概述
重新缓冲区是 Microsoft eCDN 的北star,用于衡量观看者体验的质量。
定义
重新缓冲定义为观看者在缓冲时使用静止视频或不使用视频的任意时间。 它按个人的完整会话时间的百分比计算:buffer-time/ (play-time + buffer-time) 。 所有用户的重新缓冲区的聚合按事件平均并显示在分析仪表板中,并在“重新缓冲区”小组件中选择的时间范围求平均值。
什么是错误的回退?
3% 或更高被视为不良体验。
| 范围 | 颜色编码 | 测定 |
|---|---|---|
| >3% | 红色 | 我们认为超过 3% 的体验很差,当存在大量用户群时,需要进行调查。 |
| <3% 和 >1% |
黄色 | 可以考虑从降级到关注。 我们发现,通常,如果位于范围的较高端,并且仅当大型或集中组受到影响时,黄色范围才引起关注。 |
| <1% | 绿色 | 被认为是一个很好的体验。 我们通常看到 Microsoft eCDN 客户群的拒绝率远远低于 1%。 |
如何使用 rebuffering 进行故障排除
Microsoft eCDN 提供深度体验指标(例如回退),这些指标可用于证实用户体验不佳的报告,并帮助确定受影响的查看者的范围。 它还可用于突出显示网络环境中的弱点,尤其是在使用 无提示测试执行负载测试时。
以下是重新缓冲区可能是一个有用的指标的方案。
确定问题期限
故障排除的第一步是确定问题的期限。 通过将事件的回退百分比与以前的事件进行比较,可以识别出时间范围内不同的模式。 要问的问题可能包括...
- 在以前的事件中也观察到这种回退还是非持久性?
- 这是否拒绝了新事件?
- 如果是这样,则自上次事件以来,子网映射或网络配置中做了一些更改,并进行了很好的回缓冲区。 如果是,该怎么办?
潜在持续问题的示例
在此屏幕截图中,我们观察到从具有较大事件的特定日期开始的合理一致问题。 除了事件大小之外,最好观察其他可能的共同特征,例如 ISP 或子网组。
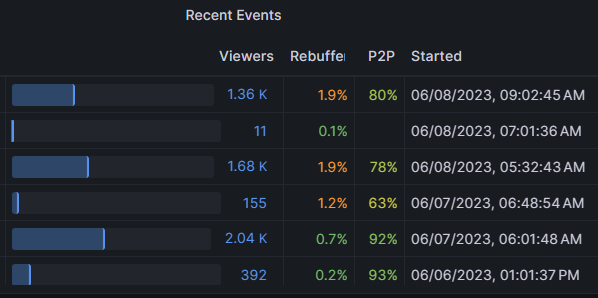
单个高反缓冲区事件的示例
在此屏幕截图中,我们观察到,针对最大事件的高回退是以前事件中不存在的新问题。 这里要问的一个好问题是,是在整个观众群中经历了糟糕的拒绝,还是集中在某个地方。
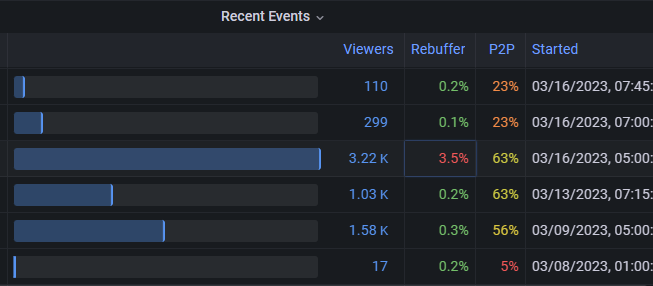
我们还观察到后续较小的事件是可以的,因此可以假定原因与事件的唯一特征有关,例如其大小、计时或其他属性。
排除暂时性网络不规范
重新缓冲区可能是由于网络不一致而无法直接控制,例如 ISP 或内容分发网络暂时服务不一致。 在“向下钻取”仪表板中,在筛选特定事件后,选择“组细分”维度后,我们检查“重新缓冲区时间线”图中是否存在跨组的任何视觉模式。
跨组重新缓冲区的示例
在 “组 ”维度的“重新缓冲区时间线”屏幕截图中,我们观察到在这 90 分钟事件中的三个时刻,在事件开始时、中间点和事件结束时,所有大型组织的组都经历了高度回退。 这种跨组织的影响是问题来源的有力指标,在这种情况下,这是组织的内容分发网络: 一个 CDN,不要与 Microsoft eCDN 混淆。
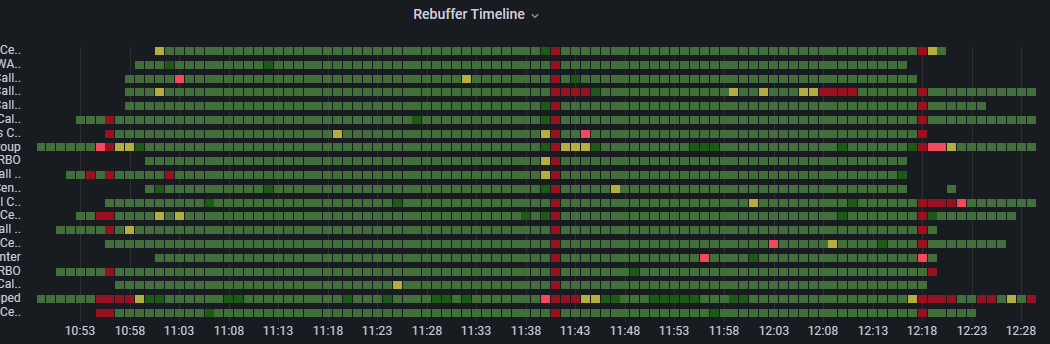
在单个组中进行反缓冲区的示例
与上述时间线屏幕截图类似,在此示例中,我们还观察到组织范围的拒绝时刻接近尾声。 此外,我们还可以看到,此组织的 VPN 组之一在整个事件中遇到了糟糕的回退。 这可能是组织的 VPN 线路中容量不足的明显指标。 如果是这样,则此组将是一个很好的测试用例,用于调查拆分隧道 Teams 流量的影响以降低负载。
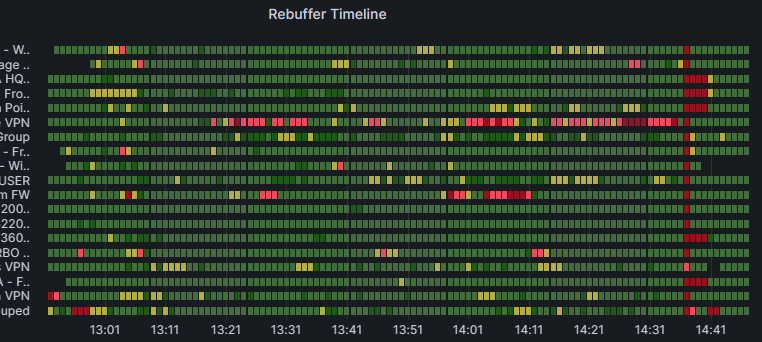
识别有问题的切片
假设总体原因不明显,请通过系统地切片分析向下钻取仪表板中各种可用故障的数据,在故障排除过程中继续确定问题点。 细分维度包括以下内容。
- 事件
- 组
- 应用程序
- Isp
- 国家/地区
- 市/县
- 操作系统
限制
即使上传了子网映射,有时也会在 默认组中找到高退位点。 若要排查这些组的指标不佳问题,请使用自动填充的细分类别,例如以下内容来筛选和切片数据。
- 应用程序
- Isp
- 国家/地区
- 市/县
摘要
下次遇到高度回退时,请查找模式并问自己以下问题。
- 高拒绝是发生在公司范围内还是仅在特定站点发生?
- 对于用于watch直播活动的特定操作系统或应用程序,是拒绝更高的?
- 是否在每个用户的特定时刻发生拒绝操作,并在一段时间后消失?
- 观察到的退让时刻与网络上的另一个潜在影响事件之间是否有关联?
重新缓冲区是一种不需要的副产品,通常与网络不可靠相关。 借助 Microsoft eCDN 的仪表板,你可以更深入地了解其源,以帮助你解决问题。