你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
分面导航用于在搜索应用中对查询结果进行自我定向筛选,其中应用程序提供表单控件,用于将搜索范围限定为文档组(例如类别或品牌),Azure AI 搜索提供了支持体验的数据结构和筛选器。
本文介绍在 Azure AI 搜索中返回分面导航结构的步骤。 熟悉基本概念和客户端后,请继续阅读分面示例了解各种用例的语法,包括基本分面和唯一计数。
可通过预览 API 获取更多分面功能:
- 分层分面结构
- 分面筛选
- 分面聚合
分面导航示例提供预览功能的语法和用法。
搜索页面中的分面导航
分面是动态的,因为它们基于每个特定的查询结果集。 搜索响应包含用于在结果中导航文档的所有分面存储桶。 首先执行查询,然后从当前结果拉取分面,并组合成分面导航结构。
在 Azure AI 搜索中,分面深度为一层,除非使用预览 API,否则无法分层。 如果你不熟悉分面导航结构,以下示例左侧显示的就是一个分面导航。 计数指示每个分面的匹配项数。 同一文档可以以不同方面表示。
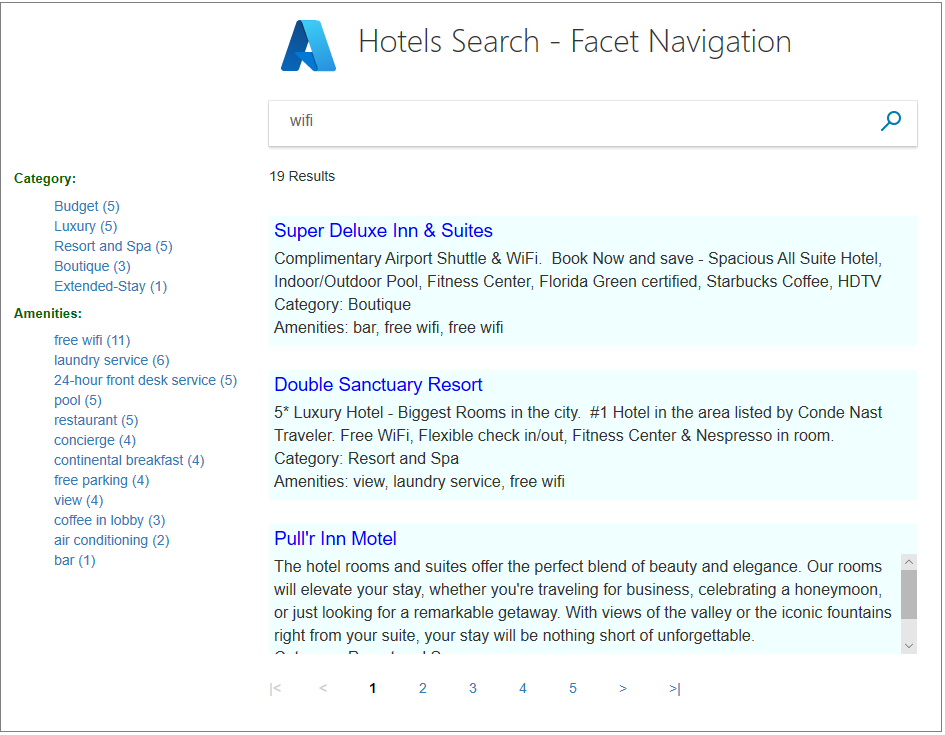
分面可帮助你查找所需的内容,同时确保获取相关结果。 作为开发人员,分面允许公开用于导航搜索索引的最有用的搜索条件。
代码中的分面导航
在索引中支持的字段上启用分面,然后在查询上指定。 响应的开头返回分面导航结构,然后是结果。
以下 REST 示例是一个空查询("search": "*"),该查询的范围限定为整个索引(请参阅 内置酒店示例)。 参数 facets 指定“Category”字段。
POST https://{{service_name}}.search.windows.net/indexes/hotels/docs/search?api-version={{api_version}}
{
"search": "*",
"queryType": "simple",
"select": "",
"searchFields": "",
"filter": "",
"facets": [ "Category"],
"orderby": "",
"count": true
}
示例的响应以分面导航结构开头。 该结构由“Category”值和每个值的 hotel 计数组成。 接下来是其余的搜索结果,为了简洁起见,这里将其精简为仅一个文档。 此示例运行效果良好有多种原因。 此字段的分面数未超过限制(默认值为 10),因此所有分面都得以显示,并且 50 个 hotel 索引中的每个 hotel 都只以其中一个类别表示。
{
"@odata.context": "https://demo-search-svc.search.windows.net/indexes('hotels')/$metadata#docs(*)",
"@odata.count": 50,
"@search.facets": {
"Category": [
{
"count": 13,
"value": "Budget"
},
{
"count": 12,
"value": "Resort and Spa"
},
{
"count": 9,
"value": "Luxury"
},
{
"count": 7,
"value": "Boutique"
},
{
"count": 5,
"value": "Suite"
},
{
"count": 4,
"value": "Extended-Stay"
}
]
},
"value": [
{
"@search.score": 1.0,
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Category": "Boutique",
"Tags": [
"pool",
"air conditioning",
"concierge"
],
"ParkingIncluded": false,
},
. . .
]
}
在字段上启用分面
可以向包含纯文本或数字内容的新字段添加分面。 支持的数据类型包括字符串、日期、布尔字段和数值字段(但不包括向量)。
可以使用 Azure 门户、REST API、Azure SDK 或任何支持在 Azure AI 搜索中创建或更新索引架构的方法。 第一步,确定用于分面的字段。
选择要分配属性的字段
可通过单值字段和集合计算分面。 最适用于分面导航的字段具有以下特征:
- 人类可读(非矢量)内容。
- 低基数(在搜索语料库的整个文档中重复的少量不同值)。
- 简短的描述性值(一两个单词),可以在导航树中清晰显示。
字段中的值(而非字段名称本身)将生成分面导航结构中的分面。 如果该分面是一个名为“Color”的字符串字段,则分面是“blue”、“green”和该字段的其他任何值。 查看字段值以确保没有拼写错误、null 或大小写差异。 请考虑为“filterable”和“facetable”字段分配规范器,以消除文本中的细小变化。 例如,“Canada”、“CANADA”和“canada”将全部规范化为一个存储桶。
避免不受支持的字段
不能在现有字段、矢量字段或类型为Edm.GeographyPoint或Collection(Edm.GeographyPoint)的字段上设置分面。
在复杂字段集合上,“facetable”必须为空值。
从新的字段定义开始
仅当创建字段时,才能设置影响字段索引方式的属性。 此限制适用于分面和筛选器。
如果索引已存在,可以添加提供分面的新字段定义。 索引中的现有文档在新字段中获得空值。 下次 刷新索引时,将替换此 null 值。
在 Azure 门户的搜索服务页中,转到索引的 “字段 ”选项卡,然后选择“ 添加”字段。
提供名称、数据类型和属性。 建议添加“filterable”,因为通常基于响应中的某个分面存储桶来设置。 建议进行排序,因为筛选器生成无序结果,你可能希望在应用程序中对其进行排序。
如果还希望支持字段的全文搜索,可以设置为可搜索;如果想在搜索响应中包含该字段,可以设置为可检索。
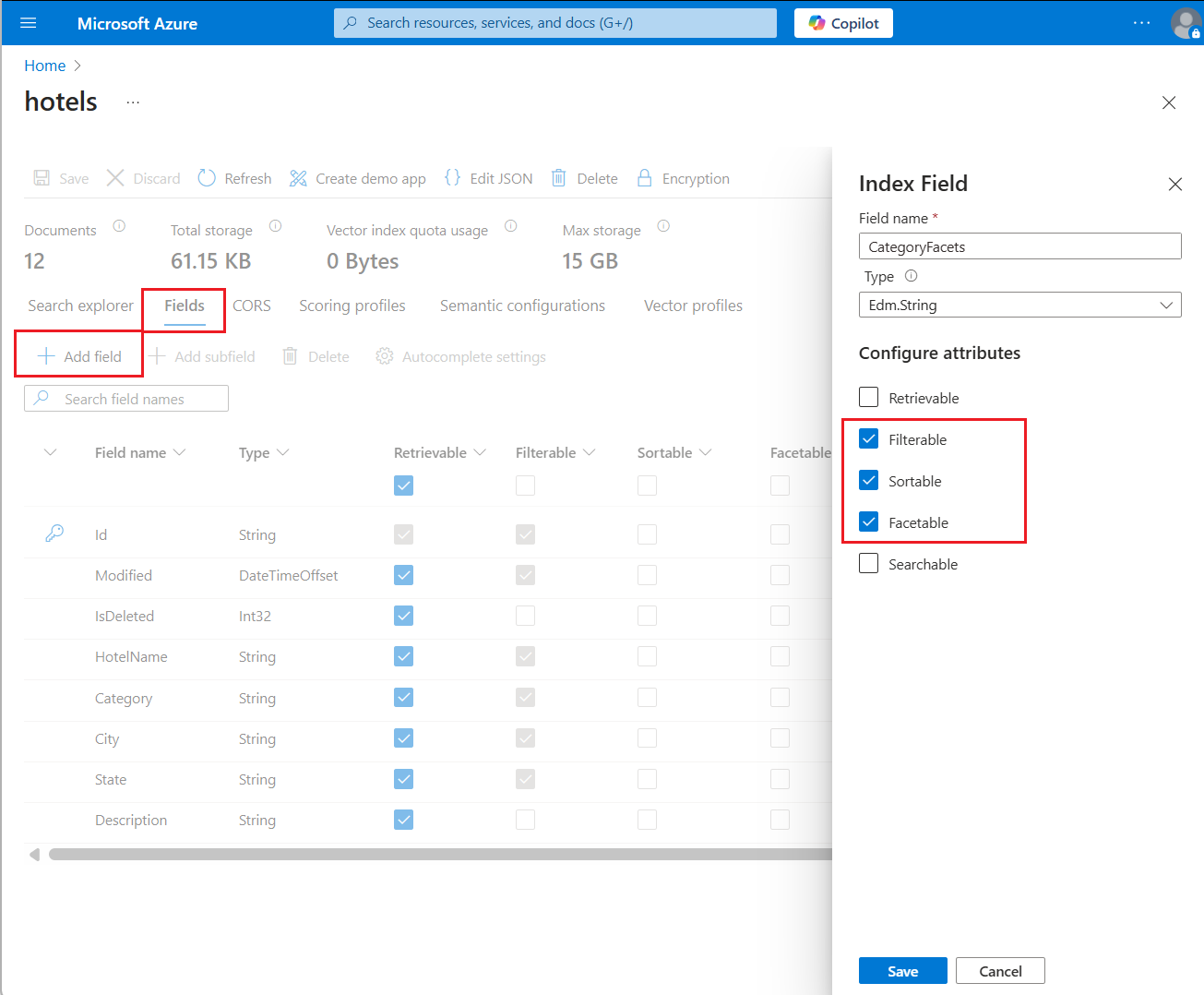
保存字段定义。

返回查询中的分面
回想一下,分面是从查询响应中的结果动态计算出来的。 仅将获取当前查询找到的文档的分面。
使用搜索资源管理器中的 JSON 视图在 Azure 门户中设置分面参数。
- 选择索引并在 JSON 视图中打开搜索资源管理器。
- 在 JSON 中提供查询。 你可以键入它,从 REST 示例复制 JSON,或使用 IntelliSense 帮助完成语法。 有关分面表达式的引用,请参阅下一个选项卡中的 REST 示例。
- 选择 “搜索 ”以返回分面结果,以 JSON 形式显示。
这是酒店示例索引中的基本分面查询示例的屏幕截图。 可以粘贴本文中的其他示例,以在搜索资源管理器中返回结果。

使用分面的最佳做法
本部分是有助于应用程序开发的提示和解决方法的集合。
建议 C#: 向 Web 应用添加搜索功能,这是一种包括表示层代码的分面导航示例。 此示例还包括筛选器、建议和自动完成。 它对呈现层使用 JavaScript 和 React。
使用非限定或空搜索字符串初始化分面导航结构
使用开放查询 ("search": "*") 初始化搜索页以完全填充分面导航结构,这一方法非常有用。 在请求中传递查询词后,分面导航结构的范围仅限定为结果中的匹配项,而不是整个索引。 这种做法有助于在测试流程中验证分面和筛选行为。 如果在查询中包含匹配条件,响应将排除不匹配的文档,这可能会对后续步骤产生排除分面的潜在影响。
清除分面
设计该用户体验时,请记住添加用于清除分面的机制。 清除分面的常见方法是发起一个开放查询以重置页面。
禁用分面功能以节省存储空间,并提高性能。
对于性能和存储优化,请为不应用作分面的字段设置 "facetable": false。 示例包括用于唯一值的字符串字段(如 ID 或产品名称),以防止其在分面导航中被意外(且无效)使用。 此最佳做法对于 REST API 尤其重要,该 API 默认启用字符串字段上的筛选器和分面。
请记住,无法在分面导航中使用 Edm.GeographyPoint 或 Collection(Edm.GeographyPoint) 字段。 回想一下,分面最适合用于基数较小的字段。 由于地理坐标的解析方式,在给定的数据集中,任何两组坐标相等的情况都很少见。 因此,地理坐标不支持分面。 应使用城市或区域字段来按位置进行分面。
检查错误数据
准备用于编制索引的数据时,请检查空值、拼写错误或大小写差异的字段,以及同一单词的单个和复数版本。 默认情况下,筛选器和分面不进行词法分析或拼写检查,这意味着“facetable”字段的所有值都可能生成分面,即使这些单词只相差一个字符。
规范化器可以缓解数据差异,纠正大小写和字符差异。 否则,若要检查数据,可以在其源处检查字段,或运行从索引返回值的查询。
索引不是修复 null 值或无效值的最佳位置。 应修复源中的数据问题,假设它是数据库或持久性存储,或在编制索引之前执行的数据清理步骤中。
对分面存储桶进行排序
虽然可以在一个存储桶内进行排序,但在整体导航结构中,没有用于控制分面存储桶顺序的参数。 如果希望分面桶按特定顺序排列,则必须在应用程序代码中实现。
分面计数中的差异
在某些情况下,你可能会发现由于分片体系结构,分面计数并不完全准确。 每个搜索索引都分布在多个分片上,每个分片报告文档数量最多的前 N 个分面,然后将这些分面合并为一个结果。 因为这只是每个分片的前 N 个分面,所以可能会在分面响应中遗漏或少计匹配的文档。
为保证准确性,可以人为地将 count:<number> 增加到一个较大的数字,用于强制从每个分片进行完整报告。 可以为无限分面指定 "count": "0"。 或者,可以将“count”设置为大于或等于分面字段的唯一值数的值。 例如,如果按具有五个唯一值的“size”字段进行分面,则可以设置 "count:5" 以确保分面响应表示所有匹配项。
此解决方法的缺点会增加查询延迟,因此仅在必要时才使用这种方法。
以异步方式保留筛选结果的分面导航结构
在 Azure AI 搜索中,只有当前结果存在分面。 但是,一项常见的应用程序要求是保留一组静态分面,便于用户按相反顺序进行导航,回顾步骤以通过搜索内容了解可选路径。
如果您希望在动态钻取体验的同时拥有一组静态分面,可以通过使用两个筛选查询来实现:一个查询针对结果进行限定,另一个则用于创建一个静态的分面列表,以便于导航。
通过筛选器偏移较大的分面计数
太大的搜索结果和分面结果可以通过添加筛选器来精简。 在以下示例中,在 云计算的查询中,254 个项目具有 内部规范 作为内容类型。 如果结果太大,添加筛选器可帮助用户通过添加更多条件来优化查询。
项目之间并不相互排斥。 如果某个项满足这两个筛选条件,它将分别计入每一个。 针对通常用于实现记录标记的 Collection(Edm.String) 字段进行分面时,可能会出现这种重复。
Search term: "cloud computing"
Content type
Internal specification (254)
Video (10)