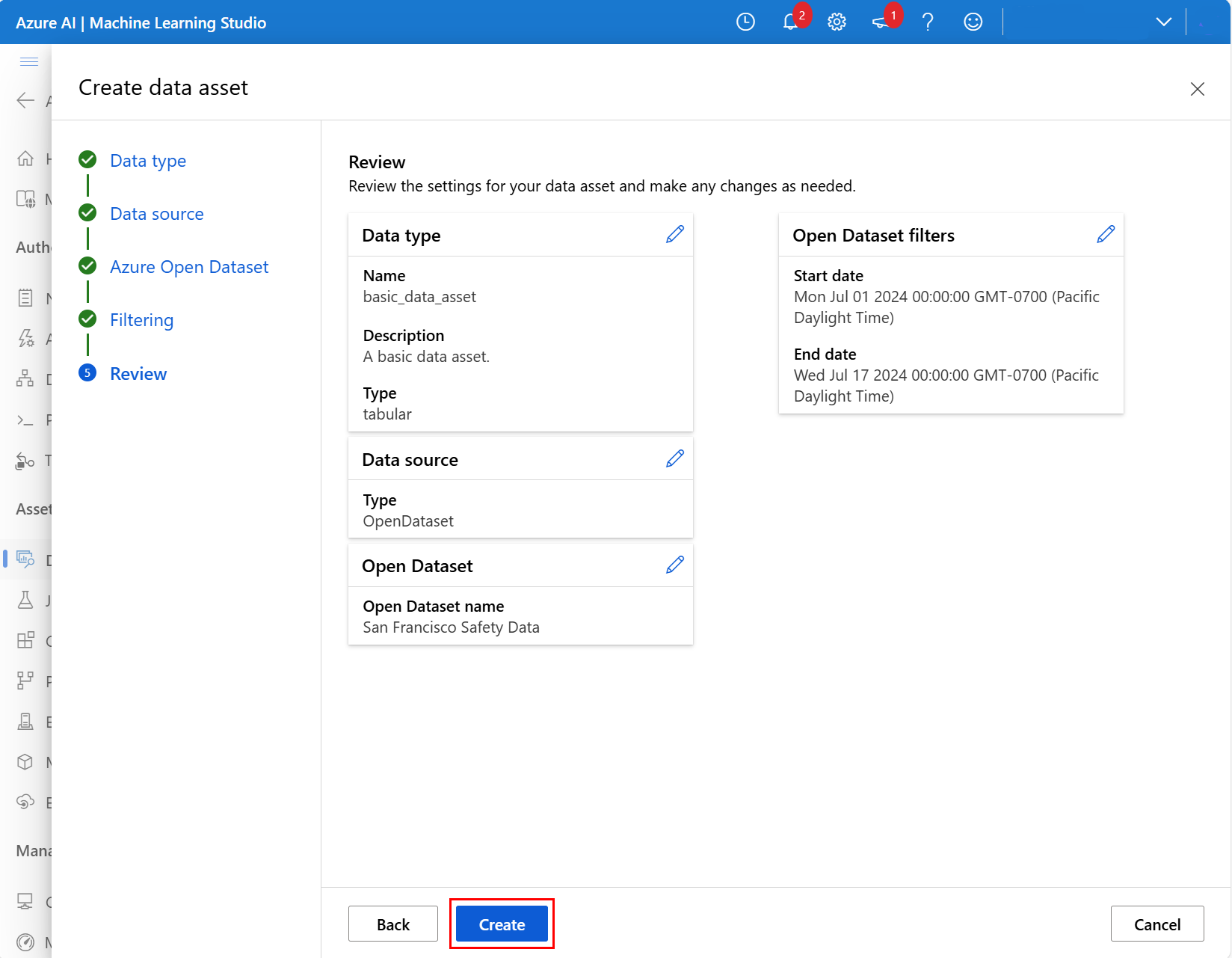
有关“旧金山安全数据”数据集的字段说明和日期范围的详细信息,请访问旧金山安全数据资源。 有关其他数据集的详细信息,请访问 Azure 开放数据集目录资源。







现在,该数据集已显示在工作区中的“数据集”下。 可以像使用创建的其他数据集一样来使用它。
访问供试验使用的数据集
在机器学习试验中使用数据集来训练 ML 模型。 有关详细信息,请访问详细了解如何使用数据集进行训练。
示例笔记本
有关开放数据集功能的示例和演示,请查看这些示例笔记本。