你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本教程介绍如何使用 Azure 开放数据集和 Apache Spark 执行探索数据分析。 然后,可以在 Azure Synapse Analytics 的 Synapse Studio 笔记本中可视化结果。
具体而言,我们将分析 纽约市(NYC)出租车 数据集。 数据通过 Azure 开放数据集提供。 此数据集子集包含有关黄色出租车行程的信息:有关每次行程、开始和结束时间、位置、成本和其他令人感兴趣的属性的信息。
在您开始之前
按照 “创建 Apache Spark 池”教程创建 Apache Spark 池。
下载并准备数据
使用 PySpark 内核创建笔记本。 有关说明,请参阅创建笔记本。
注释
由于使用的是 PySpark 内核,因此不需要显式创建任何上下文。 运行第一个代码单元格时,系统会自动创建 Spark 上下文。
在本教程中,我们将使用多个不同的库来帮助可视化数据集。 若要执行此分析,请导入以下库:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd由于原始数据采用 Parquet 格式,因此可以使用 Spark 上下文将文件作为数据帧直接拉取到内存中。 通过开放数据集 API 检索数据来创建 Spark 数据帧。 在这里,我们在 读取属性上使用 Spark 数据帧架构来推断数据类型和架构。
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())读取数据后,我们需要执行一些初始筛选来清理数据集。 我们可能会删除不需要的列并添加提取重要信息的列。 此外,我们将筛选出数据集中的异常。
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
分析数据
作为数据分析人员,你可以使用多种工具从数据中提取见解。 在本教程的这一部分中,我们将演练 Azure Synapse Analytics 笔记本中提供的一些有用工具。 在此分析中,我们希望了解在所选时段哪些因素会产生更高的出租车小费。
Apache Spark SQL Magic
首先,我们将使用 Azure Synapse 笔记本执行 Apache Spark SQL 和 magic 命令的探索数据分析。 有了查询后,我们将使用内置 chart options 功能直观显示结果。
在笔记本中,创建新单元格并复制以下代码。 使用此查询,我们希望了解在所选时间段内平均小费金额是如何变化的。 此查询还将帮助我们识别其他有用的见解,包括每天的最低/最大小费金额和平均票价金额。
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASC查询完成运行后,可以通过切换到图表视图来可视化结果。 此示例通过将
day_of_month字段指定为键并将avgTipAmount指定为值来创建折线图。 选择后,选择“ 应用 ”以刷新图表。
可视化数据
除了内置的笔记本图表选项外,你还可以使用常用的开放源代码库来创建自己的可视化效果。 在以下示例中,我们将使用 Seaborn 和 Matplotlib。 常用的Python库用于数据可视化。
注释
默认情况下,Azure Synapse Analytics 中的每个 Apache Spark 池都包含一组常用库和默认库。 可以在 Azure Synapse 运行时 文档中查看库的完整列表。 此外,若要使第三方或本地生成的代码可供应用程序使用,可以将 库安装 到其中一个 Spark 池中。
为了简化和降低开发成本,我们将向下采样数据集。 我们将使用内置的 Apache Spark 采样功能。 此外,Seaborn 和 Matplotlib 都需要 Pandas 数据帧或 NumPy 数组。 若要获取 Pandas 数据帧,请使用
toPandas()命令来转换数据帧。# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()我们希望了解数据集中小费的分布情况。 我们将使用 Matplotlib 创建显示小费金额和计数分布的直方图。 根据分布情况,我们可以看到小费偏向于小于或等于 $10 的金额。
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()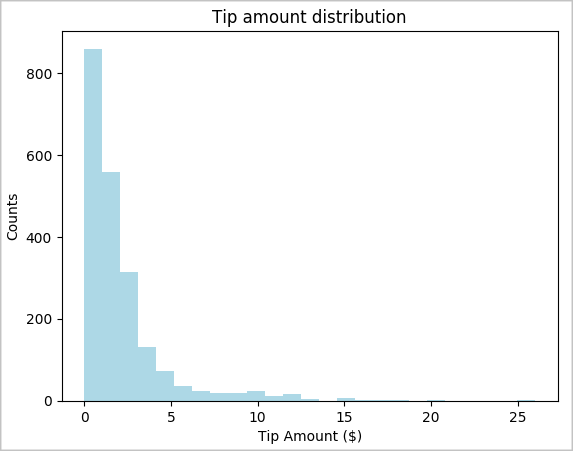
接下来,我们想要了解给定行程的小费与一周中的某一天的关系。 请使用 Seaborn 创建一个箱线图,用于汇总一周中每一天的趋势。
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()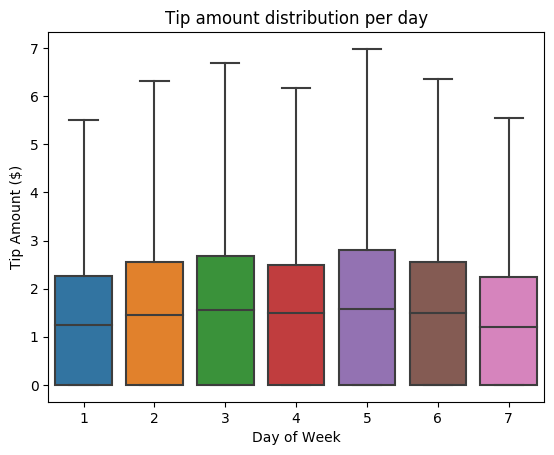
我们的另一个假设可能是乘客数量与出租车小费总额之间存在积极关系。 为了验证此关系,请运行以下代码以生成一个盒须图,以展示按乘客计数的小费分布情况。
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()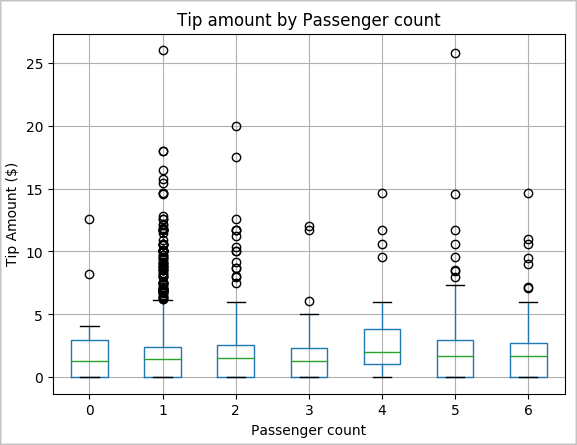
最后,我们希望了解票价金额与小费金额之间的关系。 根据结果,我们可以看到有几个观察表明人们没有给小费。 但是,我们还看到了整体票价和小费金额之间的积极关系。
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()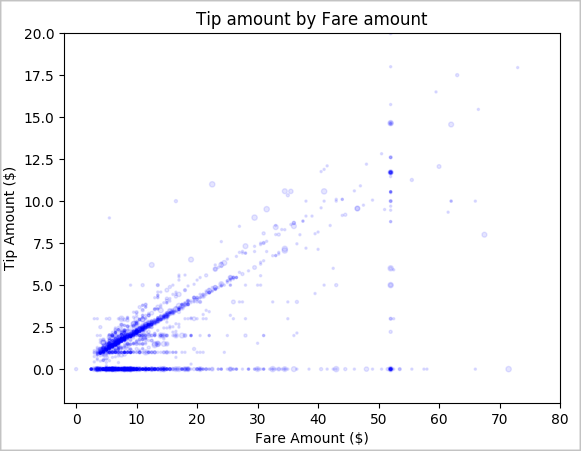
关闭 Spark 实例
运行完应用程序后,关闭笔记本以释放资源。 关闭选项卡,或者从笔记本底部的状态面板中选择 “结束会话 ”。