你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
针对 Teradata 迁移的数据迁移、ETL 和负载
本文是一个包含七部分的系列教程的第二部分,提供有关如何从 Teradata 迁移到 Azure Synapse Analytics 的指导。 本文的重点是 ETL 和负载迁移的最佳做法。
数据迁移注意事项
有关从 Teradata 迁移数据的初始决策
迁移 Teradata 数据仓库时,需要询问一些与数据相关的基本问题。 例如:
是否应迁移未使用过的表结构?
若要最大程度地降低风险和用户影响,最佳迁移方法是什么?
迁移数据市场时:是保持物理状态还是转为虚拟状态?
接下来的部分将在从 Teradata 迁移的背景下讨论这些问题。
是否迁移未使用的表?
提示
在旧系统中,表随着时间推移而变得冗余的情况很常见,在大多数情况下不需要迁移这些表。
只迁移现有系统正在使用的表是合理的。 可对非活动状态的表进行存档,而不是迁移,以便将来在必要时可使用这些数据。 若要确定正在使用哪些表,最好使用系统元数据和日志文件(而不是文档),因为文档可能已过时。
如果启用,Teradata 系统目录表和日志包含的信息可确定给定表的上次访问时间,而这些信息又可用于确定表是否适合迁移。
下面是一个关于 DBC.Tables 的示例查询,其提供上次访问和上次修改的日期:
SELECT TableName, CreatorName, CreateTimeStamp, LastAlterName,
LastAlterTimeStamp, AccessCount, LastAccessTimeStamp
FROM DBC.Tables t
WHERE DataBaseName = 'databasename'
如果启用了日志记录并且可以访问日志历史记录,则其他信息(例如 SQL 查询文本)在表 DBQLogTbl 和关联的日志记录表中可用。 有关详细信息,请参阅 Teradata 日志历史记录。
若要最大程度地降低用户风险和影响,最佳迁移方法是什么?
这个问题经常出现,因为公司可能希望降低更改对数据仓库数据模型的影响,以提高敏捷性。 在 ETL 迁移过程中,公司通常会看到进一步实现数据现代化或转换的机会。 这种方法具有更高的风险,因为它同时改变了多个因素,从而很难比较新旧系统的结果。 在此处进行数据模型更改也可能会影响其他系统的上游或下游 ETL 作业。 由于存在这种风险,因此最好在数据仓库迁移后于此范围内重新设计。
即使在整体迁移过程中有意更改了数据模型,最好也将现有模型按原样迁移到 Azure Synapse,而不是在新平台上进行任何重新设计。 此方法可最大程度地降低对现有生产系统的影响,同时可利用 Azure 平台的性能和灵活的可伸缩性来完成一次性重新设计任务。
从 Teradata 迁移时,请考虑在 Azure 内的 VM 中创建 Teradata 环境,作为迁移过程中的一块垫脚石。
提示
最初按原样迁移现有模型(即使计划将来对数据模型进行更改)。
在迁移过程中使用 VM Teradata 实例
从本地 Teradata 环境迁移的一种可选方法是,利用 Azure 环境在 Azure 内的 VM 中创建一个 Teradata 实例,该实例与目标 Azure Synapse 环境位于同一位置。 此方法可行的原因在于 Azure 提供成本低廉的云存储空间和弹性的可伸缩性。
借助此方法,标准 Teradata 实用工具(如 Teradata Parallel Data Transporter)或第三方数据复制工具(如 Attunity Replicate)可用于高效地移动需要迁移到 VM 实例的 Teradata 表子集。 然后,可在 Azure 环境中执行所有迁移任务。 此方法具有以下几个优点:
完成初始数据复制后,迁移任务不会影响源系统。
Azure 环境具有熟悉的 Teradata 界面、工具和实用工具。
Azure 环境在本地源系统和云目标系统之间提供网络带宽可用性。
Azure 数据工厂等工具可高效调用 Teradata Parallel Transporter 等实用工具,以快速轻松地迁移数据。
迁移过程完全在 Azure 环境内部进行协调和控制。
迁移数据市场时,是保持物理状态还是转为虚拟状态?
提示
将数据市场虚拟化可节省存储和处理资源。
在旧 Teradata 数据仓库环境中,通常会创建多个结构化数据市场,以便为组织中的给定部门或业务职能的即席自助查询和报表提供良好的性能。 因此,数据市场通常由数据仓库的一部分组成,并包含数据的聚合版本,其形式使用户能够通过便于用户使用的查询工具(如 Microsoft Power BI、Tableau 或 MicroStrategy)轻松查询数据。 这种形式通常是一个维度数据模型。 数据市场的一种用途是以可用形式公开数据,即使基础仓库数据模型不同(如数据保管库)。
可针对组织中的不同业务部门使用单独的数据市场以实现可靠的数据安全方案,方法是仅允许用户访问与其相关的特定数据市场,以及消除、模糊处理或匿名化敏感数据。
如果将这些数据市场作为物理表实现,则需要额外的存储资源来存储它们,并需要进行额外的处理来定期生成和刷新。 此外,市场中数据的更新情况仅与最后一次刷新操作保持一致,因此可能不适合高度易失的数据仪表板。
提示
Azure Synapse 的性能和可伸缩性使虚拟化可在不牺牲性能的情况下实现。
随着相对低成本的可缩放 MPP 体系结构(如 Azure Synapse)的出现,以及此类体系结构的固有性能特征,或许可以提供数据市场功能,而无需将市场实例化为一组物理表。 这可以通过在主数据仓库上通过 SQL 视图有效地虚拟化数据市场,或者通过使用 Azure 中的视图或 Microsoft 合作伙伴的可视化产品等功能的虚拟化层实现。 此方法简化了或无需额外的存储和聚合处理,并减少了要迁移的数据库对象总数。
此方法有另一个潜在好处。 通过在虚拟化层内实现聚合和联接逻辑,并通过虚拟化视图呈现外部报告工具,创建这些视图所需的处理会“向下推送”到数据仓库中,而数据仓库通常是对大量数据运行联接、聚合和其他相关操作的最佳位置。
选择虚拟数据市场实现,而不选择物理数据市场的主要驱动因素包括:
更加敏捷:虚拟数据市场比物理表和关联的 ETL 流程更易于更改。
总拥有成本更低:虚拟化实现需要的数据存储和数据副本更少。
无需使用 ETL 作业即可在虚拟化环境中迁移和简化数据仓库体系结构。
性能:尽管物理数据市场历来性能更高,但现在虚拟化产品可实现智能缓存技术来缓解这一问题。
从 Teradata 迁移数据
了解数据
计划迁移时需要详细了解需要迁移的数据量,因为这会影响有关迁移方法的决策。 使用系统元数据来确定要迁移的表内的“原始数据”会占用的物理空间。 在这种情况下,“原始数据”是指表中数据行使用的空间量,不包括索引和压缩等开销。 这对于最大的事实数据表尤其如此,因为这些表通常包含超过 95% 的数据。
可以通过将数据的代表性样本(例如,一百万行)提取到未压缩的分隔平面 ASCII 数据文件中,获取给定表需要迁移的数据量的准确数字。 然后,使用该文件的大小获取该表的每行平均原始数据大小。 最后,将该平均大小乘以全表中的总行数,得出该表的原始数据大小。 在计划中使用该原始数据大小。
ETL 迁移注意事项
有关 Teradata ETL 迁移的初始决策
提示
提前计划 ETL 迁移方法,并在适当的情况下利用 Azure 设施。
对于 ETL/ELT 处理,旧 Teradata 数据仓库可能会通过 Teradata 实用工具(如 BTEQ 和 Teradata Parallel Transporter [TPT])或第三方 ETL 工具(如 Informatica 或 Ab Initio)来使用定制脚本。 有时,Teradata 数据仓库会使用随时间演变的 ETL 和 ELT 方法的组合。 在计划迁移到 Azure Synapse 时,需要确定在新环境中实现所需 ETL/ELT 处理的最佳方式,同时最大程度地降低所涉及的成本和风险。 若要详细了解 ETL 和 ELT 处理,请参阅 ELT 与 ETL 设计方法。
以下部分介绍各种迁移方案,并针对各种用例提出建议。 此流程图汇总了一种方法:
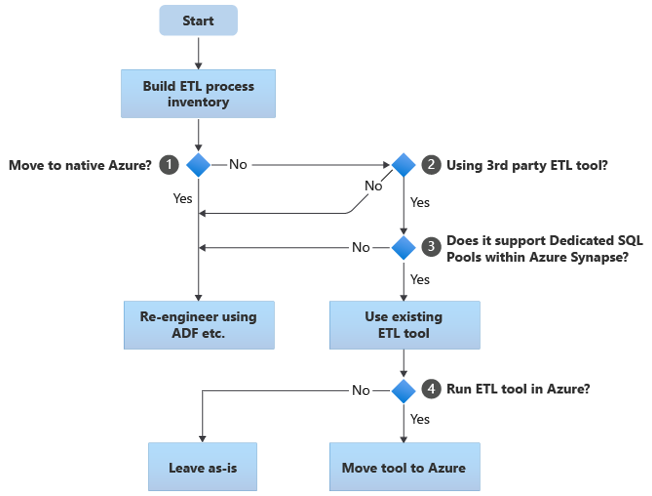
第一步始终是生成需要迁移的 ETL/ELT 流程清单。 与其他步骤一样,标准的“内置”Azure 功能可能不要求迁移某些现有流程。 为了进行计划,请务必了解要执行的迁移规模。
在前面的流程图中,决策 1 涉及关于是否迁移到完全 Azure 原生环境的大致决策。 如果要迁移到完全 Azure 原生环境,建议使用 Azure 数据工厂中的管道和活动或 Azure Synapse 管道重新设计 ETL 处理。 如果不迁移到完全 Azure 原生环境,则决策 2 涉及现有第三方 ETL 工具是否已在使用中。
在 Teradata 环境中,部分或所有 ETL 处理都可能会通过 Teradata 特定实用工具(如 BTEQ 和 TPT)由自定义脚本执行。 在这种情况下,应使用通过数据工厂重新设计的方法。
提示
利用对现有第三方工具的投资来降低成本和风险。
如果已在使用第三方 ETL 工具,特别是如果对技能进行大量投资或有多个现有工作流和计划使用该工具,则决策 3 涉及该工具是否可以高效地支持将 Azure Synapse 作为目标环境。 理想情况下,该工具将包含“本机”连接器,这些连接器可以利用 PolyBase 或 COPY INTO 等 Azure 设施进行最高效的数据加载。 有一种方法可以调用外部进程,例如 PolyBase 或 COPY INTO,并传入相应的参数。 在这种情况下,利用现有技能和工作流,并将 Azure Synapse 作为新的目标环境。
如果决定保留现有第三方 ETL 工具,则在 Azure 环境中(而不是在现有本地 ETL 服务器上)运行该工具并让 Azure 数据工厂处理现有工作流的整体业务流程可能会有好处。 一个特别的好处是需要从 Azure 下载、处理,然后上传回 Azure 的数据更少。 因此,决策 4 涉及是让现有工具按原样运行还是将其移至 Azure 环境以实现成本、性能和可伸缩性方面的好处。
重新设计现有的 Teradata 特定脚本
如果部分或全部的现有 Teradata 仓库 ETL/ELT 处理由使用 Teradata 特定实用工具(如 BTEQ、MLOAD 或 TPT)的自定义脚本处理,则需要为新的 Azure Synapse 环境重新编码这些脚本。 同样,如果 ETL 流程使用 Teradata 中的存储过程实现,则这些过程也必须重新编码。
提示
要迁移的 ETL 任务的清单应包括脚本和存储过程。
ETL 流程的一些元素很容易迁移,例如,通过直接从外部文件将数据批量加载到暂存表中。 甚至可以自动化流程的这些部分,例如,通过使用 PolyBase,而不是快速加载选项或 MLOAD。 如果导出的文件是 Parquet 文件,则可以使用本机 Parquet 读取器,这是比 PolyBase 更快的选择。 流程中包含任意复杂 SQL 和/或存储过程的其他部分将需要更多时间来重新设计。
测试 Teradata SQL 与 Azure Synapse 的兼容性的一种方法是从 Teradata 日志中捕获一些具有代表性的 SQL 语句,然后在这些查询前面加上 EXPLAIN 前缀,接着(假设为 Azure Synapse 中的对等迁移数据模型)在 Azure Synapse 中运行那些 EXPLAIN 语句。 任何不兼容的 SQL 都会生成错误,错误信息可用于确定重新编码任务的规模。
Microsoft 合作伙伴提供工具和服务,用于将 Teradata SQL 和存储过程迁移到 Azure Synapse。
使用第三方 ETL 工具
如上一部分所述,在许多情况下,现有的旧数据仓库系统已由第三方 ETL 产品填充和维护。 有关用于 Azure Synapse 的 Microsoft 数据集成合作伙伴列表,请参阅数据集成合作伙伴。
从 Teradata 加载数据
从 Teradata 加载数据时的可用选项
提示
第三方工具可以简化和自动化迁移过程,从而降低风险。
从 Teradata 数据仓库迁移数据时,需要解决与数据加载相关的一些基本问题。 需要确定如何将数据从现有本地 Teradata 环境物理迁移到云中的 Azure Synapse,以及使用哪些工具来执行传输和加载。 考虑以下问题,这些问题将在下一部分中讨论。
是会将数据提取到文件,还是直接通过网络连接移动数据?
是从源系统还是从 Azure 目标环境协调流程?
将使用哪些工具来自动化和管理该流程?
通过文件还是网络连接传输数据?
提示
了解要迁移的数据量和可用的网络带宽,因为这些因素会影响关于迁移方法的决策。
在 Azure Synapse 中创建要迁移的数据库表后,可以将用于填充这些表的数据移出旧 Teradata 系统,然后移到新环境中。 有两种基本方法:
文件提取:通过 BTEQ、快速导出或 Teradata Parallel Transporter (TPT) 从 Teradata 表将数据提取到平面文件(通常采用 CSV 格式)。 尽可能使用 TPT,因为它在数据吞吐量方面效率最高。
这种方法需要空间来放置提取的数据文件。 此空间可以是 Teradata 源数据库的本地空间(如果有足够的存储空间),也可以是 Azure Blob 存储中的远程空间。 在本地写入文件时,可实现最佳性能,因为这样就避免了网络开销。
若要最大程度地减少存储和网络传输需求,最好使用 gzip 等实用工具压缩提取的数据文件。
提取后,平面文件可移动到 Azure Blob 存储(与目标 Azure Synapse 实例位于同一位置),或使用 PolyBase 或 COPY INTO 直接加载到 Azure Synapse。 将数据从本地存储物理移动到 Azure 云环境的方法取决于数据量和可用的网络带宽。
Microsoft 提供了用于迁移大量数据的不同选项,包括用于将文件通过网络移动到 Azure 存储的 AZCopy、用于通过专用网络连接批量迁移数据的 Azure ExpressRoute,以及在其中将文件移动到物理存储设备,然后交付到 Azure 数据中心进行加载的 Azure Data Box。 有关详细信息,请参阅数据传输。
通过网络直接提取和加载:目标 Azure 环境将数据提取请求发送(通常通过 SQL 命令)到旧 Teradata 系统以提取数据。 结果通过网络发送并直接加载到 Azure Synapse,而无需将数据放置到中间文件中。 通常,此方案的限制因素为 Teradata 数据库与 Azure 环境之间的网络连接带宽。 对于数据量非常大的情况,此方法可能不实用。
还有一种利用这两种方法的混合方法。 例如,可以针对较小的维度表和较大的事实数据表样本使用直接网络提取方法,以便在 Azure Synapse 中快速提供测试环境。 对于大量历史事实数据表,可以通过 Azure Data Box 使用文件提取和传输方法。
通过 Teradata 还是 Azure 协调?
迁移到 Azure Synapse 时的建议方法是使用 Azure Synapse 管道或 Azure 数据工厂以及关联的实用工具(如 PolyBase 或 COPY INTO)来协调从 Azure 环境提取和加载数据的过程,从而实现最高效的数据加载。 此方法利用 Azure 功能,并提供一种简单的方法来生成可重用的数据加载管道。
此方法的其他好处包括,在数据加载过程中减少对 Teradata 系统的影响(因为管理和加载过程在 Azure 中运行),以及能够使用元数据驱动的数据加载管道自动执行该过程。
可以使用哪些工具?
完成数据转换和移动是所有 ETL 产品的基本功能。 如果其中一个产品已在现有 Teradata 环境中使用,则使用现有 ETL 工具可以简化从 Teradata 到 Azure Synapse 的数据迁移。 此方法假定 ETL 工具支持将 Azure Synapse 用作目标环境。 有关支持 Azure Synapse 的工具的详细信息,请参阅数据集成合作伙伴。
如果使用 ETL 工具,请考虑在 Azure 环境中运行该工具,以获得 Azure 云性能、可伸缩性和成本方面的好处,并释放 Teradata 数据中心的资源。 另一个好处是减少了云和本地环境之间的数据移动。
总结
概括而言,有关将数据和关联的 ETL 流程从 Teradata 迁移到 Azure Synapse 的建议如下:
提前计划,确保迁移操作成功。
尽快生成要迁移的数据和流程的详细清单。
使用系统元数据和日志文件准确了解数据和流程使用情况。 不要依赖文档,因为文档可能已过时。
了解要迁移的数据量,以及本地数据中心和 Azure 云环境之间的网络带宽。
考虑使用 Azure VM 中的 Teradata 实例作为从旧 Teradata 环境卸载迁移的跳板。
利用标准的“内置”Azure 功能,以最大限度地减少迁移工作负载。
确定并了解在 Teradata 和 Azure 环境中提取和加载数据的最高效工具。 在过程中的每个阶段使用相应的工具。
使用 Azure 设施(如 Azure Synapse 管道或 Azure 数据工厂)协调和自动化迁移过程,同时最大程度地降低对 Teradata 系统的影响。
后续步骤
若要详细了解安全访问操作,请参阅本系列中的下一篇文章:Teradata 迁移的安全性、访问权限和操作。