你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Foundry 工具中的 Azure 视觉 是 一种Microsoft Foundry 工具 ,可用于根据视觉特征处理图像和返回信息。 本教程介绍如何使用 视觉 分析 Azure Synapse Analytics 上的图像。
本教程演示如何将文本分析和 SynapseML 结合使用来实现以下目的:
- 从图像内容中提取视觉特征
- 识别图像中的字符 (OCR)
- 分析图像内容并生成缩略图
- 检测和识别图像中特定领域的内容
- 生成与图像相关的标记
- 以人类可读的语言生成整个图像的说明
分析图像
根据图像内容提取一组丰富的视觉特征,例如物体、人脸、成人内容和自动生成的文本说明。
示例输入

# Create a dataframe with the image URLs
df = spark.createDataFrame([
("<replace with your file path>/dog.jpg", )
], ["image", ])
# Run the Vision service. Analyze Image extracts information from/about the images.
analysis = (AnalyzeImage()
.setLinkedService(ai_service_name)
.setVisualFeatures(["Categories","Color","Description","Faces","Objects","Tags"])
.setOutputCol("analysis_results")
.setImageUrlCol("image")
.setErrorCol("error"))
# Show the results of what you wanted to pull out of the images.
display(analysis.transform(df).select("image", "analysis_results.description.tags"))
预期结果
["dog","outdoor","fence","wooden","small","brown","building","sitting","front","bench","standing","table","walking","board","beach","holding","bridge"]
光学字符识别 (OCR)
从图像(例如路标和产品的照片)以及文档(发票、账单、财务报表、文章等)中提取打印文本、手写文本、数字和货币符号。 该技术经过优化,可以从多文本图像中提取文本,也可从包含混合语言的多页 PDF 文档中提取文本。 它支持检测同一图像或文档中的印刷文本和手写文本。
示例输入

df = spark.createDataFrame([
("<replace with your file path>/ocr.jpg", )
], ["url", ])
ri = (ReadImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("ocr"))
display(ri.transform(df))
预期结果
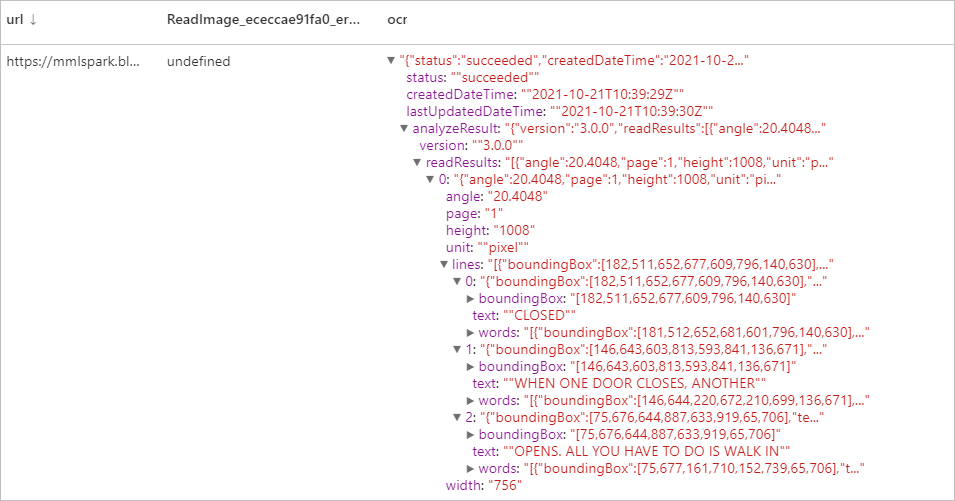
生成缩略图
分析图像的内容,生成该图像的相应缩略图。 视觉服务首先生成高质量缩略图,然后通过分析图像中的对象来确定感兴趣区域。 Vision随后将图像裁剪以适应感兴趣区域的要求。 可以根据您的需求,显示生成的缩略图时,可以使用与原始图像不同的纵横比。
示例输入

df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
gt = (GenerateThumbnails()
.setLinkedService(ai_service_name)
.setHeight(50)
.setWidth(50)
.setSmartCropping(True)
.setImageUrlCol("url")
.setOutputCol("thumbnails"))
thumbnails = gt.transform(df).select("thumbnails").toJSON().first()
import json
img = json.loads(thumbnails)["thumbnails"]
displayHTML("<img src='data:image/jpeg;base64," + img + "'>")
预期结果

标记图像
生成与所提供图像的内容相关的单词或标记列表。 标记是根据在图像中找到的数千个可识别物体、生物、风景或动作返回的。 标记可以包含提示以避免歧义或提供上下文,例如标记“ascomycete”可以附带提示“fungus”。
让我们继续使用 Satya 的图像作为示例。
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
ti = (TagImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("tags"))
display(ti.transform(df))
预期结果
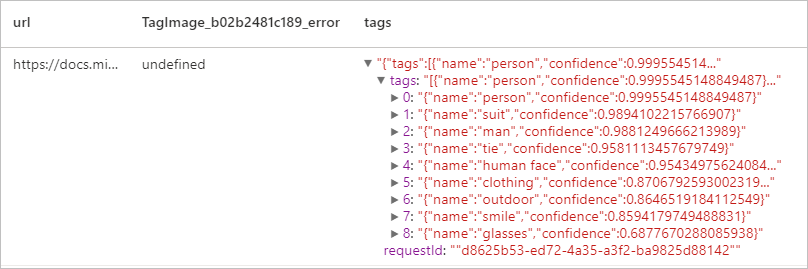
描述图像
使用完整的句子,以人类可读语言生成整个图像的说明。 视觉服务的算法可根据图像中标识的对象生成各种说明。 分别对这些说明进行评估并生成置信度分数。 然后将返回置信度分数从高到低的列表。
让我们继续使用 Satya 的图像作为示例。
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
di = (DescribeImage()
.setLinkedService(ai_service_name)
.setMaxCandidates(3)
.setImageUrlCol("url")
.setOutputCol("descriptions"))
display(di.transform(df))
预期结果
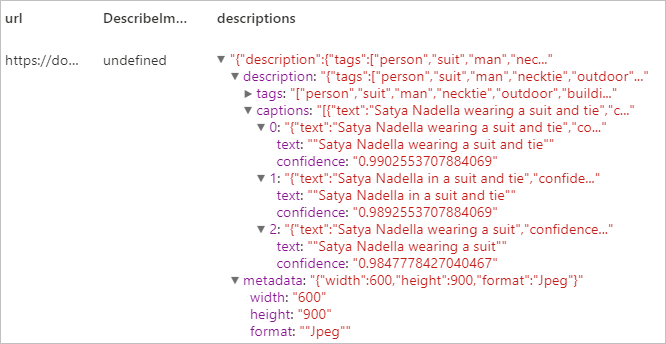
识别领域特定的内容
使用域模型来检测和标识图像中特定领域的内容,例如名人和地标。 例如,如果图像中包含人物,视觉服务可以使用针对名人的域模型来确定图像中检测到的人物是否为已知名人。
让我们继续使用 Satya 的图像作为示例。
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
celeb = (RecognizeDomainSpecificContent()
.setLinkedService(ai_service_name)
.setModel("celebrities")
.setImageUrlCol("url")
.setOutputCol("celebs"))
display(celeb.transform(df))
预期结果
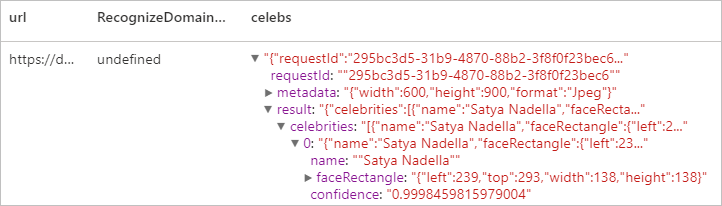
清理资源
为了确保关闭 Spark 实例,请结束任何已连接的会话(笔记本)。 达到 Apache Spark 池中指定的空闲时间时,池将会关闭。 也可以从笔记本右上角的状态栏中选择“停止会话”。
