C++ 允许在同一范围内指定多个同名函数。 这些函数称为重载函数或重载。 利用重载函数,你可以根据参数的类型和数量为函数提供不同的语义。
以采用 print 参数的 std::string 函数为例。 此函数执行的任务可能与采用 double 类型参数的函数大不相同。 通过重载,不必使用诸如 print_string 或 print_double 之类的名称。 在编译时,编译器会根据调用方传入的参数类型和数量选择要使用的重载。 如果你调用 print(42.0),则会调用 void print(double d) 函数。 如果你调用 print("hello world"),则会调用 void print(std::string) 重载。
可以重载成员函数和自由函数。 下表显示了 C++ 使用函数声明的哪些部分来区分同一范围内具有相同名称的函数组。
重载注意事项
| 函数声明元素 | 是否用于重载? |
|---|---|
| 函数返回类型 | 否 |
| 自变量的数量 | 是 |
| 自变量的类型 | 是 |
| 省略号存在或缺失 | 是 |
typedef 名称的使用 |
否 |
| 未指定的数组边界 | 否 |
const 或 volatile |
是,应用于整个函数时 |
引用限定符(& 和 &&) |
是 |
示例
以下示例演示了如何使用函数重载:
// function_overloading.cpp
// compile with: /EHsc
#include <iostream>
#include <math.h>
#include <string>
// Prototype three print functions.
int print(std::string s); // Print a string.
int print(double dvalue); // Print a double.
int print(double dvalue, int prec); // Print a double with a
// given precision.
using namespace std;
int main(int argc, char *argv[])
{
const double d = 893094.2987;
if (argc < 2)
{
// These calls to print invoke print( char *s ).
print("This program requires one argument.");
print("The argument specifies the number of");
print("digits precision for the second number");
print("printed.");
exit(0);
}
// Invoke print( double dvalue ).
print(d);
// Invoke print( double dvalue, int prec ).
print(d, atoi(argv[1]));
}
// Print a string.
int print(string s)
{
cout << s << endl;
return cout.good();
}
// Print a double in default precision.
int print(double dvalue)
{
cout << dvalue << endl;
return cout.good();
}
// Print a double in specified precision.
// Positive numbers for precision indicate how many digits
// precision after the decimal point to show. Negative
// numbers for precision indicate where to round the number
// to the left of the decimal point.
int print(double dvalue, int prec)
{
// Use table-lookup for rounding/truncation.
static const double rgPow10[] = {
10E-7, 10E-6, 10E-5, 10E-4, 10E-3, 10E-2, 10E-1,
10E0, 10E1, 10E2, 10E3, 10E4, 10E5, 10E6 };
const int iPowZero = 6;
// If precision out of range, just print the number.
if (prec < -6 || prec > 7)
{
return print(dvalue);
}
// Scale, truncate, then rescale.
dvalue = floor(dvalue / rgPow10[iPowZero - prec]) *
rgPow10[iPowZero - prec];
cout << dvalue << endl;
return cout.good();
}
上述代码显示了文件范围内 print 函数的重载。
默认参数不被视为函数类型的一部分。 因此,它不用于选择重载函数。 仅在默认自变量上存在差异的两个函数被视为多个定义而不是重载函数。
不能为重载运算符提供默认参数。
自变量匹配
编译器根据当前范围内的函数声明与函数调用中提供的参数的最佳匹配,来选择要调用的重载函数。 如果找到合适的函数,则调用该函数。 此上下文中的“Suitable”具有下列含义之一:
找到完全匹配项。
已执行不重要的转换。
已执行整型提升。
已存在到所需自变量类型的标准转换。
已存在到所需参数类型的用户定义转换(转换运算符或构造函数)。
已找到省略号所表示的自变量。
编译器为每个自变量创建一组候选函数。 候选函数是这样一种函数,其中的实际自变量可以转换为形式自变量的类型。
为每个自变量生成一组“最佳匹配函数”,并且所选函数是所有集的交集。 如果交集包含多个函数,则重载是不明确的并会生成错误。 对于至少一个参数而言,最终选择的函数始终比组中的所有其他函数更匹配。 如果没有明显的优胜者,函数调用会生成编译器错误。
考虑下面的声明(针对下面的讨论中的标识,将函数标记为 Variant 1、Variant 2 和 Variant 3):
Fraction &Add( Fraction &f, long l ); // Variant 1
Fraction &Add( long l, Fraction &f ); // Variant 2
Fraction &Add( Fraction &f, Fraction &f ); // Variant 3
Fraction F1, F2;
请考虑下列语句:
F1 = Add( F2, 23 );
前面的语句生成两个集:
集 1:其第一个参数的类型为 Fraction 的候选函数 |
集 2:其第二个参数可转换为类型 int 的候选函数 |
|---|---|
| 变体 1 | Variant 1(可使用标准转换将 int 转换为 long) |
| 变体 3 |
集 2 中的函数具有从实参类型到形参类型的隐式转换。 其中一个函数将实参类型转换为相应形参类型的“成本”最小。
这两个集的交集为 Variant 1。 不明确的函数调用的示例为:
F1 = Add( 3, 6 );
前面的函数调用生成以下集:
集 1:其第一个参数的类型为 int 的候选函数 |
集 2:其第二个参数的类型为 int 的候选函数 |
|---|---|
Variant 2(可使用标准转换将 int 转换为 long) |
Variant 1(可使用标准转换将 int 转换为 long) |
由于这两个集的交集为空,因此编译器会生成错误消息。
对于参数匹配,具有 n 个默认参数的函数被视为 n+1 个单独函数,并且每个函数均具有不同数量的参数。
省略号 (...) 用作通配符;它与任何实参匹配。 如果你未极其谨慎地设计重载函数集,它可能导致产生许多不明确的集。
注意
重载函数的多义性无法确定,直到遇到函数调用。 此时,将为函数调用中的每个自变量生成集,并且可以确定是否存在明确的重载。 这意味着,多义性可能会保留在代码中,直到它们由特定函数调用引发。
参数类型差异
重载函数区分使用不同的初始值设定项的自变量类型。 因此,对于重载而言,给定类型的自变量和对该类型的引用将视为相同。 由于它们采用相同的初始值设定项,因此它们被视为是相同的。 例如,max( double, double ) 被视为与 max( double &, double & ) 相同。 声明两个此类函数会导致错误。
出于同一原因,对于重载而言,由 const 或 volatile 修饰的类型的函数参数的处理方式与基类型没有什么不同。
但是,函数重载机制可以区分由 const 和 volatile 限定的引用和对基类型的引用。 它可以实现如下代码:
// argument_type_differences.cpp
// compile with: /EHsc /W3
// C4521 expected
#include <iostream>
using namespace std;
class Over {
public:
Over() { cout << "Over default constructor\n"; }
Over( Over &o ) { cout << "Over&\n"; }
Over( const Over &co ) { cout << "const Over&\n"; }
Over( volatile Over &vo ) { cout << "volatile Over&\n"; }
};
int main() {
Over o1; // Calls default constructor.
Over o2( o1 ); // Calls Over( Over& ).
const Over o3; // Calls default constructor.
Over o4( o3 ); // Calls Over( const Over& ).
volatile Over o5; // Calls default constructor.
Over o6( o5 ); // Calls Over( volatile Over& ).
}
输出
Over default constructor
Over&
Over default constructor
const Over&
Over default constructor
volatile Over&
对于重载而言,指向 const 和 volatile 对象的指针也被认为与指向基类型的指针不同。
自变量匹配和转换
当编译器尝试根据函数声明中的参数匹配实际参数时,如果未找到任何确切匹配项,它可以提供标准转换或用户定义的转换来获取正确类型。 转换的应用程序受这些规则的限制:
不考虑包含多个用户定义转换的转换序列。
不考虑可通过删除中间转换来缩短的转换序列。
最终的转换序列(如果有)称为最佳匹配序列。 可通过多种方式使用标准转换将 int 类型的对象转换为 unsigned long 类型的对象(如标准转换中所述):
从
int转换为long,然后从long转换为unsigned long。从
int转换为unsigned long。
虽然第一个序列达到了预期的目标,但它不是最佳匹配序列,因为存在更短的序列。
下表显示了一组称为常用转换的转换。 常用转换对编译器选择哪个序列作为最佳匹配的影响有限。 表后说明了常用转换的效果。
常用转换
| 参数类型 | 转换后的类型 |
|---|---|
type-name |
type-name& |
type-name& |
type-name |
type-name[] |
type-name* |
type-name(argument-list) |
(*type-name)(argument-list) |
type-name |
const type-name |
type-name |
volatile type-name |
type-name* |
const type-name* |
type-name* |
volatile type-name* |
在其中尝试转换的序列如下:
完全匹配。 用于调用函数的类型与函数原型中声明的类型之间的完全匹配始终是最佳匹配。 常用转换的序列将归类为完全匹配。 但是,不进行任何这些转换的序列被视为比进行转换的序列更佳:
从指针,到指向
const的指针(type-name*到const type-name*)。从指针,到指向
volatile的指针(type-name*到volatile type-name*)。从引用,到对
const的引用(type-name&到const type-name&)。从引用,到对
volatile的引用(type-name&到volatile type&)。
使用提升的匹配。 未归类为仅包含整型提升、从
float到double的转换以及常用转换的完全匹配的任何序列都被归类为使用提升的匹配。 尽管比不上完全匹配,但使用提升的匹配仍优于使用标准转换的匹配。使用标准转换的匹配。 未归类为完全匹配或仅包含标准转换和常用转换的使用提升的匹配的序列将归类为使用标准转换的匹配。 在此类别中,以下规则将适用:
从指向派生类的指针到指向直接或间接基类的指针的转换优于到
void *或const void *的转换。从指向派生类的指针到指向基类的指针的转换会产生一个到直接基类的更好匹配。 假定类层次结构如下图所示:

显示首选转换的图形。
从 D* 类型到 C* 类型的转换优于从 D* 类型到 B* 类型的转换。 同样,从 D* 类型到 B* 类型的转换优于从 D* 类型到 A* 类型的转换。
此同一规则适用于引用转换。 从 D& 类型到 C& 类型的转换优于从 D& 类型到 B& 类型的转换等。
此同一规则适用于指向成员的指针转换。 从 T D::* 类型到 T C::* 类型的转换优于从 T D::* 类型到 T B::* 类型的转换等(其中,T 是该成员的类型)。
前面的规则仅沿派生的给定路径应用。 考虑下图中显示的关系图。
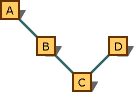
显示首选转换的多重继承图。
从 C* 类型到 B* 类型的转换优于从 C* 类型到 A* 类型的转换。 原因是它们位于同一个路径上,且 B* 更为接近。 但是,从 C* 类型到 D* 类型的转换不优于到 A* 类型的转换;没有首选项,因为这些转换遵循不同的路径。
使用用户定义的转换的匹配。 此序列不能归类为完全匹配、使用提升的匹配或使用标准转换的匹配。 若要归类为使用用户定义转换的匹配,序列必须仅包含用户定义的转换、标准转换或常用转换。 使用用户定义转换的匹配被认为优于使用省略号 (
...) 的匹配,但比不上使用标准转换的匹配。使用省略号的匹配。 与声明中的省略号匹配的任何序列将归类为使用省略号的匹配。 它被视为最弱匹配。
如果内置提升或转换不存在,则用户定义的转换将适用。 这些转换是根据要匹配的参数的类型来选择的。 考虑下列代码:
// argument_matching1.cpp
class UDC
{
public:
operator int()
{
return 0;
}
operator long();
};
void Print( int i )
{
}
UDC udc;
int main()
{
Print( udc );
}
类 UDC 的可用用户定义转换来自 int 类型和 long 类型。 因此,编译器会考虑针对将匹配的对象类型的转换:UDC。 到 int 的转换已存在且已被选中。
在匹配参数的过程中,标准转换可应用于参数和用户定义的转换的结果。 因此,下面的代码将适用:
void LogToFile( long l );
...
UDC udc;
LogToFile( udc );
在此示例中,编译器调用用户定义的转换 operator long,将 udc 转换为 long 类型。 如果未定义到 long 类型的用户定义转换,编译器会先使用用户定义的 UDC 转换将 int 类型转换为 operator int 类型。 然后应用从 int 类型到 long 类型的标准转换,以匹配声明中的参数。
如果需要任何用户定义的转换来匹配参数,则在计算最佳匹配时不会使用标准转换。 即使多个候选函数需要用户定义的转换,这些函数也被认为是相等的。 例如:
// argument_matching2.cpp
// C2668 expected
class UDC1
{
public:
UDC1( int ); // User-defined conversion from int.
};
class UDC2
{
public:
UDC2( long ); // User-defined conversion from long.
};
void Func( UDC1 );
void Func( UDC2 );
int main()
{
Func( 1 );
}
Func 的两个版本都需要用户定义的转换,以将 int 类型转换为类类型参数。 可能的转换包括:
从
int类型转换为UDC1类型(用户定义的转换)。从
int类型转换为long类型;然后转换为UDC2类型(两步转换)。
即使第二个转换需要标准转换和用户定义的转换,这两个转换仍被视为相等。
注意
用户定义的转换被认为是构造转换或初始化转换。 编译器在确定最佳匹配时,会将这两种方法视为相等。
参数匹配和 this 指针
处理类成员函数的方式各不相同,具体取决于它们是否已被声明为 static。
static 函数没有提供 this 指针的隐式参数,因此它们被认为比常规成员函数少一个参数。 在其他方面,它们的声明相同。
不是 static 的成员函数要求隐含的 this 指针与调用该函数的对象类型相匹配。 或者,对于重载运算符,它们要求第一个参数与应用运算符的对象相匹配。 有关重载运算符的详细信息,请参阅重载运算符。
与重载函数中的其他参数不同,编译器在尝试匹配 this 指针参数时,不会引入临时对象,也不会尝试转换。
当 -> 成员选择运算符用于访问类 class_name 的成员函数时,this 指针参数具有 class_name * const 的类型。 如果将成员声明为 const 或 volatile,则类型分别为 const class_name * const 和 volatile class_name * const。
. 成员选择运算符以相同的方式工作,只不过隐式 & (address-of) 运算符将成为对象名称的前缀。 下面的示例演示了此工作原理:
// Expression encountered in code
obj.name
// How the compiler treats it
(&obj)->name
处理 ->* 和 .*(指向成员的指针)运算符的左操作数的方式与处理与参数匹配相关的 . 和 ->(成员选择)运算符的方式相同。
成员函数的引用限定符
引用限定符可以根据 this 指向的对象是 rvalue 还是 lvalue 来重载成员函数。 在选择不提供对数据的指针访问的情况下,使用此功能可避免不必要的复制操作。 例如,假设类 C 在其构造函数中初始化一些数据,并在成员函数 get_data() 中返回这些数据的副本。 如果 C 类型的对象是即将被销毁的 rvalue,编译器会选择 get_data() && 重载,该重载将移动而不是复制数据。
#include <iostream>
#include <vector>
using namespace std;
class C
{
public:
C() {/*expensive initialization*/}
vector<unsigned> get_data() &
{
cout << "lvalue\n";
return _data;
}
vector<unsigned> get_data() &&
{
cout << "rvalue\n";
return std::move(_data);
}
private:
vector<unsigned> _data;
};
int main()
{
C c;
auto v = c.get_data(); // get a copy. prints "lvalue".
auto v2 = C().get_data(); // get the original. prints "rvalue"
return 0;
}
重载限制
多个限制管理可接受的重载函数集:
重载函数集内的任意两个函数必须具有不同的参数列表。
仅基于返回类型重载具有相同类型的参数列表的函数是错误的。
Microsoft 专用
可以根据返回类型重载
operator new,特别是根据指定的内存模型修饰符。结束 Microsoft 专用
只要一个成员函数是
static,而另一个不是static,就无法重载。typedef声明不定义新类型;它们引入现有类型的同义词。 它们不影响重载机制。 考虑下列代码:typedef char * PSTR; void Print( char *szToPrint ); void Print( PSTR szToPrint );前面的两个函数具有相同的自变量列表。
PSTR是char *类型的同义词。 在成员范围内,此代码生成错误。枚举类型是不同的类型,并且可用于区分重载函数。
就区分重载函数而言,类型“array of”和“pointer to”是等效的,但仅适用于一维数组。 这些重载函数会发生冲突并生成错误消息:
void Print( char *szToPrint ); void Print( char szToPrint[] );对于更高维度的数组,第二个和后续维度被视为类型的一部分。 它们可用来区分重载函数:
void Print( char szToPrint[] ); void Print( char szToPrint[][7] ); void Print( char szToPrint[][9][42] );
重载、重写和隐藏
同一范围内具有同一名称的任何两个函数声明都可以引用同一函数或两个不同的重载函数。 如果声明的自变量列表包含等效类型的自变量(如上一节所述),函数声明将引用同一函数。 否则,它们将引用使用重载选择的两个不同的函数。
需要严格遵守类范围。 在基类中声明的函数与在派生类中声明的函数不在同一范围内。 如果使用与基类中的 virtual 函数相同的名称声明派生类中的函数,则该派生类函数会重写基类函数。 有关详细信息,请参阅虚函数。
如果未将基类函数声明为 virtual,则称派生类函数隐藏它。 重写和隐藏与重载不同。
需要严格遵守块范围。 在文件范围中声明的函数与在本地声明的函数不在同一范围内。 如果在本地声明的函数与在文件范围中声明的函数具有相同名称,则在本地声明的函数将隐藏文件范围内的函数而不是导致重载。 例如:
// declaration_matching1.cpp
// compile with: /EHsc
#include <iostream>
using namespace std;
void func( int i )
{
cout << "Called file-scoped func : " << i << endl;
}
void func( char *sz )
{
cout << "Called locally declared func : " << sz << endl;
}
int main()
{
// Declare func local to main.
extern void func( char *sz );
func( 3 ); // C2664 Error. func( int ) is hidden.
func( "s" );
}
前面的代码显示函数 func 中的两个定义。 由于 char * 语句,采用 main 类型的参数的定义是 extern 的本地定义。 因此,采用 int 类型的参数的定义被隐藏,而对 func 的第一次调用出错。
对于重载的成员函数,不同版本的函数可能获得不同的访问权限。 它们仍被视为在封闭类的范围内,因此是重载函数。 请考虑下面的代码,其中的成员函数 Deposit 将重载;一个版本是公共的,另一个版本是私有的。
此示例的目的是提供一个 Account 类,其中需要正确的密码来执行存款。 此操作通过重载来完成。
对 Deposit 中的 Account::Deposit 的调用会调用私有成员函数。 此调用是正确的,因为 Account::Deposit 是成员函数,可以访问类的私有成员。
// declaration_matching2.cpp
class Account
{
public:
Account()
{
}
double Deposit( double dAmount, char *szPassword );
private:
double Deposit( double dAmount )
{
return 0.0;
}
int Validate( char *szPassword )
{
return 0;
}
};
int main()
{
// Allocate a new object of type Account.
Account *pAcct = new Account;
// Deposit $57.22. Error: calls a private function.
// pAcct->Deposit( 57.22 );
// Deposit $57.22 and supply a password. OK: calls a
// public function.
pAcct->Deposit( 52.77, "pswd" );
}
double Account::Deposit( double dAmount, char *szPassword )
{
if ( Validate( szPassword ) )
return Deposit( dAmount );
else
return 0.0;
}