重要
Azure Synapse Analytics 数据资源管理器(预览版)将于 2025 年 10 月 7 日停用。 在此日期之后,Synapse 数据资源管理器上运行的工作负荷将被删除,关联的应用程序数据将丢失。 强烈建议迁移到 Microsoft Fabric 中的 Eventhouse 。
Microsoft云迁移工厂(CMF)计划旨在帮助客户迁移到 Fabric。 该计划向客户免费提供动手键盘资源。 这些资源在 6-8 周内分配,并具有预定义和同意的范围。 客户提名可以通过 Microsoft 帐户团队接受,或者直接提交《帮助请求》给 CMF 团队。
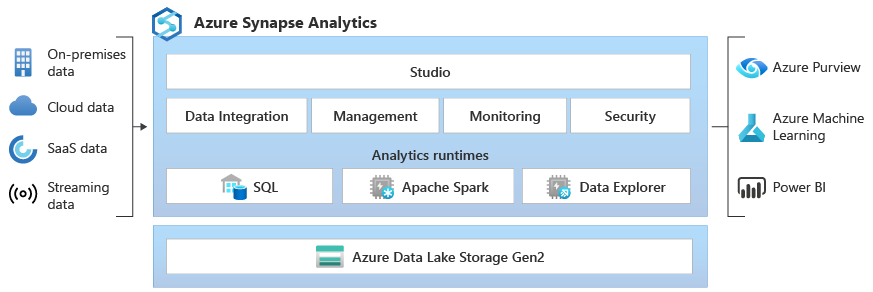
Azure Synapse 数据资源管理器为客户提供交互式查询体验,以从日志和遥测数据中解锁见解。 为了补充现有的 SQL 和 Apache Spark 分析运行时引擎,数据资源管理器分析运行时使用强大的索引技术来自动为遥测数据中常用的自由文本和半结构化数据编制索引,从而优化高效日志分析。
若要了解详细信息,请参阅以下视频:
Azure Synapse 数据资源管理器有什么独特之处?
轻松引入 - 数据资源管理器为无代码/低代码、高吞吐量数据引入和实时源中的数据缓存提供内置集成。 可以从 Azure 事件中心、Kafka、Azure Data Lake、开源代理(如 Fluentd/Fluent Bit)和各种云和本地数据源等源引入数据。
没有复杂的数据建模 - 使用数据浏览器时,无需构建复杂的数据模型,也不需要编写复杂的脚本来转换数据之后再使用。
没有索引维护 - 无需维护任务来优化查询性能的数据,也不需要索引维护。 使用数据浏览器,可立即访问所有原始数据,从而在流式处理和持久性数据上运行高性能和高并发查询。 可以使用这些查询生成准实时仪表板和警报,将运营分析数据与数据分析平台的其余部分连接起来。
实现数据分析的民主化 - 数据资源管理器使用直观的 Kusto 查询语言(KQL),使大众更容易进行自助式大数据分析。KQL 结合了 SQL 的表现力和强大功能以及 Excel 的简单易用。 KQL 通过利用数据资源管理器的顶级文本索引技术,进行高效的自由文本和正则表达式搜索,同时提供全面的解析能力,来查询跟踪和文本数据以及 JSON 半结构化数据(包括数组和嵌套结构),从而对原始遥测和时序数据进行高度优化。 KQL 提供高级时序支持,用于创建、作和分析多个时序,并提供引擎内 Python 执行支持进行模型评分。
采用 PB 级验证的技术 - 数据资源管理器是一种分布式系统,其计算资源和存储可以独立缩放,从而对千兆字节或 PB 级数据进行分析。
集成 - Azure Synapse Analytics 在数据资源管理器、Apache Spark 和 SQL 引擎之间提供跨数据的互作性,使数据工程师、数据科学家和数据分析师能够轻松、安全地访问和协作数据湖中的相同数据。
何时使用 Azure Synapse 数据资源管理器?
使用数据资源管理器作为数据平台来生成准实时日志分析和 IoT 分析解决方案,以便:
跨本地、云和第三方数据源合并和关联日志和事件数据。
加速 AI Ops 旅程(模式识别、异常情况检测、预测等)。
替换基于基础结构的日志搜索解决方案,以节省成本并提高工作效率。
为 IoT 数据生成 IoT 分析解决方案。
构建分析 SaaS 解决方案,为内部和外部客户提供服务。
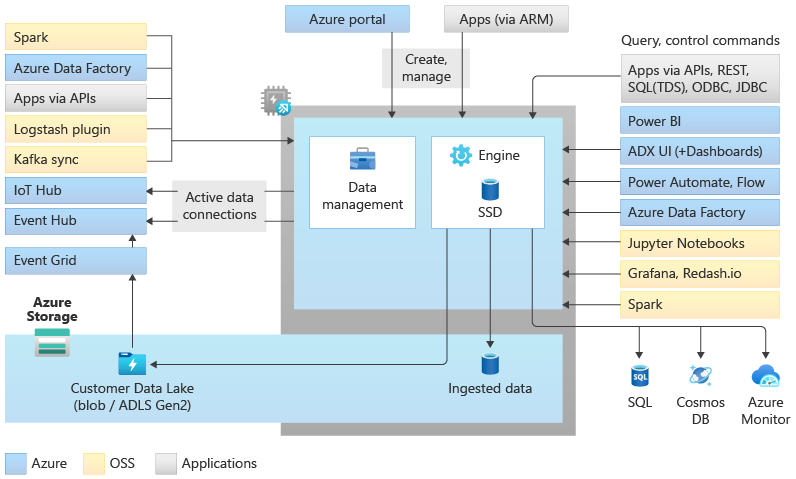
数据探索池架构
数据资源管理器池通过分离计算和存储资源来实现横向扩展体系结构。 这样,便可以独立缩放每个资源,例如,对同一数据运行多个只读计算。 数据资源管理器池由一组计算资源组成,这些资源运行引擎负责自动编制索引、压缩、缓存和提供分布式查询。 它们还有第二组计算资源,用于运行负责后台系统作业的数据管理服务,和管理以及排队的数据引入。 所有数据都持久化在使用压缩列格式的托管的 Blob 存储帐户上。
数据探查器池支持一个丰富的生态系统,可以通过连接器、SDK、REST API 以及其他托管功能来导入数据。 它提供了各种方法来消费数据,用于临时查询、报表、仪表板、警报、REST API 接口和 SDK。
有许多独特的功能使 Data Explore 成为 Azure 上的日志和时序分析的最佳分析引擎。
以下部分重点介绍了关键区别。
自由文本和半结构化数据索引可实现近乎实时的高性能和高并发查询
数据资源管理器对半结构化数据(JSON)和非结构化数据(自由文本)编制索引,这使得运行查询对此类数据表现良好。 默认情况下,每个字段在数据引入期间都编制索引,并可以选择使用低级别编码策略微调或禁用特定字段的索引。 索引的范围是单个数据分片。
索引的实现取决于字段的类型,如下所示:
| 字段类型 | 索引实现 |
|---|---|
| 字符串 | 引擎为字符串列值生成倒排术语索引。 将分析每个字符串值并将其拆分为规范化术语,并为每个术语记录包含记录序号的有序逻辑位置列表。 生成的术语及其关联位置的排序列表存储为不可变的 B 树。 |
|
数值 日期时间 TimeSpan |
引擎生成基于范围的简单前向索引。 索引记录每个块的最小值/最大值、一组块以及数据分片中的整个列。 |
| 动态 | 引入过程枚举动态值中的所有“原子”元素,例如属性名称、值和数组元素,并将其转发到索引生成器。 动态字段与字符串字段具有相同的倒排术语索引。 |
这些高效的索引功能使 Data Explore 能够近乎实时地提供数据,以便进行高性能和高并发查询。 系统会自动优化数据分片,以进一步提升性能。
Kusto 查询语言
KQL 拥有庞大的、不断增长的社区,可快速采用 Azure Monitor Log Analytics 和 Application Insights、Microsoft Sentinel、Azure 数据资源管理器和其他Microsoft产品/服务。 该语言设计良好,具有易于阅读的语法,并提供从简单的单行器到复杂数据处理查询的平滑转换。 这样,Data Explorer 就可以提供丰富的 Intellisense 支持,以及丰富的语言构造和内置功能合集,这些功能用于聚合、时间序列和用户分析,而这些在 SQL 中是不可用的,以便对遥测数据进行快速探索。