你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文提供 Azure Blob 存储上网络文件系统版本 3(NFS 3.0)的基准测试建议和结果。 由于 NFS 3.0 主要用于 Linux 环境,本文仅重点介绍 Linux 工具。 在许多情况下,可以使用其他操作系统,但工具和命令可能会更改。
概述
存储性能测试用于评估和比较不同的存储服务。 有多种方法可以执行它,但这些方法是最常见的三种方法:
- 使用标准 Linux 命令,通常
cp或dd。 - 使用性能基准工具,例如
fio,vdbench或ior。 - 使用一个在生产环境中使用的真实应用程序。
无论使用哪种方法,了解环境中的其他潜在瓶颈并确保它们不会影响结果始终很重要。 例如,测量写入性能时,需要确保源磁盘可以像预期写入性能一样快地读取数据。
相同的原则适用于读取性能。 理想情况下,在这些测试中,可以使用 RAM 磁盘。 需要对网络吞吐量和 CPU 利用率进行类似的注意事项。
使用标准 Linux 命令。 此方法是性能基准测试的最简单方法,但它也是最不推荐的。 此方法很简单,因为每个 Linux 环境中都存在工具,并且用户熟悉它们。 必须仔细分析结果,因为许多方面都对他们有影响,而不仅仅是存储性能。 通常使用的两个命令:
- 该
cp命令将一个或多个文件从源复制到目标存储服务,并测量完全完成操作所需的时间。 此命令执行缓冲(而不是直接)IO,具体取决于缓冲区大小、操作系统和线程模型。 另一方面,一些实际应用程序的行为方式类似,有时表示良好的用例。 - 该
dd命令是单线程的。 在大规模带宽测试中,结果受单个 CPU 核心的速度限制。 可以同时运行多个命令并将其分配给不同的核心,但该技术使测试和聚合结果复杂化。 运行起来也比一些性能基准测试工具要简单得多。
- 该
使用性能基准工具。 此方法表示通常用于比较不同存储服务的综合性能测试。 工具已正确设计为使用可用的客户端资源,以最大程度地提高存储吞吐量。 大多数工具都是可配置的,并允许模仿实际应用程序,至少是更简单的应用程序。 模拟实际应用程序需要有关应用程序行为和了解其存储模式的详细信息。
使用实际应用程序。 此方法始终是最佳方法,因为它度量用户正在存储服务上运行的实际工作负荷的性能。 此方法通常不实用,因为它需要生产环境和用户的副本才能在系统上生成适当的负载。 某些应用程序确实具有负载生成功能,应用于性能基准测试。
| 测试方法 | 优点 | 缺点 |
|---|---|---|
| 标准 Linux 命令 | -简单。 - 在任何 Linux 平台上都可用。 - 熟悉这些工具。 |
- 不适用于性能测试。 - 不可配置。 通常受限于 CPU 核心。 |
| 性能基准工具 | 针对性能测试进行了优化。 - 非常可配置。 - 简单的多节点测试。 |
设置真实环境测试非常复杂。 |
| 实际应用 | - 提供准确的用户体验。 | - 通常用户运行测试。 - 需要生产环境的副本。 - 可以是主观的。 |
尽管使用实际应用程序进行性能测试是最佳选择,但由于测试设置的简单性,最常见的方法是使用性能基准测试工具。 我们显示了使用 NFS 3.0 在 Azure Blob 存储上运行性能测试的建议设置。
小窍门
大多数性能测试方法都侧重于单个客户端性能。 若要进行横向扩展测试,请使用可协调多客户端测试(例如 fio 或 vdbench)的性能基准工具。 还可以构建自定义编排层。
选择虚拟机大小
若要正确执行性能测试,第一步是正确调整在测试中使用的虚拟机(VM)的大小。 VM 充当运行性能基准测试工具的客户端。 为该测试选择虚拟机大小时最重要的因素是可用网络带宽。 选择的 VM 越大,可实现的结果就越好。 如果在 Azure 中运行测试,建议使用常规 用途 VM 之一。
使用 NFS 3.0 创建存储帐户
选择 VM 后,需要创建用于测试的存储帐户。 有关分步指南,请参阅 使用网络文件系统 (NFS) 3.0 协议装载 Blob 存储。 建议在测试之前阅读 Azure Blob 存储中 NFS 3.0 的性能注意事项 。
其他注意事项
- 具有 NFS 3.0 终结点的 VM 和存储帐户必须位于同一区域。
- 运行测试应用程序的 VM 应仅用于测试,以确保其他正在运行的服务不会影响结果。
- 挂载 NFS 3.0 终结点时必须使用 AzNFS 挂载辅助客户端以确保可靠访问。
执行性能基准测试
可在 Linux 环境中使用多个性能基准测试工具。 可以使用其中任何一个来评估性能。 我们与灵活 I/O (FIO) 测试人员共享我们的推荐方法。 FIO 通过每个 Linux 分发版的标准包管理器或 作为源代码提供。 可以在许多测试方案中使用它。
本文介绍 Azure 存储的建议方案。 有关进一步自定义和不同的参数,请参阅 FIO 文档。
以下参数用于测试。
| 工作量 | 指标 | 块大小 | 线程 | IO 深度 | 文件大小 | nconnect |
直接 IO |
|---|---|---|---|---|---|---|---|
| 顺序 | Bandwidth | 1 MiB(兆字节) | 8 | 1024 | 10 GiB | 16 | 是的 |
| 顺序 | IOPS | 4 KiB | 8 | 1024 | 10 GiB | 16 | 是的 |
| 随机 | IOPS | 4 KiB | 8 | 1024 | 10 GiB | 16 | 是的 |
我们的测试设置是在“美国东部”区域中完成的,客户端 VM 类型 为D32ds_v5 ,文件大小为 10 GB。 所有测试都运行了 100 次,结果显示平均值。 测试是在标准存储帐户和高级存储帐户上完成的。 详细了解存储帐户 概述中这两种类型的存储帐户之间的差异。
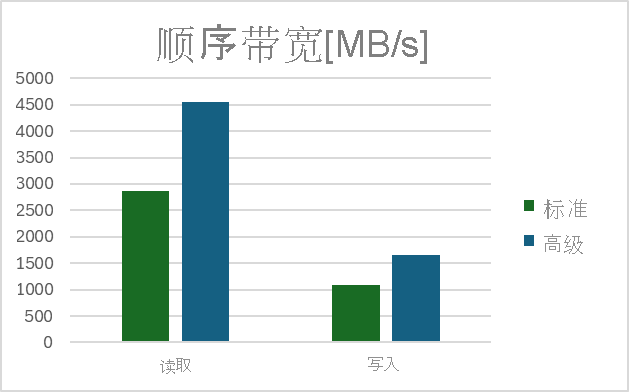
测量顺序带宽
读取带宽
fio --name=seq_read_bw --ioengine=libaio --directory=/mnt/test_folder --direct=1 --blocksize=1M --readwrite=read --filesize=10G --end_fsync=1 --numjobs=8 --iodepth=1024 --runtime=60 --group_reporting --time_based=1
写入带宽
fio --name=seq_write_bw --ioengine=libaio --directory=/mnt/test_folder --direct=1 --blocksize=1M --readwrite=write --filesize=10G --end_fsync=1 --numjobs=8 --iodepth=1024 --runtime=60 --group_reporting --time_based=1
结果
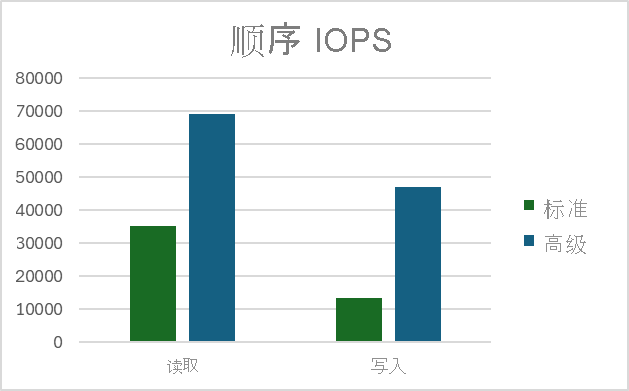
测量顺序输入/输出操作每秒 (IOPS)
读取 IOPS
fio --name=seq_read_iops --ioengine=libaio --directory=/mnt/test_folder --direct=1 --blocksize=4K --readwrite=read --filesize=10G --end_fsync=1 --numjobs=8 --iodepth=1024 --runtime=60 --group_reporting --time_based=1
写 IOPS
fio --name=seq_write_iops --ioengine=libaio --directory=/mnt/test_folder --direct=1 --blocksize=4K --readwrite=write --filesize=10G --end_fsync=1 --numjobs=8 --iodepth=1024 --runtime=60 –group_reporting –time_based=1
结果
注释
顺序 IOPS 测试结果显示每秒请求数值超过了存储帐户限制。 IOPS 在客户端进行度量。 较大的值是由于服务优化和测试的顺序性质。
测量随机 IOPS
读取 IOPS
fio --name=rnd_read_iops --ioengine=libaio --directory=/mnt/test_folder --direct=1 --blocksize=4K --readwrite=randread --filesize=10G --end_fsync=1 --numjobs=8 --iodepth=1024 --runtime=60 --group_reporting --time_based=1
写 IOPS
fio --name=rnd_write_iops --ioengine=libaio --directory=/mnt/test_folder --direct=1 --blocksize=4K --readwrite=randwrite --filesize=10G --end_fsync=1 --numjobs=8 --iodepth=1024 --runtime=60 –group_reporting –time_based=1
结果
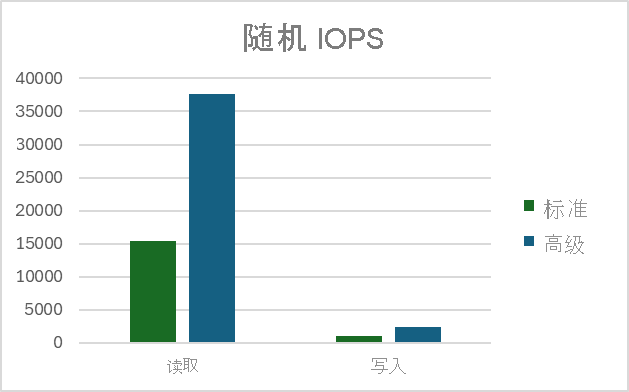
注释
将添加随机测试的结果以确保完整。 不建议将 Blob 存储上的 NFS 3.0 终结点用作随机写入工作负荷的存储服务。