你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
采用高可用性和灾难恢复 (HADR) 配置的 IBM Db2 for Linux、UNIX 和 Windows (LUW) 包含一个运行主数据库实例的节点,以及至少一个运行辅助数据库实例的节点。 对主数据库实例进行的更改将以同步或异步方式复制到辅助数据库实例,具体取决于你的配置。
注意
本文包含对 Microsoft 不再使用的术语的引用。 当这些术语在软件中被删除后,我们会将它们从本文中删除。
本文介绍如何部署和配置 Azure 虚拟机 (VM) 、安装群集框架,以及安装具有 HADR 配置的 IBM Db2 LUW。
本文不介绍如何安装和配置具有 HADR 的 IBM Db2 LUW 或 SAP 软件安装。 为了帮助你完成这些任务,我们提供了对 SAP 和 IBM 安装手册的参考。 本文重点介绍特定于 Azure 环境的部件。
受支持的 IBM Db2 版本为 10.5 及更高版本,如 SAP 说明 1928533 中所述。
在开始安装之前,请参阅以下 SAP 说明和文档:
| SAP 说明 | 说明 |
|---|---|
| 1928533 | Azure 上的 SAP 应用程序:支持的产品和 Azure VM 类型 |
| 2015553 | Azure 上的 SAP:支持先决条件 |
| 2178632 | Azure 上的 SAP 的关键监视指标 |
| 2191498 | Azure 的 Linux 上的 SAP:增强型监视 |
| 2243692 | Azure (IaaS) VM 上的 Linux:SAP 许可证问题 |
| 2002167 | Red Hat Enterprise Linux 7.x:安装和升级 |
| 2694118 | Azure 上的 Red Hat Enterprise Linux HA 附加产品 |
| 1999351 | 适用于 SAP 的增强型 Azure 监视故障排除 |
| 2233094 | DB6:Azure 上使用 IBM DB2 for Linux、UNIX 和 Windows 的 SAP 应用程序 - 附加信息 |
| 1612105 | DB6:具有 HADR 的 Db2 的常见问题解答 |
| 文档 |
|---|
| SAP 社区 Wiki:包含适用于 Linux 的所有必需 SAP 说明 |
| 《针对 Linux 上的 SAP 的 Azure 虚拟机规划和实施》指南 |
| 适用于 Linux 上的 SAP 的 Azure 虚拟机部署(本文) |
| 《适用于 Linux 上的 SAP 的 Azure 虚拟机数据库管理系统 (DBMS) 部署》指南 |
| Azure 上的 SAP 工作负荷规划和部署清单 |
| Red Hat Enterprise Linux 7 的高可用性附加产品概述 |
| High Availability Add-On Administration(高可用性附加产品管理) |
| High Availability Add-On 参考 |
| Support Policies for RHEL High Availability Clusters - Microsoft Azure Virtual Machines as Cluster Members(RHEL 高可用性群集的支持策略 - Microsoft Azure 虚拟机作为群集成员) |
| Installing and Configuring a Red Hat Enterprise Linux 7.4 (and later) High-Availability Cluster on Microsoft Azure(在 Microsoft Azure 上安装和配置 Red Hat Enterprise Linux 7.4 [及更高版本] 高可用性群集) |
| 适用于 SAP 工作负荷的 IBM Db2 Azure 虚拟机 DBMS 部署 |
| IBM Db2 HADR 11.1 |
| IBM Db2 HADR 10.5 |
| RHEL 高可用性群集的支持策略 - 群集中的 IBM Db2 for Linux、Unix 和 Windows 管理 |
概述
为实现高可用性,至少在两台 Azure 虚拟机上安装具有 HADR 的 IBM Db2 LUW,这些虚拟机部署在跨可用性区域灵活编排的虚拟机规模集中或部署在可用性集中。
下图显示了两个数据库服务器 Azure VM 的设置。 两个数据库服务器 Azure VM 都附加了其自己的存储,并且已启动并运行。 在 HADR 中,其中一个 Azure VM 中的一个数据库实例具有主实例的角色。 所有客户端均连接到主实例。 数据库事务中的所有更改都将在 Db2 事务日志中本地保存。 由于事务日志记录在本地保存,将通过 TCP/IP 将记录传输到第二个数据库服务器、备用服务器或备用实例上的数据库实例。 备用实例通过前滚传输的事务日志记录来更新本地数据库。 通过这种方式,备用服务器与主服务器保持同步。
HADR 只是一种复制功能。 它没有故障检测,也没有自动接管或故障转移功能。 接管或传输到备用服务器时,必须由数据库管理员手动启动。 要实现自动接管和故障检测,可以使用 Linux Pacemaker 群集功能。 Pacemaker 监视两个数据库服务器实例。 当主数据库服务器实例发生故障时,Pacemaker 将通过备用服务器启动“自动”HADR 接管。 Pacemaker 还可确保将虚拟 IP 地址分配给新的主服务器。
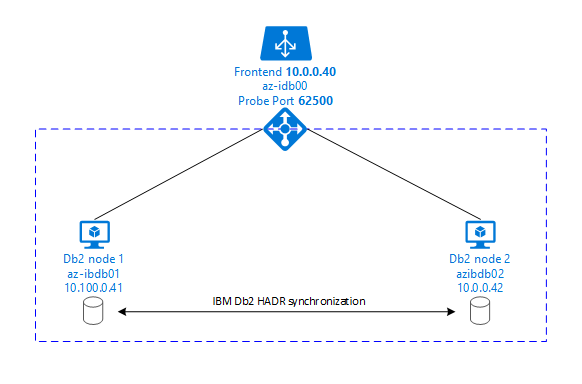
要让 SAP 应用程序服务器连接到主数据库,需要使用虚拟主机名和虚拟 IP 地址。 发生故障转移后,SAP 应用程序服务器会连接到新的主数据库实例。 在 Azure 环境中,需要 Azure 负载均衡器来使用虚拟 IP 地址,这与 IBM DB2 的 HADR 所需的方式相同。
为了帮助你充分了解具有 HADR 和 Pacemaker 的 IBM Db2 LUW 如何适应高度可用的 SAP 系统设置,下图概述了基于 IBM Db2 数据库的 SAP 系统的高可用性设置。 本文仅介绍 IBM Db2,但它提供了有关如何设置 SAP 系统其他组件的其他文章的参考。
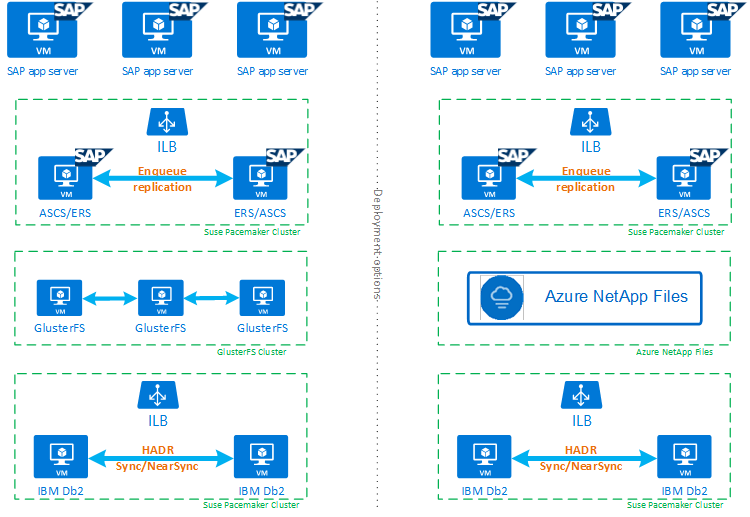
所需步骤的高级概述
要部署 IBM Db2 配置,需执行以下步骤:
- 计划环境。
- 部署 VM。
- 更新 SUSE Linux 并配置文件系统。
- 安装并配置 Pacemaker。
- 设置 glusterfs 群集或 Azure NetApp 文件
- 在单独的群集上安装 ASCS/ERS。
- 安装具有分布式/高可用性选项 (SWPM) 的 IBM Db2 数据库。
- 安装和创建辅助数据库节点和实例,并配置 HADR。
- 确认 HADR 是否正常工作。
- 应用 Pacemaker 配置以控制 IBM Db2。
- 配置 Azure 负载均衡器。
- 安装主应用程序服务器和对话应用程序服务器。
- 检查并改编 SAP 应用程序服务器的配置。
- 执行故障转移和接管测试。
计划用于托管具有 HADR 的 IBM Db2 LUW 的 Azure 基础结构
在执行部署之前完成规划过程。 规划为在 Azure 中部署具有 HADR 的 Db2 的配置奠定了基础。 下表列出了需要成为 IMB Db2 LUW 规划一部分(SAP 环境的数据库部分)的关键元素:
| 主题 | 简短说明 |
|---|---|
| 定义 Azure 资源组 | 部署 VM、虚拟网络、Azure 负载均衡器和其他资源的资源组。 可以是现有的,也可以是新的。 |
| 虚拟网络/子网定义 | 用于 IBM Db2 和 Azure 负载均衡器的 VM 的部署位置。 可以是现有的,也可以是新创建的。 |
| 托管 IBM Db2 LUW 的虚拟机 | VM 大小、存储、网络、IP 地址。 |
| IBM Db2 数据库的虚拟主机名和虚拟 IP | 用于连接 SAP 应用程序服务器的虚拟 IP 或主机名。 db-virt-hostname、db-virt-ip。 |
| Azure 隔离 | 避免出现拆分情况的方法。 |
| Azure 负载均衡器 | 使用适用于 Db2 数据库的标准(推荐)探测端口 probe-port(推荐使用 62500)。 |
| 名称解析 | 名称解析在环境中的工作方式。 强烈建议使用 DNS 服务。 可以使用本地主机文件。 |
有关 Azure 中 Linux Pacemaker 的详细信息,请参阅在 Azure 中的 SUSE Linux Enterprise Server 上设置 Pacemaker。
重要
对于 Db2 版本 11.5.6 及更高版本,强烈建议使用 IBM 中使用 Pacemaker 的集成解决方案。
在 Red Hat Enterprise Linux 上部署
Red Hat Enterprise Linux Server HA 附加产品中包含 IBM Db2 LUW 的资源代理。 对于本文档中所述的设置,应使用 Red Hat Enterprise Linux for SAP。 Azure 市场中包含 Red Hat Enterprise Linux 7.4 for SAP 或更高版本的映像,可以用于部署新的 Azure 虚拟机。 选择 Azure VM 市场中的 VM 映像时,请注意 Red Hat 通过 Azure 市场提供的各种支持或服务模型。
主机: DNS 更新
创建所有主机名(包括虚拟主机名)的列表,并更新 DNS 服务器,以便为主机名解析启用适当的 IP 地址。 如果 DNS 服务器不存在,或者无法更新和创建 DNS 条目,则需要使用参与此方案的各个 VM 的本地主机文件。 如果使用的是主机文件条目,请确保将条目应用到 SAP 系统环境中的所有 VM。 但是,建议使用 DNS,在理想情况下扩展到 Azure
手动部署
请确保用于 IBM Db2 LUW 的 IBM/SAP 支持所选操作系统。 SAP 说明 1928533 中提供了 Azure VM 和 Db2 版本支持的操作系统版本列表。 SAP 产品可用性对照表中提供了各个 Db2 版本的操作系统版本列表。 我们强烈建议至少为 Red Hat Enterprise Linux 7.4 for SAP,因为此版本或更高版本的 Red Hat Enterprise Linux 改进了与 Azure 相关的性能。
- 创建或选择资源组。
- 创建或选择虚拟网络和子网。
- 为 SAP 虚拟机选择合适的部署类型。 通常是采用灵活业务流程的虚拟机规模集。
- 创建虚拟机 1。
- 使用 Azure 市场中的 Red Hat Enterprise Linux for SAP 映像。
- 选择在步骤 3 中创建的规模集、可用性区域或可用性集。
- 创建虚拟机 2。
- 使用 Azure 市场中的 Red Hat Enterprise Linux for SAP 映像。
- 选择在步骤 3 中创建的规模集、可用性区域或可用性集(与步骤 4 中的区域不同)。
- 向 VM 中添加数据磁盘,然后在适用于 SAP 工作负荷的 IBM Db2 Azure 虚拟机 DBMS 部署一文中查看文件系统设置建议。
安装 IBM Db2 LUW 和 SAP 环境
在开始安装基于 IBM Db2 LUW 的 SAP 环境之前,请查看以下文档:
- Azure 文档。
- SAP 文档。
- IBM 文档。
本文的介绍部分提供了本文档的链接。
请查看有关在 IBM Db2 LUW 上安装基于 NetWeaver 的应用程序的 SAP 安装手册。 可以使用 SAP 安装指南查找器查找有关 SAP 帮助门户的指南。
通过设置以下筛选器可以减少门户中显示的指南数:
- 我想:安装新系统。
- 我的数据库:IBM DB2 for Linux、UNIX 和 Windows。
- SAP NetWeaver 版本、堆栈配置或操作系统的其他筛选器。
Red Hat 防火墙规则
默认情况下,Red Hat Enterprise Linux 已启用防火墙。
#Allow access to SWPM tool. Rule is not permanent.
sudo firewall-cmd --add-port=4237/tcp
设置具有 HADR 的 IBM Db2 LUW 的安装提示
要设置主 IBM Db2 LUW 数据库实例,请执行以下操作:
- 使用高可用性或分布式选项。
- 安装 SAP ASCS/ERS 和数据库实例。
- 对新安装的数据库进行备份。
重要
写下在安装过程中设置的“数据库通信端口”。 两个数据库实例的端口号必须相同。
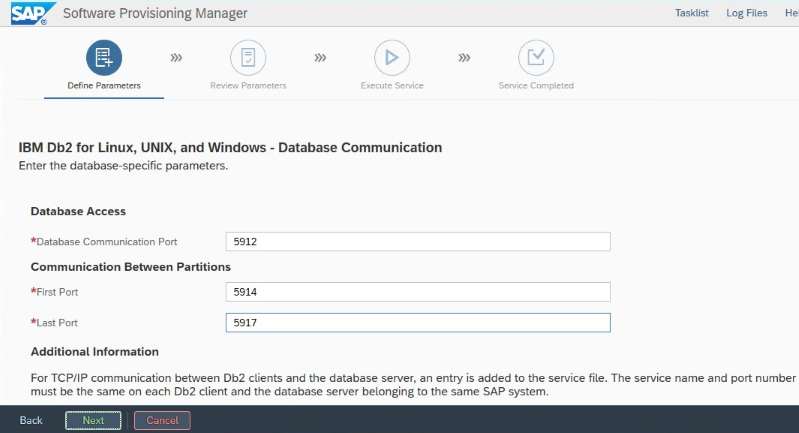
适用于 Azure 的 IBM Db2 HADR 设置
使用 Azure Pacemaker 隔离代理时,请设置以下参数:
- HADR 对等窗口持续时间(秒)(HADR_PEER_WINDOW) = 240
- HADR 超时值 (HADR_TIMEOUT) = 45
建议前面的参数基于初始故障转移/接管测试。 必须使用这些参数设置测试故障转移和接管功能是否正常。 由于各个配置可能会有所不同,因此参数可能需要调整。
注意
特定于通过正常启动的具有 HADR 的 IBM Db2 配置:辅助或备用数据库实例必须启动并运行,然后才能启动主数据库实例。
注意
对于特定于 Azure 和 Pacemaker 的安装和配置:在通过 SAP 软件预配管理器进行安装的过程中,有一个关于 IBM Db2 LUW 高可用性的明确问题:
- 请勿选择 IBM Db2 pureScale。
- 请勿选择“安装适用于多平台的 IBM Tivoli 系统自动化”。
- 请勿选择“生成群集配置文件”。
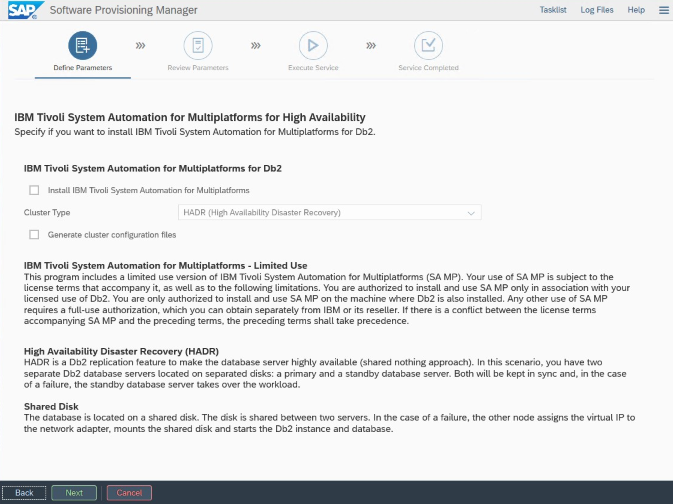
要使用 SAP 同类系统复制过程来设置备用数据库服务器,请执行以下步骤:
- 选择“系统复制”选项 >“目标系统”>“分布式”>“数据库实例”。
- 作为一种复制方法,选择“同类系统”,以便可以使用备份在备用服务器实例上还原备份。
- 到达为同类系统副本还原数据库的退出步骤时,请退出安装程序。 从主主机的备份中还原数据库。 所有后续安装阶段都已在主数据库服务器上执行。
适用于 DB2 HADR 的 Red Hat 防火墙规则
添加防火墙规则以允许流向 DB2 和 DB2 之间的流量,使 HADR 正常工作:
- 数据库通信端口。 如果使用分区,则也要添加这些端口。
- HADR 端口(DB2 参数 HADR_LOCAL_SVC 的值)。
- Azure 探测端口。
sudo firewall-cmd --add-port=<port>/tcp --permanent
sudo firewall-cmd --reload
IBM Db2 HADR 检查
为了便于演示以及用于本文中所述的过程,数据库 SID 为 ID2。
配置 HADR 并且主节点和备用节点上的状态为 PEER 和 CONNECTED 后,请执行以下检查:
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
Database Member 0 -- Database ID2 -- Active -- Up 1 days 15:45:23 -- Date 2019-06-25-10.55.25.349375
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.076494 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 5
HEARTBEAT_EXPECTED = 52
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 5
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 369280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 132242668
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 300
PEER_WINDOW_END = 06/25/2019 11:12:03.000000 (1561461123)
READS_ON_STANDBY_ENABLED = N
#Secondary output:
Database Member 0 -- Database ID2 -- Standby -- Up 1 days 15:45:18 -- Date 2019-06-25-10.56.19.820474
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.078116 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 10
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 367360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 1000
PEER_WINDOW_END = 06/25/2019 11:12:59.000000 (1561461179)
READS_ON_STANDBY_ENABLED = N
配置 Azure 负载均衡器
在配置 VM 期间,你可以在网络部分中创建或选择现有的负载均衡器。 按照以下步骤设置标准负载均衡器以完成 DB2 数据库的高可用性设置。
按照创建负载均衡器中的步骤,使用 Azure 门户为高可用性 SAP 系统设置标准负载均衡器。 在设置负载均衡器期间,请注意以下几点:
- 前端 IP 配置:创建前端 IP。 选择与数据库虚拟机相同的虚拟网络和子网名称。
- 后端池:创建后端池并添加数据库 VM。
- 入站规则:创建负载均衡规则。 对两个负载均衡规则执行相同步骤。
- 前端 IP 地址:选择前端 IP。
- 后端池:选择后端池。
- 高可用性端口:选择此选项。
- 协议:选择“TCP”。
- 运行状况探测:创建具有以下详细信息的运行状况探测:
- 协议:选择“TCP”。
- 端口:例如 625<instance-no.>。
- 间隔时间:输入 5。
- 探测阈值:输入 2。
- 空闲超时(分钟):输入 30。
- 启用浮动 IP:选择此选项。
注意
不会遵循运行状况探测配置属性 numberOfProbes(在门户中也称为“运行不正常阈值”)。 若要控制成功或失败的连续探测的数量,请将属性 probeThreshold 设置为 2。 当前无法使用 Azure 门户设置此属性,因此请使用 Azure CLI 或 PowerShell 命令。
注意
如果没有公共 IP 地址的 VM 放在标准 Azure 负载均衡器的内部(无公共 IP 地址)实例的后端池中,除非执行更多的配置以允许路由到公共终结点,否则就没有出站 Internet 连接。 有关如何实现出站连接的详细信息,请参阅 SAP 高可用性方案中使用 Azure 标准负载均衡器的 VM 的公共终结点连接。
重要
请勿在放置于 Azure 负载均衡器之后的 Azure VM 上启用 TCP 时间戳。 启用 TCP 时间戳会导致运行状况探测失败。 将参数 net.ipv4.tcp_timestamps 设置为 0。 有关详细信息,请参阅负载均衡器运行状况探测。
[A] 为探测端口添加防火墙规则:
sudo firewall-cmd --add-port=<probe-port>/tcp --permanent
sudo firewall-cmd --reload
创建 Pacemaker 群集
要为此 BM Db2 服务器创建基本 Pacemaker 群集,请参阅在 Azure 中的 SUSE Linux Enterprise Server 上设置 Pacemaker。
Db2 Pacemaker 配置
如果在发生节点故障时使用 Pacemaker 进行自动故障转移,则需要相应地配置 Db2 实例和 Pacemaker。 本部分介绍此类型的配置。
以下各项带有任一前缀:
- [A] :适用于所有节点
- [1] :仅适用于节点 1
- [2] :仅适用于节点 2
[A] Pacemaker 配置的先决条件:
以用户 db2<sid> 身份通过 db2stop 关闭两个数据库服务器。
将 db2<sid> 用户的 shell 环境更改为 /bin/ksh:
# Install korn shell: sudo yum install ksh # Change users shell: sudo usermod -s /bin/ksh db2<sid>
Pacemaker 配置
[1] IBM Db2 HADR 特定的 Pacemaker 配置:
# Put Pacemaker into maintenance mode sudo pcs property set maintenance-mode=true[1] 创建 IBM Db2 资源:
如果在 RHEL 7.x 上生成群集,请确保将 resource-agents 包更新到
resource-agents-4.1.1-61.el7_9.15或更高版本。 使用以下命令创建群集资源:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' master meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resource sudo pcs resource update Db2_HADR_ID2-master meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-master #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-master then g_ipnc_db2id2_ID2如果在 RHEL 8.x 上生成群集,请确保将 resource-agents 包更新到
resource-agents-4.1.1-93.el8或更高版本。 有关详细信息,请参阅 Red Hat KB:具有 HADR 的资源db2升级失败,状态为PRIMARY/REMOTE_CATCHUP_PENDING/CONNECTED。 使用以下命令创建群集资源:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' promotable meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resource sudo pcs resource update Db2_HADR_ID2-clone meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-clone #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-clone then g_ipnc_db2id2_ID2[1] 启动 IBM Db2 资源:
将 Pacemaker 退出维护模式。
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo pcs property set maintenance-mode=false[1] 确保群集状态正常,并且所有资源都已启动。 资源在哪个节点上运行并不重要。
sudo pcs status 2 nodes configured 5 resources configured Online: [ az-idb01 az-idb02 ] Full list of resources: rsc_st_azure (stonith:fence_azure_arm): Started az-idb01 Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2] Masters: [ az-idb01 ] Slaves: [ az-idb02 ] Resource Group: g_ipnc_db2id2_ID2 vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01 nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
重要
必须使用 Pacemaker 工具管理 Pacemaker 群集 Db2 实例。 如果使用 db2 命令(如 db2stop),则 Pacemaker 会将操作检测为资源故障。 如果要执行维护,可以将节点或资源置于维护模式。 Pacemaker 暂停监视资源,然后你可以使用普通的 db2 管理命令。
对 SAP 配置文件进行更改,以使用虚拟 IP 进行连接
要连接到 HADR 配置的主实例,SAP 应用程序层需要使用为 Azure 负载均衡器定义和配置的虚拟 IP 地址。 需要进行以下更改:
/sapmnt/<SID>/profile/DEFAULT.PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/<SID>/global/db6/db2cli.ini
Hostname=db-virt-hostname
安装主应用程序服务器和对话应用程序服务器
在针对 Db2 HADR 配置安装主应用程序服务器和对话应用程序服务器时,请使用为配置选取的虚拟主机名。
如果在创建 Db2 HADR 配置之前执行了安装,请按照上一节中所述进行更改,并遵循 SAP Java 堆栈。
ABAP+Java 或 Java 堆栈系统 JDBC URL 检查
使用 J2EE Config 工具检查或更新 JDBC URL。 由于 J2EE Config 工具是图形工具,因此需要安装 X 服务器:
登录到 J2EE 实例的主应用程序服务器并执行以下命令:
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.sh在左框架中,选择“安全性存储”。
在右框架中,选择密钥
jdbc/pool/\<SAPSID>/url。将 JDBC URL 中的主机名更改为虚拟主机名。
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0选择 添加 。
要保存所做的更改,请在左上角选择磁盘图标。
关闭配置工具。
重启 Java 实例。
配置 HADR 设置的日志存档
要为 HADR 设置配置 Db2 日志存档,建议将主数据库和备用数据库都配置为从所有日志存档位置自动检索日志。 主数据库和备用数据库都必须能够从其中一个数据库实例可能将日志文件存档到的所有日志存档位置检索日志存档文件。
日志存档仅由主数据库中执行。 如果更改数据库服务器的 HADR 角色或发生故障,则新的主数据库将负责日志存档。 如果已设置多个日志存档位置,则日志可能会存档两次。 对于本地或远程捕获,可能还必须手动将存档的日志从旧的主服务器复制到新的主服务器的活动日志位置。
建议配置一个公共 NFS 共享或 GlusterFS,其中日志从两个节点写入。 NFS 共享或 GlusterFS 必须高度可用。
可以将现有的高可用 NFS 共享或 GlusterFS 用于传输或配置文件目录。 有关详细信息,请参阅:
- 适用于 SAP NetWeaver 的 Red Hat Enterprise Linux 上的 Azure VM 上的 GlusterFS。
- 使用适用于 SAP 应用程序的 Azure NetApp 文件实现 Red Hat Enterprise Linux 的 Azure VM 上的 SAP NetWeaver 高可用性。
- Azure NetApp 文件(用于创建 NFS 共享)。
测试群集设
本部分介绍如何测试 Db2 HADR 设置。 每个测试都假设 IBM Db2 主副本正在 az-idb01 虚拟机上运行。 必须使用具有 sudo 特权的用户或 root(不建议)用户。
所有测试用例的初始状态如下所述:(crm_mon -r 或 pcs status)
- “pcs status”是在执行时 Pacemaker 状态的快照。
- “crm_mon-r”是 Pacemaker 状态的连续输出。
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
SAP 系统中的原始状态记录在“事务 DBACOCKPIT”>“配置”>“概述”中,如下图所示:
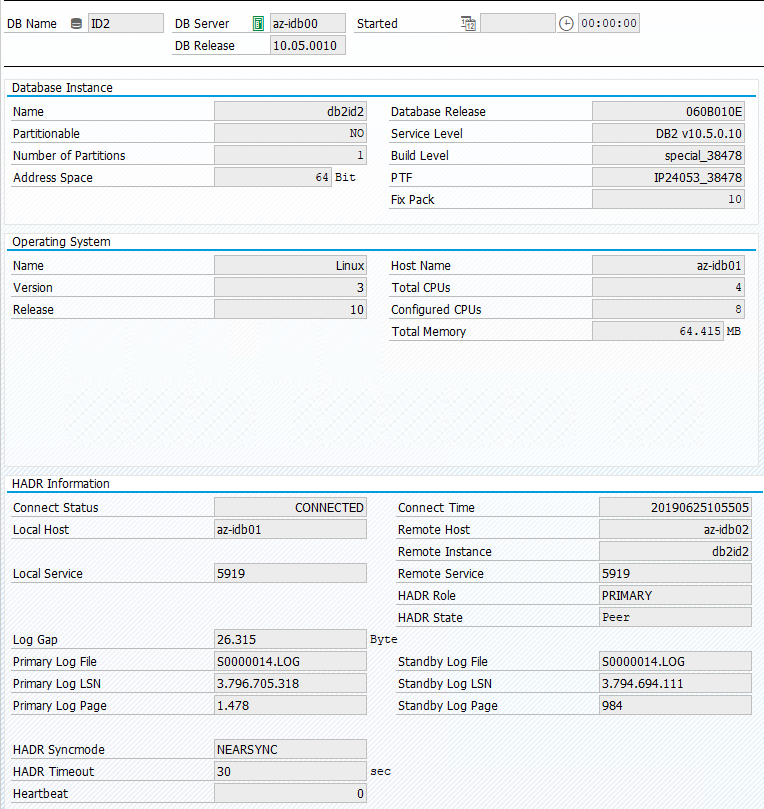
测试 IBM Db2 的接管
重要
在开始测试前,请确保:
Pacemaker 没有任何失败的操作 (pcs status)。
没有位置约束(迁移测试的 leftovers)。
IBM Db2 HADR 同步正在运行。 以用户 db2sid 身份进行检查<>。
db2pd -hadr -db <DBSID>
通过执行以下命令迁移运行主 Db2 数据库的节点:
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
完成迁移后,crm status 输出如下所示:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
SAP 系统中的原始状态记录在“事务 DBACOCKPIT”>“配置”>“概述”中,如下图所示:
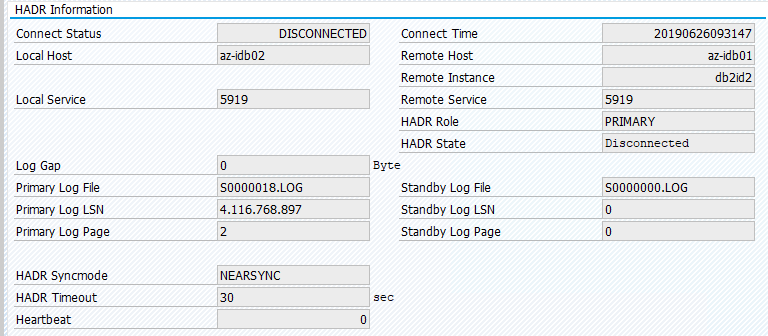
使用“pcs resource move”的资源迁移创建位置约束。 在这种情况下,位置约束阻止在 az-idb01 上运行 IBM Db2 实例。 如果不删除位置约束,则资源无法进行故障回复。
移除位置约束,将在 az-idb01 上启动备用节点。
# On RHEL 7.x
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource clear Db2_HADR_ID2-clone
并且群集状态更改为:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
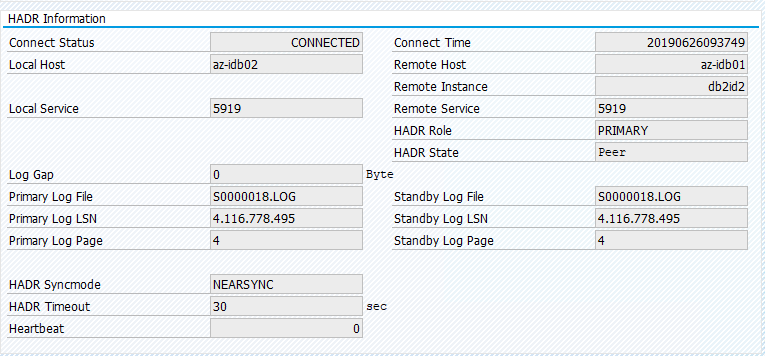
将资源迁移回“az-idb01”,并清除位置约束
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master az-idb01
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
sudo pcs resource clear Db2_HADR_ID2-clone
- 在 RHEL 7.x 上 -
pcs resource move <resource_name> <host>:创建位置约束并可能导致出现接管问题 - 在 RHEL 8.x 上 -
pcs resource move <resource_name> --master:创建位置约束并可能导致出现接管问题 pcs resource clear <resource_name>:清除位置约束pcs resource cleanup <resource_name>:清除资源的所有错误
测试手动接管
可以通过停止节点“az-idb01”上的 Pacemaker 服务来测试手动接管:
systemctl stop pacemaker
“az-ibdb02”上的状态
2 nodes configured
5 resources configured
Node az-idb01: pending
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
故障转移后,可以在“az-idb01”上再次启动该服务。
systemctl start pacemaker
终止运行 HADR 主数据库的节点上的 Db2 进程
#Kill main db2 process - db2sysc
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 34598
Db2 实例将失败,Pacemaker 将移动主节点报告以下状态:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=49, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 09:57:35 2019', queued=0ms, exec=362ms
Pacemaker 在同一节点上重启 Db2 主数据库实例,或将故障转移到运行辅助数据库实例的节点,并报告错误。
终止运行辅助数据库实例的节点上的 Db2 进程
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2id2 23144 23142 2 09:53 ? 00:00:13 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 23144
节点进入故障状态,并报告错误。
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Failed Actions:
* Db2_HADR_ID2_monitor_20000 on az-idb02 'not running' (7): call=144, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 10:02:09 2019', queued=0ms, exec=0ms
Db2 实例将在之前分配的辅助角色中重启。
在运行 HADR 主数据库实例的节点上通过 db2stop force 停止 DB
以用户 db2<sid> 身份执行命令 db2stop force:
az-idb01:db2ptr> db2stop force
检测到故障:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Slaves: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Stopped
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Stopped
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Db2 HADR 辅助数据库实例已提升为主角色。
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
使用“halt”运行 HADR 主数据库实例的 VM 出现故障
#Linux kernel panic.
sudo echo b > /proc/sysrq-trigger
在这种情况下,Pacemaker 会检测到运行主数据库实例的节点没有响应。
2 nodes configured
5 resources configured
Node az-idb01: UNCLEAN (online)
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
下一步是检查“拆分”情况。 在幸存节点确定最后运行主数据库实例的节点出现故障后,将执行资源的故障转移。
2 nodes configured
5 resources configured
Online: [ az-idb02 ]
OFFLINE: [ az-idb01 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
发生内核崩溃时,故障节点将通过隔离代理重启。 故障节点重新联机后,必须通过以下命令启动 pacemaker 群集
sudo pcs cluster start
它将 Db2 实例启动到辅助角色。
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02