ML.NET 模型生成器是一个直观的图形化 Visual Studio 扩展,用于生成、训练和部署自定义机器学习模型。 它使用自动机器学习 (AutoML) 来探索不同的机器学习算法和设置,以帮助你找到最适合自身场景的算法和设置。
使用模型生成器不需要具备机器学习的专业知识。 只需要一些数据,和确定要解决的问题。 模型生成器会生成将模型添加到 .NET 应用程序的代码。

创建 Model Builder 项目
首次启动 Model Builder 时,它会要求命名项目,然后在项目中创建 mbconfig 配置文件。 该 mbconfig 文件跟踪你在 Model Builder 中所执行的所有操作,以允许你重新打开会话。
训练后,将在 *.mbconfig 文件下生成三个文件:
- Model.consumption.cs:此文件包含
ModelInput和ModelOutput架构,以及为使用模型生成的Predict函数。 - Model.training.cs:此文件包含 Model Builder 选择的训练管道(数据转换、算法、算法超参数)以训练模型。 你可以使用此管道重新训练模型。
- Model.zip:这是一个已序列化的 zip 文件,它表示经过训练的 ML.NET 模型。
创建 mbconfig 文件时,系统将提示你输入名称。 此名称应用于使用量文件、训练文件和模型文件。 在本例中,使用的名称是 Model。
方案
可以为模型生成器提供许多不同的方案,从而为应用程序生成一个机器学习模型。
方案就是要使用数据进行预测类型的描述。 例如:
- 根据历史销售数据预测未来的产品销量。
- 根据客户评价将情绪分类为正面或负面。
- 检测某项银行交易是否存在欺诈性。
- 将客户反馈问题传递至公司中合适的团队。
每个方案都映射到不同的机器学习任务,其中包括:
| 任务 | 方案 |
|---|---|
| 二元分类 | 数据分类 |
| 多类分类 | 数据分类 |
| 图像分类 | 图像分类 |
| 文本分类 | 文本分类 |
| 回归 | 值预测 |
| 建议 | 建议 |
| 预测 | 预测 |
例如,将情绪归类为正面或负面的方案属于二元分类任务。
若要详细了解 ML.NET 支持的不同 ML 任务,请参阅 ML.NET 中的机器学习任务。
哪个机器学习方案最适合我?
在模型生成器中,你需要选择一个方案。 方案类型取决于尝试进行的预测类型。
表格
数据分类
分类用于将数据分类为类别。
示例输入
示例输出
| 萼片长度 | 萼片宽度 | 花瓣长度 | 花瓣宽度 | 种类 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 山鸢尾 |
| 预测物种 |
|---|
| 山鸢尾 |
值预测
值预测属于回归任务,用于预测数值。
示例输入
示例输出
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| 预测运费 |
|---|
| 4.5 |
建议
建议的方案根据特定用户的好恶与其他用户的相似程度,为他们预测建议项列表。
当你有一组用户和一组“产品”(如要购买的商品、电影、书籍或电视节目)以及一组用户对这些产品的“评级”时,你可以使用建议的方案。
示例输入
示例输出
| UserId | ProductId | Rating |
|---|---|---|
| 1 | 2 | 4.2 |
| 预测分级 |
|---|
| 4.5 |
预测
预测方案使用具有时序或季节因素的历史数据。
可以使用预测方案来预测产品的需求或销售。
示例输入
示例输出
| 日期 | 销售数量 |
|---|---|
| 1970/1/1 | 1000 |
| 3 天预测 |
|---|
| [1000,1001,1002] |
计算机视觉
图像分类
图像分类用于标识不同类别的图像。 例如,不同类型的地形或动物或制造缺陷。
如果你有一组图像,并且想要将图像分为不同的类别,则可以使用图像分类方案。
示例输入
示例输出

| 预测标签 |
|---|
| 狗 |
对象检测
对象检测用于定位图像中的实体并对其进行分类。 例如,定位和识别图像中的汽车和人。
如果图像包含多个不同类型的对象,可使用对象检测。
示例输入
示例输出

自然语言处理
文本分类
文本分类对原始文本输入进行分类。
如果你有一组文档或注释,并且希望将它们分类为不同的类别,则可以使用文本分类方案。
示例输入
示例输出
| 审阅 |
|---|
| 我真的很喜欢这个牛排! |
| 情绪 |
|---|
| 正 |
环境
可以在本地计算机上或在 Azure 上的云中训练机器学习模型,具体取决于相应方案。
在本地训练模型时,你将在计算机资源(CPU、内存和磁盘)的约束下工作。 在云中训练模型时,你可以扩展资源来满足你的方案的需求,尤其是对于大型数据集。
| 场景 | 本地 CPU | 本地 GPU | Azure |
|---|---|---|---|
| 数据分类 | ✔️ | ❌ | ❌ |
| 值预测 | ✔️ | ❌ | ❌ |
| 建议 | ✔️ | ❌ | ❌ |
| 预测 | ✔️ | ❌ | ❌ |
| 图像分类 | ✔️ | ✔️ | ✔️ |
| 对象检测 | ❌ | ❌ | ✔️ |
| 文本分类 | ✔️ | ✔️ | ❌ |
数据
选择方案后,Model Builder 会要求你提供数据集。 这些数据用于训练、评估和选择最适合方案的的模型。
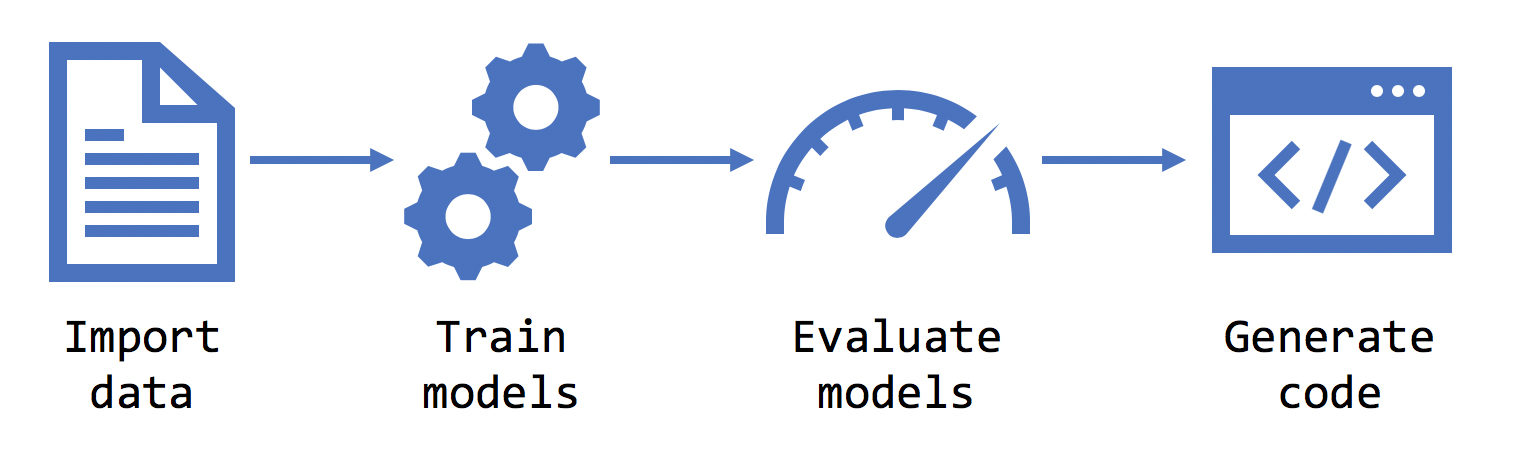
Model Builder 支持 .tsv、.csv、.txt 格式和 SQL 数据库格式的数据集。 如果你有 .txt 文件,则应使用 ,、; 或 \t 分隔列。
如果数据集由图像组成,则支持的文件类型为 .jpg 和 .png。
有关详细信息,请参阅将训练数据加载到模型生成器。
选择要预测的输出(标签)
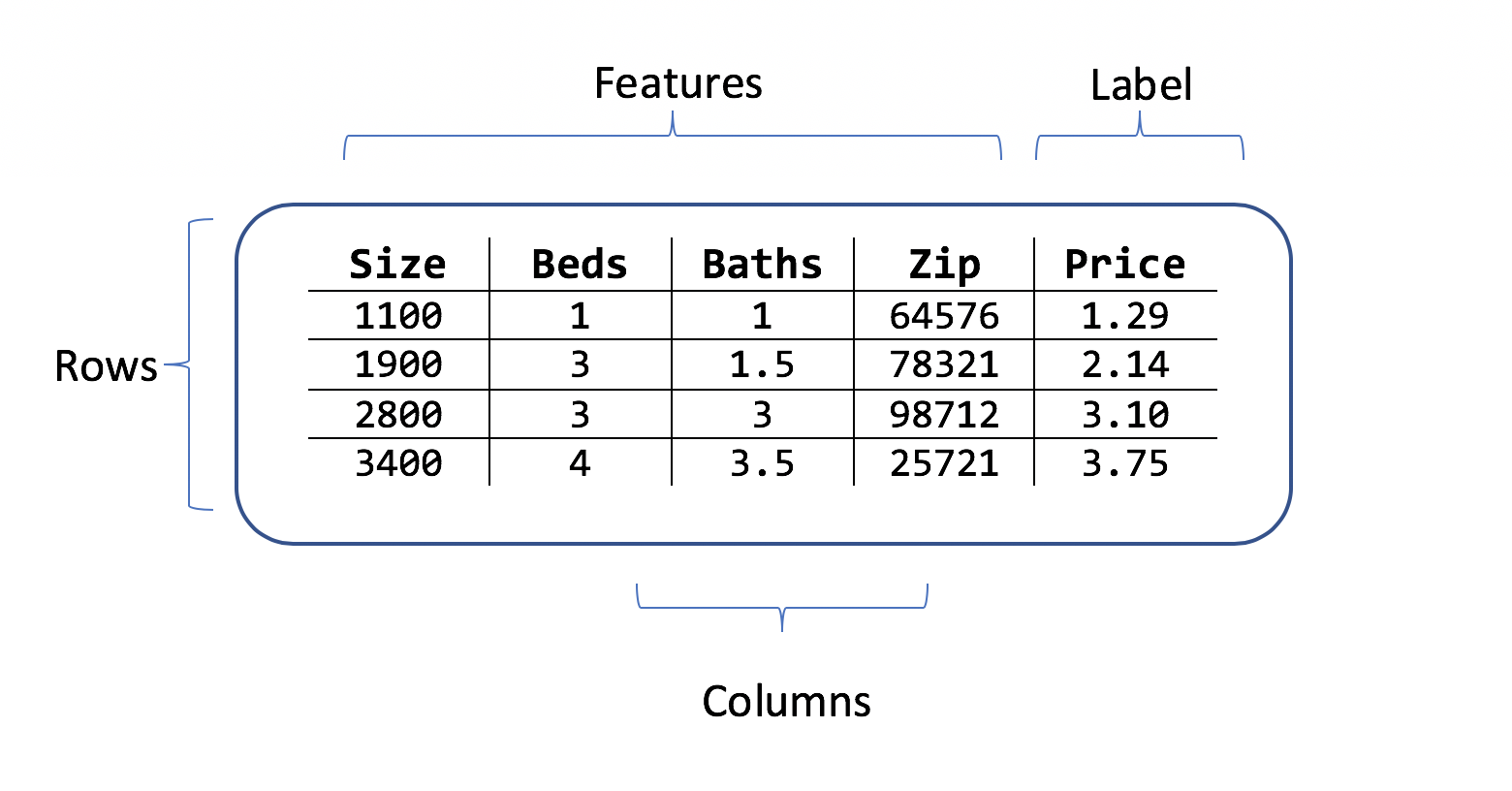
数据集是一个表格,其中,行中含训练示例,列中含特性。 每一行都具有:
- 一个标签,即要预测的特性
- 特征(为预测标签而用作输入的特性)
在房价预测方案中,特性可能是:
- 房屋的面积。
- 卧室和卫生间的数量。
- 邮政编码。
标签是与其所属行(包含面积、卧室和卫生间值以及邮政编码信息)对应的历史房价。
示例数据集
如果还没有自己的数据,请试用以下数据集之一:
| 方案 | 示例 | 数据 | Label | 特征 |
|---|---|---|---|---|
| 分类 | 预测销售异常 | 产品销售数据 | 产品销售额 | 月份 |
| 预测网站评论的情绪 | 网站评论数据 | 标签(负面情绪时为 1,正面情绪时为 0) | 评论、年份 | |
| 预测信用卡欺诈交易 | 信用卡数据 | 类(存在欺诈性为 1,否则为 0) | 金额,V1-V28(匿名处理后的特征) | |
| 预测 GitHub 存储库中的问题类型 | GitHub 问题数据 | 区域 | 标题、描述 | |
| 值预测 | 预测出租车费用价格 | 出租车费数据 | 车费 | 行程时间、距离 |
| 图像分类 | 预测花卉的类别 | 花卉图像 | 花卉类型:雏菊、蒲公英、玫瑰、向日葵、郁金香 | 图像数据本身 |
| 建议 | 预测他人喜欢的电影 | 电影评分 | 用户、电影 | 评级 |
训练
选择方案、环境、数据和标签后,模型生成器会训练该模型。
什么是训练?
训练是一个自动的过程,模型生成器通过该过程教模型如何回答方案相关的问题。 训练后,模型可以对其没有见过的输入数据进行预测。 例如,在预测房价时,可以预测新上市的房屋销售价。
因为模型生成器使用自动机器学习 (AutoML),所以在训练期间不需要任何人工输入或微调操作。
训练时长应为多长时间?
模型生成器使用 AutoML 浏览多个模型,以查找性能最佳的模型。
更长的训练周期允许 AutoML 通过更多设置来浏览更多模型。
下表汇总了在本地计算机上为一组示例数据集获取良好性能所花的平均时间。
| 数据集大小 | 训练的平均时间 |
|---|---|
| 0 - 10 MB | 10 秒 |
| 10 - 100 MB | 10 分钟 |
| 100 - 500 MB | 30 分钟 |
| 500 - 1 GB | 60 分钟 |
| 1 GB 以上 | 3 小时以上 |
这些数字仅用于指南。 训练的确切长度取决于:
- 用作模型输入的特征(列)的数量。
- 列类型。
- ML 任务。
- 用于训练的计算机的 CPU、磁盘和内存性能。
通常建议使用超过 100 行的数据集,否则可能不会生成任何结果。
评估
评估是衡量模型品质的过程。 模型生成器使用经过训练的模型对新的测试数据进行预测,然后度量预测效果的过程。
模型生成器将训练数据拆分为训练集和测试集。 训练数据 (80%) 用于训练模型,测试数据 (20%) 用于评估模型。
如何了解模型性能?
方案映射到机器学习任务。 每个 ML 任务都有其自己的一组评估指标。
值预测
值预测问题的默认指标为 RSquared,RSquared 值的范围介于 0 和 1 之间。 1 是可能的最大值,换句话说,RSquared 的值越接近 1,模型的性能就越好。
报告的其他指标(如绝对损失、平方损失和 RMS 损失)为附加指标,可以用来理解模型的性能,并将其与其他值预测模型进行比较。
分类(2 个类)
分类问题的默认指标是“准确性”。 准确性定义的是模型对测试数据集做出的正确预测的比例。 越接近 100% 或 1.0 越好。
报告的其他指标,如 AUC(曲线下面积),用于度量真正率和假正率之间的比例,在高于 0.50 时,才是可以接受的模型。
F1 分数等其他指标可用于控制精准率与召回率之间的平衡。
分类(3 个以上类)
多类分类问题的默认指标是微观准确性。 微观准确性越接近 100% 或 1.0 越好。
多类分类的另一个重要指标是宏观准确性,类似于微观准确性,越接近 1.0 越好。 考虑这两种准确性类型的一种好方法是:
- 微观准确性:传入票证分类给正确团队的频率如何?
- 宏观准确性:对于普通团队而言,传入票证符合其业务范围的频率如何?
有关评估指标的详细信息
有关详细信息,请参阅模型评估指标。
改进
如果模型性能评分不符合预期,可以:
延长训练时间。 有了更多时间,自动机器学习引擎可以体验更多算法和设置。
添加更多数据。 有时,数据量不足以训练高质量的机器学习模型。对于包含少量示例的数据集,尤其如此。
均衡分配数据。 对于分类任务,请确保在各个类别间均匀分配训练集。 例如,若有四个类别和 100 个训练示例,前两类(标记 1 和标记 2)包含 90 个记录,而剩下两类(标记 3 和标记 4)只包含 10 个记录,这就存在数据不均衡的问题,可能会导致模型很难正确预测标记 3 或标记 4。
使用
完成评估阶段后,模型生成器会输出一份模型文件和代码,可以使用该代码将模型添加到应用程序。 ML.NET 模型保存为 zip 文件。 用于加载和使用模型的代码会以新项目的形式添加到解决方案中。 模型生成器还会添加一个示例控制台应用,可以运行该应用来查看工作状态下的模型。
此外,Model Builder 还提供了选项来创建使用模型的项目。 目前,Model Builder 将创建以下项目:
- 控制台应用:创建一个 .NET 控制台应用程序,以通过模型进行预测。
- Web API:创建一个 ASP.NET Core Web API,使你可通过 Internet 使用模型。
后续步骤
安装 Model Builder Visual Studio 扩展。
请尝试价格预测或任何回归方案。