你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Tip
Microsoft Fabric Data Warehouse是数据湖基础上的企业规模关系仓库,具有未来就绪的体系结构、内置 AI 和新功能。 如果不熟悉数据仓库,请从Fabric Data Warehouse开始。 现有的指定 SQL 池工作负荷可以升级到 Fabric,以跨数据科学、实时分析和报告访问新功能。
外部表指向位于 Hadoop、Azure 存储 Blob 或 Azure Data Lake Storage (ADLS) 中的数据。
可以使用外部表读取文件中的数据,或将数据写入 Azure 存储中的文件。 借助 Azure Synapse SQL,可以使用外部表通过专用 SQL 池或无服务器 SQL 池读取外部数据。
根据外部数据源的类型,可以使用两种类型的外部表:
- Hadoop 外部表,可用于读取和导出各种数据格式(例如 CSV、Parquet 和 ORC)的数据。 Hadoop 外部表可在专用 SQL 池中使用,但无法在无服务器 SQL 池中使用。
- 原生外部表,可用于读取和导出各种数据格式(如 CSV 和 Parquet)的数据。 本机外部表可在无服务器 SQL 池和专用 SQL 池中使用。 使用 CETAS 和原生外部表编写/导出数据仅在无服务器 SQL 池中适用,但不适用于专用 SQL 池。
Hadoop 和原生外部表之间的主要区别:
| 外部表类型 | Hadoop | 原生 |
|---|---|---|
| 专用 SQL 池 | 可用 | 仅 Parquet |
| 无服务器 SQL 池 | 不可用 | 可用 |
| 支持的格式 | 带分隔符/CSV、Parquet、ORC、Hive RC 和 RC | 无服务器 SQL 池:带分隔符/CSV、Parquet 和 Delta Lake 专用 SQL 池:Parquet |
| 文件夹分区清除 | 否 | 分区消除仅适用于根据从 Apache Spark 池同步的 Parquet 或 CSV 格式创建的已分区表。 可以在 Parquet 分区文件夹上创建外部表,不过分区列无法访问且会被忽略,并且不会执行分区消除。 不要在 Delta Lake 文件夹上创建外部表,因为它们不受支持。 如果需要查询已分区的 Delta Lake 数据,请使用 Delta 已分区视图。 |
| 文件消除(谓词下推) | 否 | 在无服务器 SQL 池中为“是”。 对于字符串下推,需要对 Latin1_General_100_BIN2_UTF8 列使用 VARCHAR 排序规则来启用下推。 有关排序规则的详细信息,请参阅对 Azure Synapse Analytics 中 Synapse SQL 的数据库排序规则支持。 |
| 适用于位置的自定义格式 | 否 | 是,对 Parquet 或 CSV 格式使用通配符,例如 /year=*/month=*/day=*。 Delta Lake 中不提供自定义文件夹路径。 在无服务器 SQL 池中,还可以使用递归通配符 /logs/** 来引用所引用文件夹下任何子文件夹中的 Parquet 或 CSV 文件。 |
| 递归文件夹扫描 | 是 | 是的。 在无服务器 SQL 池中,必须在位置路径末尾指定 /**。 在专用池中,文件夹始终递归地被扫描。 |
| 存储身份验证 | 存储访问密钥 (SAK)、Microsoft Entra 直通、托管标识、自定义应用程序 Microsoft Entra 标识 | 共享访问签名 (SAS)、Microsoft Entra 直通、托管标识、自定义应用程序 Microsoft Entra 标识。 |
| 列映射 | 序号 - 外部表定义中的列按位置映射到基础 Parquet 文件中的列。 | 无服务器池:按名称。 外部表定义中的列按列名匹配映射到基础 Parquet 文件中的列。 专用池:序号匹配。 外部表定义中的列按位置映射到基础 Parquet 文件中的列。 |
| CETAS(导出/转换) | 是 | 以原生表为目标的 CETAS 仅适用于无服务器 SQL 池。 不能使用专用 SQL 池通过原生表导出数据。 |
注意
本机外部表是池中推荐的解决方案,它们已正式发布。 如果需要访问外部数据,请始终在无服务器架构或专用池中使用原生表。 仅当需要访问原生外部表中不支持的一些类型(例如 ORC、RC)或原生版本不可用时,才使用 Hadoop 表。
专用 SQL 池和无服务器 SQL 池中的外部表
可以使用外部表来执行以下操作:
- 使用 Transact-SQL 语句查询 Azure Blob 存储和 ADLS Gen2。
- 使用 Synapse SQL 提供的 CETAS 将查询结果存储到 Azure Blob 存储或 Azure Data Lake Storage 中的文件。
- 从 Azure Blob 存储和 Azure Data Lake Storage 导入数据并将其存储到专用 SQL 池中(仅限专用池中的 Hadoop 表)。
注意
在与 CREATE TABLE AS SELECT 语句结合使用时,从外部表进行选择可将数据导入到专用 SQL 池中的表。
如果专用池中 Hadoop 外部表的性能无法满足性能目标,请考虑使用 COPY 语句将外部数据加载到数据仓库表中。
有关加载操作的教程,请参阅使用 PolyBase 从 Azure Blob 存储加载数据。
可通过以下步骤在 Synapse SQL 池中创建外部表:
- CREATE EXTERNAL DATA SOURCE 以引用外部 Azure 存储并指定应当用来访问该存储的凭据。
- CREATE EXTERNAL FILE FORMAT 以描述 CSV 或 Parquet 文件的格式。
- 基于以相同文件格式放置在数据源上的文件来 CREATE EXTERNAL TABLE。
文件夹分区清除
Synapse 池中的原生外部表能够忽略放置在与查询无关的文件夹中的文件。 如果文件存储在文件夹层次结构(例如 - /year=2020/month=03/day=16)中,并且 year、month 和 day 的值作为列公开,则包含筛选器(例如 year=2020)的查询将只读取放置在 year=2020 文件夹的子文件夹中的文件。 在此查询中,将忽略放置在其他文件夹(year=2021 或 year=2022)中的文件和文件夹。 此消除称为“分区消除”。
文件夹分区消除在从 Synapse Spark 池同步的本机外部表中可用。 如果已对数据集进行分区,并且希望将分区消除用于所创建的外部表,请使用分区视图而不是外部表。
文件删除
某些数据格式(例如 Parquet 和 Delta)包含每列的文件统计信息(例如,每列的最小/最大值)。 筛选数据的查询不会读取不存在所需列值的文件。 查询将首先浏览查询谓词中使用的列的最小/最大值,以查找不包含所需数据的文件。 这些文件将被忽略并从查询计划中消除。
此方法也称为筛选器谓词下推,它可以提高查询的性能。 在 Parquet 和 Delta 格式的无服务器 SQL 池中提供过滤器下推功能。 若要为字符串类型应用筛选器下推,请将 VARCHAR 类型与 Latin1_General_100_BIN2_UTF8 排序规则一起使用。 有关排序规则的详细信息,请参阅对 Azure Synapse Analytics 中 Synapse SQL 的数据库排序规则支持。
安全性
用户必须具有对外部表的 SELECT 权限才能读取数据。
外部表使用数据库范围的凭据访问基础 Azure 存储,这些凭据使用以下规则在数据源中定义:
- 没有凭据的数据源使外部表可访问 Azure 存储上公开可用的文件。
- 数据源可能有一个凭据,外部表可以使用该凭据通过 SAS 令牌或工作区托管标识仅访问 Azure 存储上的文件 - 有关示例,请参阅开发存储文件存储访问控制一文。
注解
为了确保可靠的查询执行,外部表引用的源文件和文件夹在作期间必须保持不变。
- 在查询运行时修改、删除或替换任何引用的文件或文件夹可能会导致失败或导致结果不一致。
- 在查询专用 SQL 池中的外部表之前,请验证所有源数据是否稳定,在执行期间不会更改。
外部数据源创建示例
以下示例在专用 SQL 池中为 ADLS Gen2 创建一个指向公共纽约数据集的 Hadoop 外部数据源:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
以下示例为 ADLS Gen2 创建一个指向公开可用的纽约数据集的外部数据源:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
CREATE EXTERNAL FILE FORMAT 的示例
以下示例为人口普查文件创建外部文件格式:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
CREATE EXTERNAL TABLE 示例
以下示例创建一个外部表。 它返回第一行:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
从 Azure Data Lake 中的文件创建和查询外部表
现在,使用 Synapse Studio 的 Data Lake 浏览功能,可以通过右键单击文件使用 Synapse SQL 池创建和查询外部表。 仅 Parquet 文件支持通过单击手势从 ADLS Gen2 存储帐户创建外部表。
先决条件
你必须有权访问工作区,并且至少具有
Storage Blob Data Contributor访问角色(拥有对 ADLS Gen2 帐户或访问控制列表 (ACL) 的访问权限),然后才能查询这些文件。必须至少拥有在 Synapse SQL 池(专用或无服务器)中创建外部表的权限和查询外部表的权限。
在“数据”面板中,选择要从其创建外部表的文件:

此时会打开一个对话框窗口。 选择“专用 SQL 池”或“无服务器 SQL 池”,为表命名,然后选择“打开脚本”:
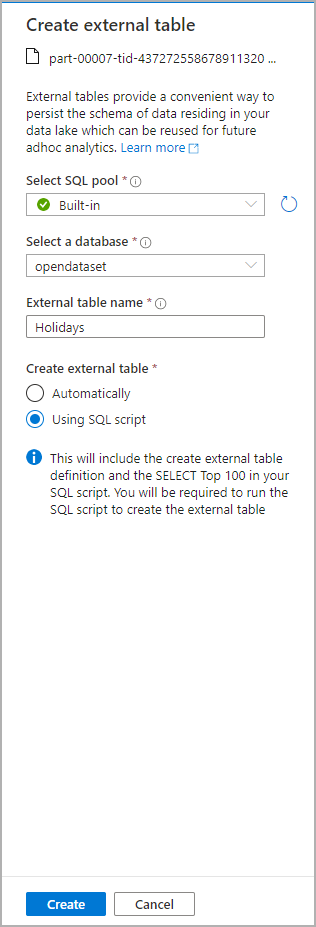
系统会从该文件推理架构并自动生成 SQL 脚本:

运行该脚本。 脚本将自动运行 SELECT TOP 100 *:

现在已创建外部表。 现在可以直接从数据窗格查询外部表。
相关内容
查看 CETAS 一文,了解如何将查询结果保存到 Azure 存储中的外部表。 或者可以开始查询 Apache Spark for Azure Synapse 外部表。