你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Apache Spark 是并行处理框架,支持使用内存中处理来提升大数据分析应用程序的性能。 Azure Synapse Analytics 中的 Apache Spark 是 Apache Spark 在云中的一种 Microsoft 实现。
Azure Synapse 现在提供了创建已启用 GPU 的 Azure Synapse 池的功能,以使用底层 RAPIDS 库运行 Spark 工作负载,这些库使用 GPU 的大规模并行处理能力来加速处理。 借助 RAPIDS Accelerator for Apache Spark,只需启用一个为已启用 GPU 的池预先配置的配置设置,即可在不更改任何代码的情况下运行现有 Spark 应用程序。 通过设置以下配置,可以选择为工作负载或部分工作负载打开/关闭基于 RAPIDS 的 GPU 加速:
spark.conf.set('spark.rapids.sql.enabled','true/false')
注意
已启用 Azure Synapse GPU 的池的预览版现已弃用。
RAPIDS加速器用于Apache Spark
Spark RAPIDS 加速器是一种插件,其工作原理是通过支持的 GPU 操作重写 Spark 作业的物理计划,并在 GPU 上运行这些操作,从而加速处理。 此库目前处于预览状态,不支持所有 Spark 操作(此处是当前支持的运算符列表,更多支持正通过新发布增量添加)。
群集配置选项
RAPIDS 加速器插件仅支持 GPU 与执行程序之间的一对一映射。 这意味着 Spark 作业将需要请求可由池资源容纳的执行程序和驱动程序资源(根据可用 GPU 和 CPU 核心的数目)。 为了满足此条件并确保实现所有池资源的最优利用,我们需要为在已启用 GPU 的池上运行的 Spark 应用程序配置以下驱动程序和执行程序:
| 池大小 | 驱动程序大小选项 | 驱动程序核心 | 驱动程序内存 (GB) | 执行程序核心数 | 执行程序内存 (GB) | 执行程序数 |
|---|---|---|---|---|---|---|
| GPU-Large | 小型驱动程序 | 4 | 30 | 12 | 六十 | 池中的节点数 |
| GPU-Large | 中型驱动程序 | 7 | 30 | 9 | 六十 | 池中的节点数 |
| GPU-XLarge | 中型驱动程序 | 8 | 40 | 14 | 80 | 4 * 池中的节点数 |
| GPU-XLarge | 大型驱动程序 | 12 | 40 | 13 | 80 | 4 * 池中的节点数 |
任何不满足上述配置之一的工作负载都将被拒绝。 这样做是为了确保使用池中的所有可用资源以最高效且性能最佳的配置运行 Spark 作业。
用户可以通过其工作负载设置上述配置。 对于笔记本,用户可以使用 %%configure magic 命令设置上述配置之一,如下所示。
例如,使用包含 3 个节点的大型池:
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
在 Azure Synapse GPU 加速池中通过笔记本运行示例 Spark 作业
在继续本部分之前,最好先熟悉有关如何在 Azure Synapse Analytics 中使用笔记本的基本概念。 让我们演练一下使用 GPU 加速来运行 Spark 应用程序的步骤。 可以使用 Synapse、PySpark (Python)、Spark (Scala)、SparkSQL 和 .NET for Spark (C#) 中支持的所有四种语言来编写 Spark 应用程序。
创建启用了 GPU 的池。
创建笔记本并将其附加到在第一步中创建的已启用 GPU 的池。
按照上一部分中所述设置配置。
通过在笔记本的第一个单元格中复制以下代码来创建示例数据帧:
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- 现在,让我们通过获取每个部门 ID 的最高薪资来进行聚合,并显示结果:
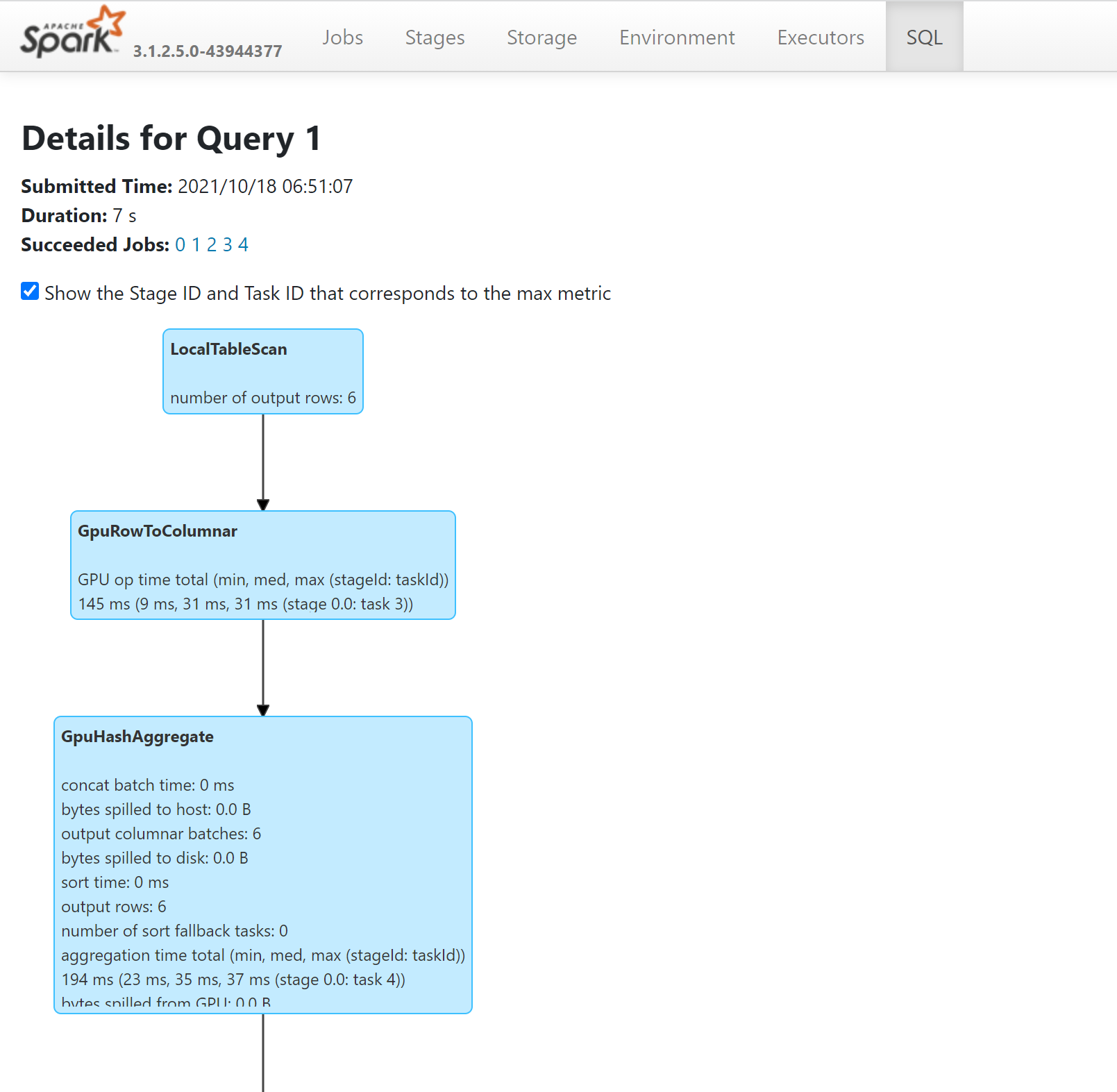
- 通过 Spark History Server 查看 SQL 计划,可以查看在 GPU 上运行的查询中的操作:
如何针对 GPU 调整应用程序
大多数 Spark 作业都可以通过从默认设置调整配置设置来提高性能,而利用适用于 Apache Spark 的 RAPIDS 加速器插件的作业也是如此。
已启用 GPU 的 Azure Synapse 池中的配额和资源约束
工作区级别
每个 Azure Synapse 工作区的默认配额为 50 个 GPU vCore。 为了增加你的 GPU 内核配额,请通过 Azure 门户提交支持请求。