你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
对于每个矢量字段,Azure AI 搜索使用字段上指定的算法参数构造内部矢量索引。 由于 Azure AI 搜索对矢量索引大小施加了配额,因此你应了解如何估算和监视矢量大小,以确保持在限制范围内。
注意
关于术语的说明。 在内部,搜索索引的物理数据结构包括原始内容(用于需要非标记化内容的检索模式)、倒排索引(用于可搜索文本字段)和矢量索引(用于可搜索的矢量字段)。 本文介绍对支持每个矢量字段的内部矢量索引的限制。
提示
矢量优化技术现已正式发布。 使用窄数据类型、标量和二进制量化和消除冗余存储等功能,以保持在矢量配额和存储配额之下。
有关配额和矢量索引大小的要点
矢量索引大小以字节为单位。
矢量配额基于内存约束。 对于使用分层可导航小世界 (HNSW) 算法创建的矢量索引,可搜索矢量索引驻留在内存中。 同时,还必须有足够的内存用于其他运行时操作。 存在矢量配额是为了确保整个系统对所有工作负载保持稳定和均衡。 如果使用穷举 KNN 算法,则索引仅在查询时加载到内存中。
矢量索引也受磁盘配额的约束,从某种意义上说,所有索引都受磁盘配额的约束。 矢量索引没有单独的磁盘配额。
在整个搜索服务上按分区强制实施向量配额,这意味着,如果添加分区,矢量配额会上升。 较新的服务上的每分区向量配额更高。 有关详细信息,请参阅矢量索引大小限制。
如何检查分区大小和数量
如果不确定你的搜索服务的限制,可通过以下两种方法获取该信息:
在 Azure 门户中的搜索服务“概览”页中,“属性”选项卡和“使用情况”选项卡显示了分区大小和存储,以及矢量配额和矢量索引大小。
在 Azure 门户中的“缩放”页中,可以查看分区的数量和大小。
如何检查服务创建日期
与较旧的服务相比,在相同的层计费费率下,2024 年 4 月 3 日之后创建的较新的服务提供 5 到 10 倍的矢量存储。 如果你的服务较旧,请考虑创建新服务并迁移内容。
在 Azure 门户中,打开包含你的搜索服务的资源组。
在最左侧的窗格中的“设置”下,选择“部署”。
找到搜索服务部署。 如果有许多部署,请使用筛选器查找“搜索”。
选择部署。 如果有多个,请单击以查看它是否解析为搜索服务。
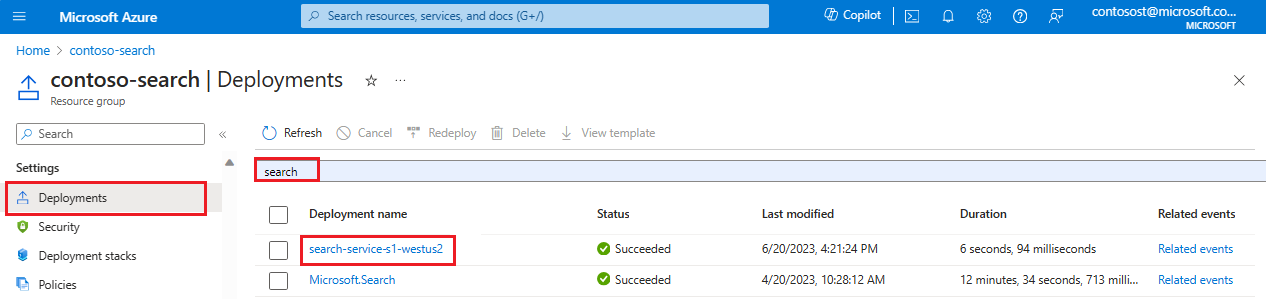
展开部署详细信息。 应会看到“已创建”和创建日期。
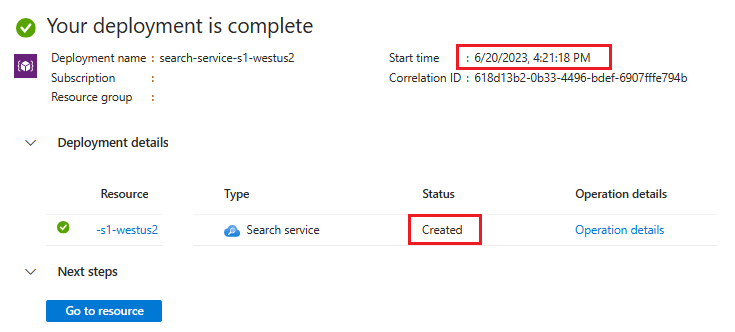
了解搜索服务的年限后,请根据服务创建查看矢量配额限制:矢量索引大小限制。


如何获取矢量索引大小
请求矢量指标是数据平面操作。 可以使用 Azure 门户、REST API 或 Azure SDK 通过服务统计信息和单个索引在服务级别获取矢量使用情况。
每个索引的矢量大小
若要获取每个索引的矢量索引大小,请选择“搜索管理”>“索引”,查看索引列表和文档计数、内存中矢量索引的大小以及磁盘上存储的总索引大小。
回想一下,矢量配额基于内存约束。 对于使用 HNSW 算法创建的矢量索引,所有可搜索矢量索引都会永久加载到内存中。 对于使用穷举 KNN 算法创建的索引,矢量索引在查询期间按顺序以区块方式加载。 对于穷举 KNN 索引,没有内存驻留要求。 已加载到内存中的页面的生存期类似于文本搜索,对于穷举 KNN 索引,除了总存储外,没有其他指标适用。
以下屏幕截图显示了同一矢量索引的两个版本。 一个版本是使用 HNSW 算法创建的,其中矢量图驻留在内存中。 另一个版本是使用穷举 KNN 算法创建的。 使用穷举 KNN 时,没有专门的内存中矢量索引,因此门户显示矢量索引大小为 0 MB。 这些矢量仍存在并按总体存储大小进行计数,但它们不占用矢量索引大小指标跟踪的内存中资源。

每个服务的矢量大小
若要获取整个搜索服务的矢量索引大小,请选择“概述”页的“使用情况”选项卡。门户页面每隔几分钟会刷新一次,因此,如果最近更新了索引,请在检查结果之前稍等片刻。
以下屏幕截图显示了一个较旧的标准 1 (S1) 搜索服务,该服务配置为一个分区和一个副本。
存储配额是磁盘约束,它包含搜索服务上的所有索引(向量和非矢量)。
矢量索引大小配额是内存约束。 它是加载为搜索服务上每个向量字段创建的所有内部向量索引所需的内存量。
屏幕截图指示索引(向量和非矢量)消耗了将近 460 MB 字节的可用磁盘存储。 矢量索引在服务级别消耗了将近近 93 MB 字节的内存。

添加或删除分区时,存储和矢量索引大小的配额会随之增加或减少。 如果更改分区计数,则磁贴会显示相应的存储和矢量配额更改。
注意
在磁盘上,矢量索引不是 93 MB。 磁盘上的矢量索引占用的空间比内存中的矢量索引多三倍。 有关详细信息,请参阅矢量字段如何影响磁盘存储。
影响矢量索引大小的因素
影响内部矢量索引大小的三个主要因素:
- 数据的原始大小
- 所选算法的开销
- 删除或更新索引中的文档所产生的开销
数据的原始大小
每个矢量通常是单精度浮点数的数组,位于类型为 Collection(Edm.Single) 的字段中。
矢量数据结构需要存储,在以下计算公式中表示为数据的“原始大小”。 使用此原始大小来估算矢量字段的矢量索引大小要求。
一个矢量的存储大小由其维数决定。 将一个矢量的大小乘以包含该矢量字段的文档数即可得出原始大小:
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| EDM 数据类型 | 数据类型的大小 |
|---|---|
Collection(Edm.Single) |
4 个字节 |
Collection(Edm.Half) |
2 个字节 |
Collection(Edm.Int16) |
2 个字节 |
Collection(Edm.SByte) |
1 个字节 |
所选算法中的内存开销
每个近似最近的邻域 (ANN) 算法都会在内存中生成额外的数据结构,以实现高效搜索。 这些结构会消耗额外的内存空间。
对于 HNSW 算法,内存开销范围为 1% 到 20%。
对于较高维度,内存开销较低,因为矢量的原始大小会增加;而额外的数据结构保持固定大小,因为它们存储有关图形中的连接的信息。 因此,额外数据结构造成的开销仅占总体大小的一小部分。
HNSW 参数 m 的值越大,内存开销就越高,该参数决定了索引构造期间为每个新矢量创建的双向链接数量。 这是因为,m 造成的开销大约为每个文档 8 到 10 个字节乘以 m。
下表汇总了在内部测试中观察到的开销百分比:
| 维度 | HNSW 参数 (m) | 开销百分比 |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8% |
| 768 | 4 | 2% |
| 1536 | 4 | 1% |
| 3072 | 4 | 0.5% |
这些结果展示了 HNSW 算法的维度、HNSW 参数 m 和内存开销之间的关系。
删除或更新索引中的文档所产生的开销
删除或更新包含矢量字段的文档时(更新在内部表示为删除和插入操作),基础文档将被标记为已删除,并在后续查询期间被跳过。 随着新文档编制索引并且内部矢量索引不断增长,系统会清理这些已删除的文档并回收资源。 这意味着,在删除文档之后,释放基础资源之前,可能存在一段滞后时间。
我们将此称为“已删除的文档比率”。 由于已删除的文档比率取决于服务的索引编制特征,因此没有通用的启发式方法来估算此参数,并且没有任何 API 或脚本可以返回服务的实际比率。 我们已观察到,有一半客户的文档删除比率低于 10%。 如果你倾向于执行高频率的删除或更新,则可能会观察到较高的已删除文档比率。
这是影响矢量索引大小的另一个因素。 遗憾的是,没有任何一种机制可以显示当前的已删除文档比率。
估算内存中数据的总大小
考虑到前面描述的因素,若要估计矢量索引的总大小,请使用以下计算方法:
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
例如,为了计算 raw_size,让我们假设你使用的是一个流行的 Azure OpenAI 模型,即具有 1,536 个维度的 text-embedding-ada-002。 这意味着一个文档将消耗 1,536 个 Edm.Single(浮点数),即 6,144 个字节,因为每个 Edm.Single 为 4 个字节。 包含单个 1,536 维矢量字段的 1,000 个文档总共将消耗 1000 个文档 x 1536 个浮点数/文档 = 1,536,000 个浮点数,或 6,144,000 个字节。
如果有多个矢量字段,则需要对索引中的每个矢量字段执行此计算,并将所有计算结果相加。 例如,包含两个 1,536 维矢量字段的 1,000 个文档将消耗 1000 个文档 x 2 个字段 x 1536 个浮点/文档 x 4 字节/浮点 = 12,288,000 字节。
若要获取矢量索引大小,请将此 raw_size 乘以算法开销和已删除文档比率。 如果所选 HNSW 参数的算法开销为 10%,而已删除的文档比率为 10%,则会得到:6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB。
矢量字段如何影响磁盘存储
本文的大部分内容提供了有关内存中矢量大小的信息。 如果想知道磁盘上的矢量大小,矢量数据的磁盘消耗量大约是内存中矢量索引大小的三倍。 例如,如果 vectorIndexSize 使用量为 100 MB(1000 万字节),则将至少使用 300 MB 的 storageSize 配额来容纳矢量索引。