
在基于微服务的应用程序等分布式系统中,存在部分故障的风险。 例如,单个微服务/容器可能会失败或可能无法在短时间内响应,或者单个 VM 或服务器可能会崩溃。 由于客户端和服务是单独的进程,因此服务可能无法及时响应客户端的请求。 服务可能会过载,并且响应速度非常慢,或者由于网络问题,可能无法在短时间内访问。
例如,请考虑 eShopOnContainers 示例应用程序中的“订单详细信息”页。 如果用户尝试提交订单时,排序微服务无响应,则客户端进程(MVC Web 应用程序)的不良实现(例如,如果客户端代码使用没有超时的同步 RPC),则会无限期地阻止线程等待响应。 除了创建糟糕的用户体验外,每个无响应的等待都会消耗或阻止线程,并且线程在高度可缩放的应用程序中非常有价值。 如果存在许多阻塞的线程,则应用程序运行时最终可能会耗尽线程。 在这种情况下,应用程序可能会全局无响应,而不仅仅是部分无响应,如图 8-1 所示。
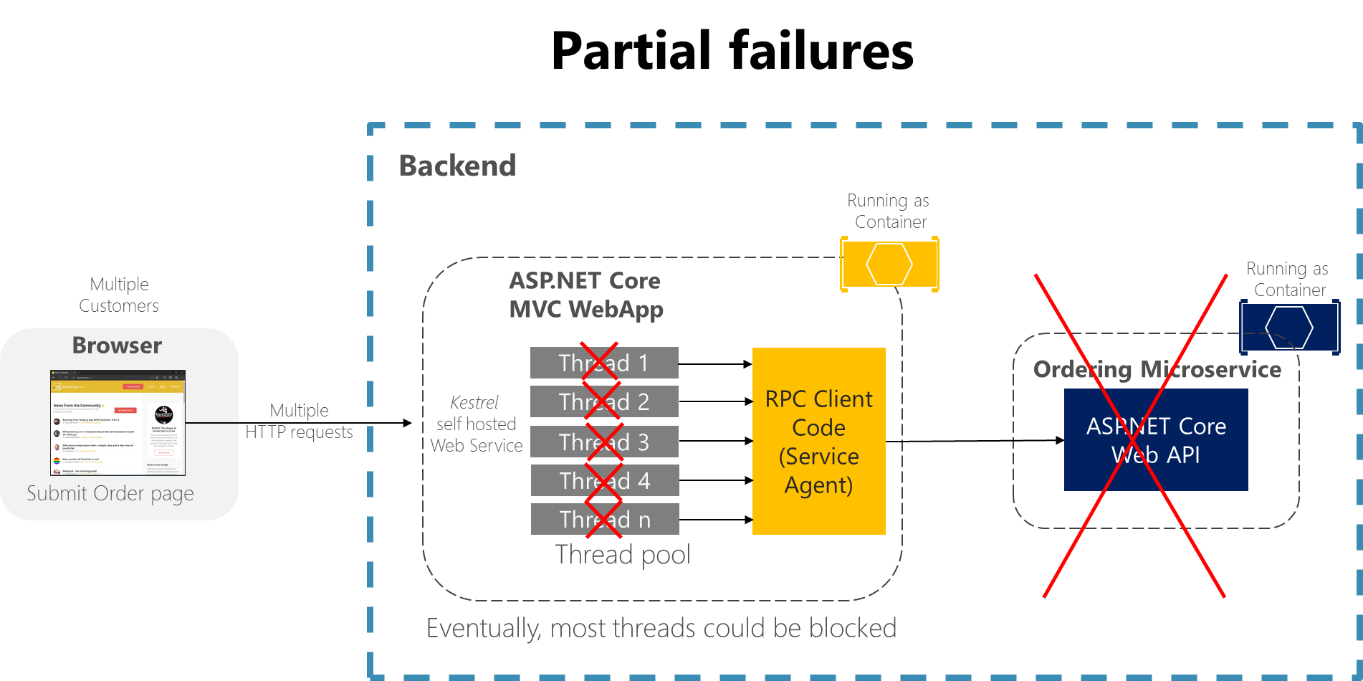
图 8-1。 由于影响服务线程可用性的依赖项而导致部分失败
在基于微服务的大型应用程序中,任何部分故障都可以放大,尤其是在大多数内部微服务交互基于同步 HTTP 调用(这被视为反模式)的情况下。 考虑每天接收数百万个传入呼叫的系统。 如果系统采用基于同步 HTTP 调用长链的不当设计,那么这些传入调用可能会再产生数百万对数十个内部微服务的传出调用(假设比例为 1:4)作为同步依赖项。 图 8-2(尤其是依赖项 #3)中显示了这种情况,它启动一个链,调用依赖项 #4,然后调用 #5。
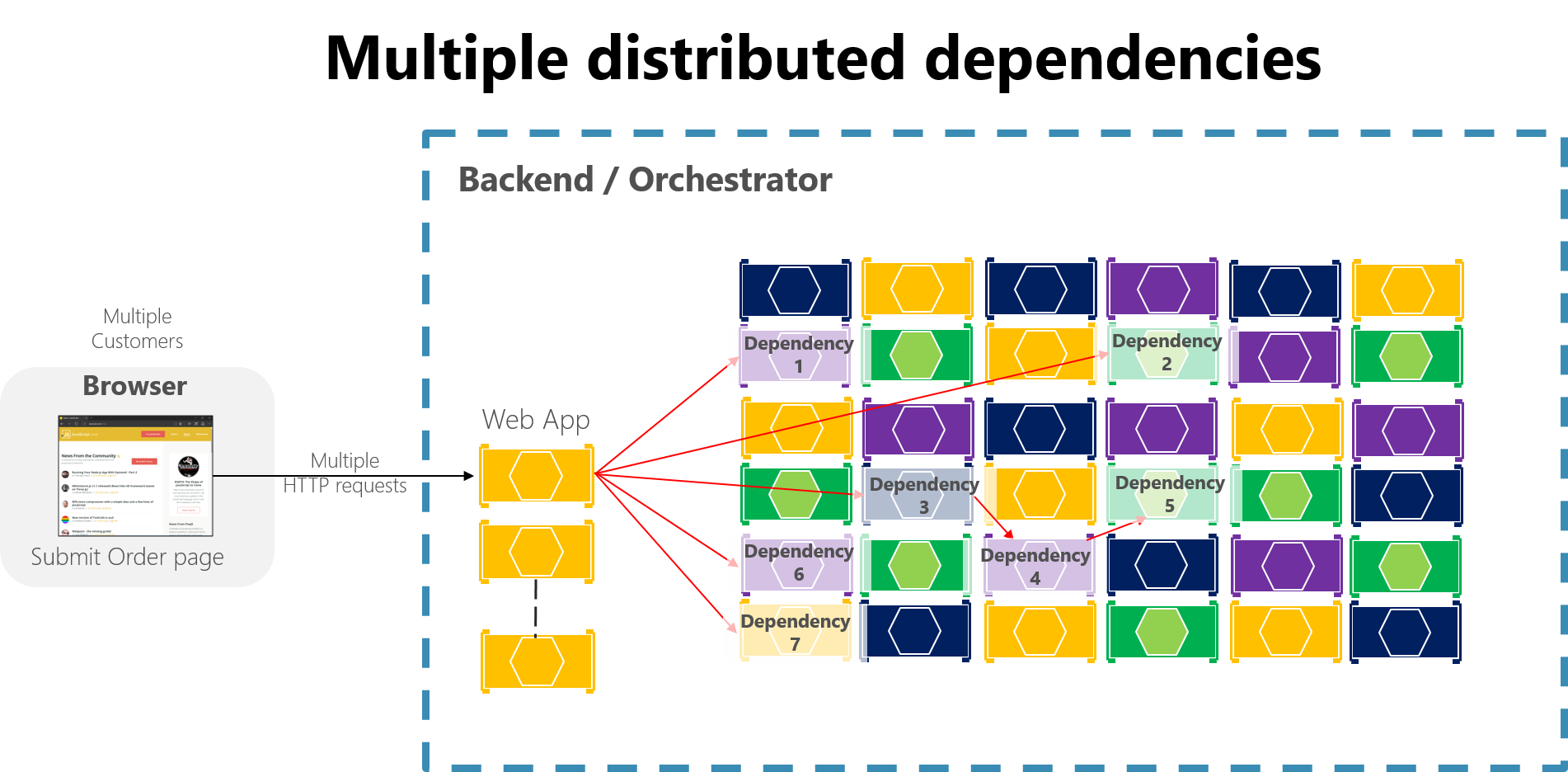
图 8-2。 采用 HTTP 请求长链的不当设计所产生的影响
间歇性故障在分布式和基于云的系统中得到保证,即使每个依赖项本身都具有出色的可用性。 这是一个事实,你需要考虑。
如果您不设计和实施容错技术,即便是短暂的停机时间也可能被放大。 例如,50 个依赖项,每个具有 99.99% 的可用性,因为这种连锁效应,每个月会产生几个小时的故障时间。 当微服务依赖项在处理大量请求时失败时,该故障可以快速使每个服务中的所有可用请求线程饱和并崩溃整个应用程序。
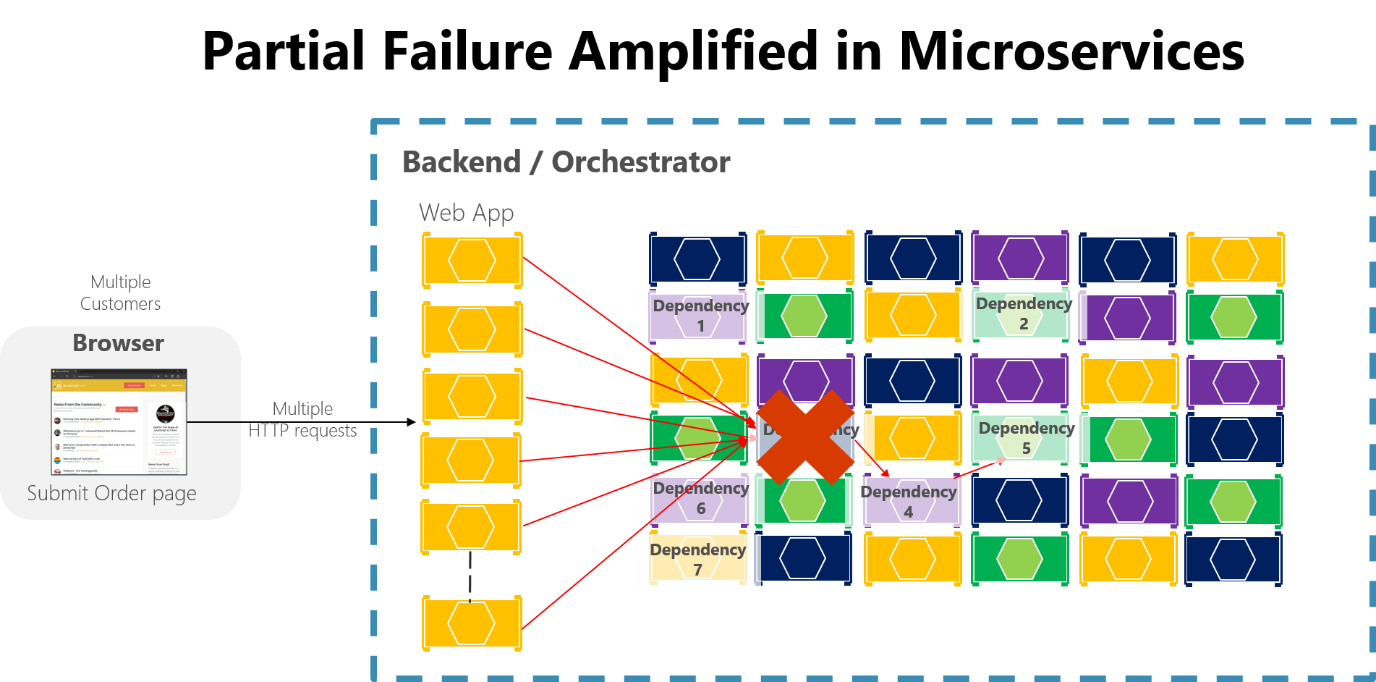
图 8-3. 由微服务使用同步 HTTP 调用长链放大的部分失败错误
为了尽量减少此问题,在 异步微服务集成强制实施微服务自治部分中,本指南鼓励你跨内部微服务使用异步通信。
此外,必须设计微服务和客户端应用程序来处理部分故障,即构建可复原的微服务和客户端应用程序。