删除每个表中的重复项以实现数据统一
统一的“删除重复项规则”步骤从源表中查找并删除客户的重复记录,让每个客户由每个表中的一行表示。 每个表使用规则分别进行重复删除,以识别给定客户的记录。
规则按顺序进行处理。 在对表中的所有记录运行所有规则后,共用同一行的匹配组将合并为一个匹配组。
定义删除重复规则
好的规则可识别唯一客户。 考虑您的数据。 根据电子邮件等字段识别客户可能就足够了。 但是,如果您想要区分共用电子邮件的客户,可以选择有两个条件的规则,对 Email + FirstName 进行匹配。 有关详细信息,请参阅删除重复项概念和场景。
在删除重复项规则页上,选择表并选择添加规则来定义删除重复规则。
小费
如果您在数据源级别扩充了表以帮助改进统一结果,选择页面顶部的使用扩充表。 有关详细信息,请参阅数据源扩充。
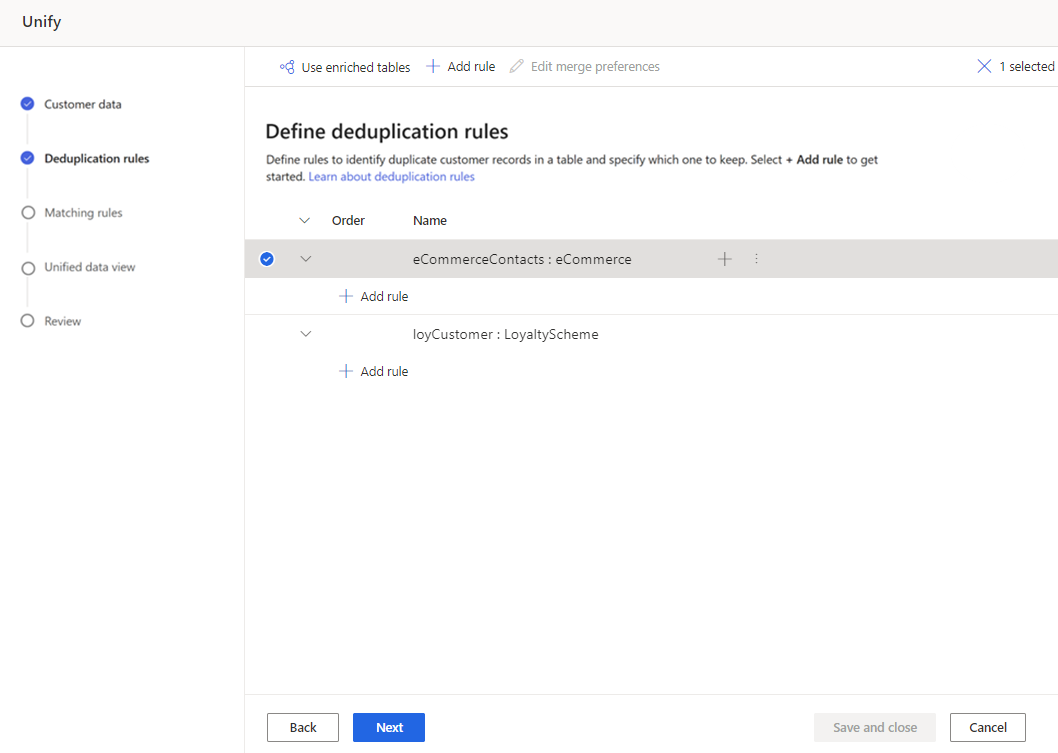
在添加规则窗格中,输入以下信息:
- 选择字段:从要检查重复项的表的可用字段列表中进行选择。 选择可能为每个客户所特有的字段。 例如,电子邮件地址,或者名称、市/县和电话号码的组合。
- 标准化:为列选择标准化选项。 标准化只影响匹配步骤,不会更改数据。
- 数字:将表示数字的多个 Unicode 符号转换为简单数字。
- 符号:删除多个常见符号,如 !"#$%&'()*+,-./:;<=>?@[]^_`{|}~。 例如,Head&Shoulder 会变为 HeadShoulder。
- 文本转换为小写:将所有字符转换为小写。 “ALL CAPS and Title Case”会变为“all caps and title case。”
- 类型(电话、名称、地址、组织):对名称、头衔、电话号码、地址等进行标准化处理。
- Unicode 转变为 ASCII:将 Unicode 字符转换为同等 ASCII 字符。 例如,重音符号 ề 将转换为 e 字符。
- 空白:删除所有空格。 Hello World 会变为 HelloWorld。
- 精度:设置精度级别。 精度用于模糊匹配,确定两个字符串需要多接近才能被视为匹配。
- 基本:从低 (30%)、中 (60%)、高 (80%) 和精确 (100%) 中选择。 选择精确以仅匹配 100% 匹配的记录。
- 自定义:设置记录需要匹配的百分比。 系统将只匹配传递此阈值的记录。
- 名称:规则的名称。
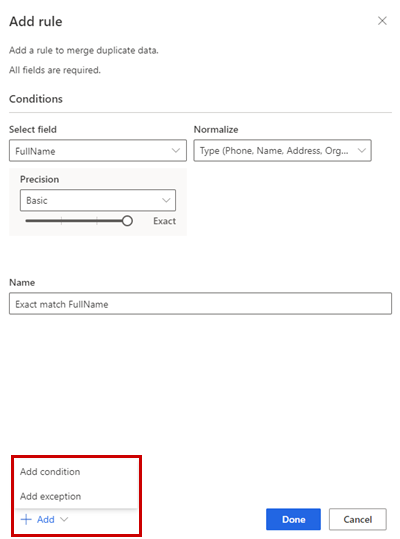
或者,也可以选择添加>添加条件向规则添加更多条件。 条件与逻辑 AND 运算符相连,因此仅在满足所有条件时才会执行。
或者,也可以选择添加>添加异常以向规则中添加异常。 异常用于解决个别情况下的误报和漏报。
选择完成以创建规则。
(可选)添加更多规则。
选择表,然后选择编辑合并首选项。
在合并首选项窗格中:
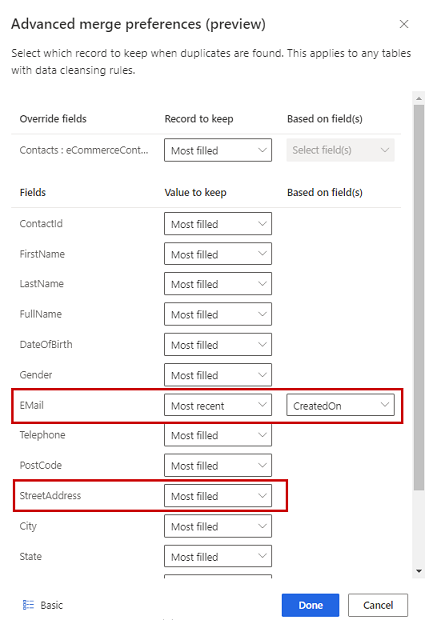
选择以下三个选项之一,以确定在发现重复项时要保留的记录:
- 最多填充:将填充列最多的记录标识为入选记录。 这是默认的合并选项。
- 最常使用:根据最常使用标识入选记录。 需要日期或数字字段以定义近期性。
- 最不常用:根据最不常用标识入选记录。 需要日期或数字字段以定义近期性。
如果存在同等项,获胜者记录是具有 MAX(PK) 或较大主键值的记录。
(可选)要对表的各个列定义合并首选项,可以选择窗格底部的高级。 例如,您可以选择保留来自不同记录的最新电子邮件和最完整地址。 展开表以查看其所有列并定义用于各个列的选项。 如果您选择基于新近度的选项,您还需要指定定义新近度的日期/时间字段。
选择完成以应用合并首选项。
定义删除重复规则和合并首选项后,选择下一步。
