你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文介绍如何做出设计选择,以解决 Azure 流分析作业中的实际时间处理问题。 时间处理设计决策与事件排序因素密切相关。
后台时间概念
为了在一个更好的框架背景下讨论,现在来定义一些后台概念:
事件时间:原始事件发生的时间。 例如,当高速公路上行使的汽车接近收费站时。
处理时间:事件到达处理系统时且被观察到的时间。 例如,收费站传感器看到汽车时,计算机系统需要一些时间来处理数据。
水印:一个事件时间标记,指示在某个时点之前,事件已进入流式处理器。 通过水印,系统能够指示事件引入过程的明确进度。 流式传输的性质决定了事件数据的传入永远不会停止,因此水印指示的是流式传输中某个时点的进度。
水印概念很重要。 流分析功能通过水印能够确定系统何时可以生成不需要撤回的完整、正确且可重复的结果。 该处理过程能够以可预测和可重复的方式完成。 例如,如果需要对某些错误处理条件进行重新计数,则水印是安全的起点和终点。
有关此主题的更多资源,请参阅 Tyler Akidau 的博客文章流式处理 101 和流式处理 102。
选择最佳开始时间
流分析为用户提供两种事件时间选项:到达时间和应用程序时间。
到达时间
当事件抵达源时,会在输入源中分配到达时间。 可以使用事件中心输入的 EventEnqueuedUtcTime 属性、IoT 中心输入的 IoTHub.EnqueuedTime 属性以及 Blob 输入的 BlobProperties.LastModified 属性来访问到达时间。
默认选项为使用到达时间,该时间最适用于数据存档方案。这种情况下,不需要时态逻辑。
应用程序时间(也称为事件时间)
生成事件时,会分配应用程序时间。应用程序时间是事件有效负载的一部分。 若要按应用程序时间处理事件,可在 SELECT 查询中使用“Timestamp by”子句。 如果缺少“Timestamp by”,则会按到达时间处理事件。
如果需要使用时态逻辑来说明源系统或网络中的延迟,则必须在有效负载中使用时间戳。 可在 SYSTEM.TIMESTAMP 中查看分配给事件的时间。
Azure 流分析中时间的进展方式
如果使用应用程序时间,时间进度基于传入的事件。 流式传输处理系统很难知道是否不存在事件或者事件是否延迟。 出于此原因,Azure 流分析通过下列方式为每个输入分区生成启发式水印:
每当有事件传入时,水印是到目前为止观察到的最大事件时间流分析与无序容错时段之差。
没有事件传入时,水印是当前估计到达时间与延迟到达容错时段之差。 估计到达时间是从上次观察到输入事件起经过的时间与该输入事件的到达时间之和。
到达时间只能估计,因为实际到达时间在输入事件中转站(例如,事件中心)上生成,而不是在处理事件的 Azure 流分析 VM 上生成。
除了生成水印之外,此设计还有其他两个用途:
无论是否有传入事件,系统都能及时生成结果。
可以控制输出结果呈现的及时程度。 在 Azure 门户中,在流分析作业的“事件排序”页面上,可以配置“无序事件”设置 。 在配置该设置时,应权衡事件流中的时效性与无序事件的容错程度。
延迟到达容错时段对于持续生成水印是必需的,即使在没有传入事件的情况下也是如此。 有时,可能存在无事件传入的时段,例如,当事件输入流的内容非常稀少时。 在输入事件中转站中使用多个分区会导致这一问题变得更加严重。
当输入较少且使用多个分区时,没有延迟到达容错时段的流式数据处理系统可能会受到延迟输出的影响。
系统行为必须是可重复的。 重复性是流式数据处理系统的重要属性。
水印是根据到达时间和应用程序时间生成的。 两者都保留在事件中转站中,因此是可重复的。 如果在没有事件的情况下估计到达时间,出于故障恢复的目的,Azure 流分析会记录估计的到达时间,以便在重播时实现可重复性。
选择使用“到达时间”作为事件时间时,无需配置无序容错和延迟到达容错。 由于要保证“到达时间”在输入事件中转站中递增,因此 Azure 流分析会忽略配置。
延迟到达的事件
根据延迟到达容错时段的定义,对于每个传入事件,Azure 流分析会将事件时间与到达时间进行比较。 如果事件时间在容错时段之外,则可以将系统配置为删除事件或将事件的时间调整为在容错范围内。
生成水印之后,服务可能会接收事件时间小于水印的事件。 可以将服务配置为“删除”这些事件,或将事件的时间“调整”为水印值。
调整时,将事件的“System.Timestamp”设置为新值,但“事件时间”字段本身不会更改。 此调整是唯一存在后列现象的情况:事件的“System.Timestamp”与事件时间字段中的值不同,且可能导致产生意外的结果。
使用子流处理时间变化
所述的启发式水印生成机制在大多数后述情况下都能正常发挥效用:时间在各种事件发送程序之间基本同步。 但在现实生活中,尤其是在许多 IoT 方案中,系统对事件发送方的时钟几乎无法控制。 事件发送方可以是领域中的各种设备,也可以是不同版本的硬件和软件。
流分析没有对输入分区中的所有事件使用全局水印,而是使用另一种称为子流的机制。 可以通过编写使用“TIMESTAMP BY”子句和“OVER”关键字的作业查询,在作业中利用子流 。 要指定子流,请在“OVER”关键字后面提供关键列名称(例如,deviceid),以便系统按该列应用时间策略。 每个子流都有自己独立的水印。 在处理事件发送方之间的较大时钟偏差或网络延迟时,此机制有助于及时生成输出。
子流是 Azure 流分析提供的独家解决方案,其他流式数据处理系统不提供子流。
在使用子流时,流分析将延迟到达容错时段应用于传入事件。 延迟到达容错决定了不同子流可以彼此间隔的最大数。 例如,如果设备 1 位于时间戳 1,而设备 2 位于时间戳 2,则延迟到达容错的最大值为时间戳 2 与时间戳 1 之差。 对于具有不同时间戳的设备来说,默认设置为 5 秒可能太小。 建议开始时设为 5 分钟,然后根据设备时钟偏差模式进行调整。
提前到达的事件
你可能已注意到另一个称为“提前到达时段”的概念,它看起来与延迟到达容错时段相反。 这个时段固定为 5 分钟,其用途与延迟到达容错时段不同。
由于 Azure 流分析可保证完整的结果,因此只能将“作业开始时间”指定为作业的第一个输出时间,而不能指定为输入时间。 作业开始时间是必需的,以便处理完整时段,而不仅仅是从时段中间进行处理。
流分析通过查询规范得到开始时间。 但是,由于输入事件中转站仅按到达时间编制索引,因此系统必须将开始事件时间转换为到达时间。 系统可以从输入事件中转站中的这一时点开始处理事件。 由于提前到达时段的限制,这一转换很简单:开始事件时间减去 5 分钟的提前到达时段。 此计算还意味着系统会删除事件时间比到达时间早 5 分钟的所有事件。 删除事件时,提前输入事件指标是递增的。
此概念用于确保无论从何处开始输出,处理过程都可重复。 如果不借助这种机制,就不可能像许多其他流式处理系统声称的那样保证可重复性。
事件排序时间容错的副作用
流分析作业有多个“事件排序”选项。 可以在 Azure 门户中配置两个选项:“无序事件”设置(无序容错)和“延迟到达的事件”设置(延迟到达容错) 。 “提前到达”容错是固定的,无法调整。 流分析使用这些时间策略来提供强有力的保障。 但是,这些设置确实会产生一些意想不到的影响:
意外过早发送事件。
不应正常输出提前事件。 如果发送方的时钟运行太快,可能会输出提前事件。 所有提前到达的事件都会被丢弃,因此你不会在输出中看到任何事件。
将旧事件发送到事件中心供 Azure 流分析处理。
旧的事件最初可能看起来无害,但由于应用了延迟到达容错,可能会丢弃旧的事件。 如果事件太旧,System.Timestamp 值将在事件引入期间发生更改。 由于此行为,当前 Azure 流分析更适合接近实时的事件处理方案,而不适合历史事件处理方案。 在某些情况下,可以将“延迟到达的事件”时间设置为最大可能值(20 天)以解决此问题。
输出似乎有所延迟。
在计算的时间生成第一个水印:系统迄今观察到的“最大事件时间”减去无序容错时段。 默认情况下,无序容错配置为零(00 分 00 秒)。 将无序容错设置为更高的非零时间值时,因计算的第一个水印时间的缘故,会延迟流式作业的第一个输出,延迟时间即为该时间值(或更高值)。
输入非常少。
如果给定分区中没有任何输入,水印时间计算方式为“到达时间”减去延迟到达容错时段。 因此,如果事件输入不频繁且很少,则可能会延迟输出,延迟时间为此时间量。 “延迟到达的事件”的默认值为 5 秒。 例如,一次发送一个输入事件时,应会产生一定的延迟。 将“延迟到达的事件”时段设置为较大值时,延迟会更长。
“System.Timestamp”值与“事件时间”字段中的时间不同 。
如前所述,系统通过无序容错或延迟到达容错时段调整事件时间。 事件的“System.Timestamp”值进行了调整,但不会调整“事件时间”字段 。 这可用于确定时间戳调整了哪些事件。 如果系统由于其中一个容错而更改了时间戳,则通常它们是相同的。
要观察的指标
可以通过 Azure 流分析作业指标观察一系列的事件排序时间容错效应。 以下指标是相关的:
| 指标 | 说明 |
|---|---|
| 无序事件数 | 表示收到的无序事件的数目,这些事件或已丢弃或已为其提供调整后的时间戳。 此指标直接受 Azure 门户中作业的“事件排序”页面上“无序事件”设置的配置影响 。 |
| 延迟输入事件数 | 表示从源延迟到达的事件数目。 此指标包括已删除或者已调整其时间戳的事件。 此指标直接受 Azure 门户中作业的“事件排序”页面上的“延迟到达的事件”设置的配置影响 。 |
| 提前输入事件数 | 表示从源处提前到达的事件的数目,这些事件或已删除,或提前超过 5 分钟已调整了时间戳。 |
| 水印延迟 | 表示流式数据处理作业延迟。 有关详细信息,请参阅以下部分。 |
水印延迟详细信息
“水印延迟”指标的计算方式为处理节点的时钟时间减去其迄今观察到的最大水印时间。 有关详细信息,请参阅水印延迟。
在正常操作下,此指标值大于 0 可能有多种原因:
流式管道的内在处理延迟。 通常这种延迟是常规性的。
无序容错时段带来延迟,因为水印扣减了容错时段的量。
延迟到达时段带来延迟,因为水印扣减了容错时段的量。
生成指标的处理节点存在时钟偏差。
还存在许多其他可能导致流式管道速度变慢的资源限制。 由于以下原因,水印延迟指标可能会上升:
流分析中没有足够的处理资源用于处理输入事件。 有关详细信息,请参阅了解和调整流单元。
输入事件中转站中的吞吐量不足,因此会受到限制。 有关可能的解决方案,请参阅自动增加 Azure 事件中心吞吐量单位。
输出接收器没有预配足够的容量,因此会受到限制。 可能的解决方案因所使用的输出服务的风格而有很大差异。
输出事件频率
Azure 流分析使用水印进度作为生成输出事件的唯一触发器。 水印源自输入数据,因此在故障恢复期间以及用户发起的重新处理过程中都是可重复的。 使用时段化聚合时,该服务仅在时段结束时生成输出。 在某些情况下,用户可能希望查看从时段生成的部分聚合。 Azure 流分析目前不支持某些聚合。
在其他流式处理解决方案中,输出事件可以在各种触发点处具体化,具体取决于外部环境。 在某些解决方案中,可能会为给定时段组多次生成输出事件。 随着输入值的细化,聚合结果会更加准确。 可以先推测事件,然后随着时间的推移进行修正。 例如,当某个设备从网络离线时,系统可以使用估计值。 稍后,同一设备联机到网络。 然后可以将实际事件数据包含在输入流中。 处理该时段所得到的输出结果会包含更准确的输出内容。
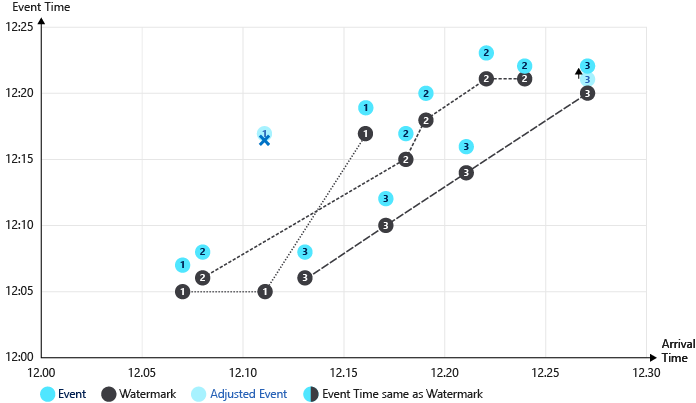
水印示例图
以下图像显示了水印在不同情况下的进展方式。
此表显示了下面制成图表的示例数据。 请注意,事件时间与到达时间会有变化,有时匹配,而有时不匹配。
| 事件时间 | 到达时间 | DeviceId |
|---|---|---|
| 12:07 | 12:07 | device1 |
| 12:08 | 12:08 | device2 |
| 12:17 | 12:11 | device1 |
| 12:08 | 12:13 | 设备3 |
| 12:19 | 12:16 | device1 |
| 12:12 | 12:17 | 设备3 |
| 12:17 | 12:18 | device2 |
| 12:20 | 12:19 | device2 |
| 12:16 | 12:21 | 设备3 |
| 12:23 | 12:22 | device2 |
| 12:22 | 12:24 | device2 |
| 12:21 | 12:27 | 设备3 |
此图中使用了以下容错:
- 提前到达时段为 5 分钟
- 延迟到达时段为 5 分钟
- 重新排序时段为 2 分钟
这些事件进展的水印图示:
上图中的显著进程:
第一个事件 (device1) 和第二个事件 (device2) 具有一致的时间,未经过调整即被处理。 水印时间在每个事件上持续计时。
处理第三个事件 (device1) 时,到达时间 (12:11) 早于事件时间 (12:17)。 事件提前 6 分钟到达,因 5 分钟的提前到达容错而删除了该事件。
在发生这种事件提前到达的情况下,水印时间不会继续计时。
第四个事件 (device3) 和第五个事件 (device1) 具有一致的时间,未经过调整即被处理。 水印时间在每个事件上持续计时。
处理第六个事件 (device3) 时,到达时间 (12:17) 和事件时间 (12:12) 均低于水印时间。 事件时间调整为水印时间 (12:17)。
处理第十二个事件 (device3) 时,到达时间 (12:27) 比事件时间 (12:21) 提前 6 分钟。 适用延迟到达策略。 对事件时间进行了调整 (12:22),该时间高于水印时间 (12:21),因此不再进行进一步调整。
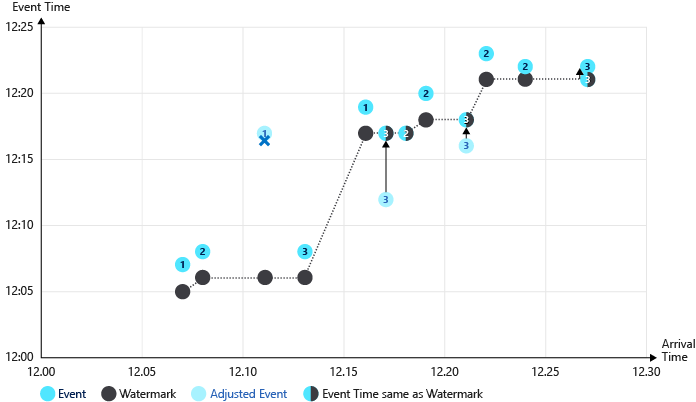
未应用提前到达策略的水印计时第二图示:
在此示例中,未应用提前到达策略。 较早到达的异常事件会显着提高水印值。 请注意,在这种情况下不丢弃第三个事件(deviceId1 时间 12:11),且水印时间提升至 12:15。 因此,第四个事件时间向后调整了 7 分钟(从 12:08 到 12:15)。
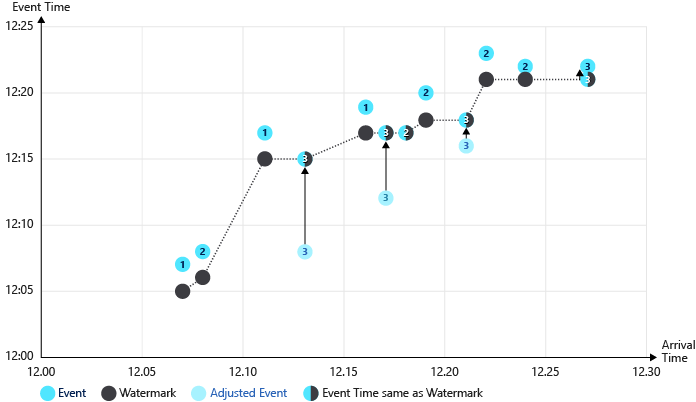
在最后一图中,使用了子流(通过 DeviceId)。 跟踪了多个水印,每个流一个水印。 因此,调整时间的事件减少了。