注意
本文假设您知道如何在基本场景下使用 Code First 迁移。 如果你不知道,则需要先阅读 Code First 迁移,再继续。
拿一杯咖啡,你需要阅读整篇文章
团队环境中的问题主要涉及两个开发人员已在他们的本地代码库中生成迁移时的合并迁移。 虽然解决这些问题的步骤非常简单,但要求你对迁移的工作原理有深刻的了解。 请不要直接跳到结尾,花时间阅读整篇文章以确保成功。
一些通用准则
在深入探讨如何管理由多个开发人员生成的合并迁移之前,下面是一些让你为取得成功做好准备的通用准则。
每个团队成员都应有一个本地开发数据库
迁移使用 __MigrationsHistory 表来存储已向数据库应用的迁移。 如果多个开发人员生成不同的迁移,同时尝试将同一个数据库作为目标(并因此共享一个 __MigrationsHistory 表),迁移就会变得非常混乱。
当然,如果团队中有成员不参与迁移的生成,那让他们共享一个中心开发数据库是没问题的。
避免自动迁移
最重要的一点是,自动迁移最初在团队环境中看起来不错,实际上却不起作用。 如果希望了解原因,请继续阅读;否则,可以跳到下一个部分。
自动迁移使你能够更新数据库架构以匹配当前模型,而无需生成代码文件(基于代码的迁移)。 如果你曾经只使用了自动迁移并且从未生成任何基于代码的迁移,则自动迁移在团队环境中非常有效。 问题在于自动迁移是有限的,并且它们不处理许多操作 - 例如,将属性/列重命名,将数据移动到另一个表。若要处理这些情况,你最终将生成基于代码的迁移(并编辑构建的代码),这些迁移混合在自动迁移处理的更改之间。 几乎不可能在两名开发人员签入迁移时合并更改。
了解迁移的工作原理
在团队环境中成功使用迁移的关键是,对迁移如何跟踪并使用模型相关信息来检测模型更改有基本的了解。
首次迁移
你在将首次迁移添加到项目时,会在包管理器控制台中运行类似于 Add-Migration First 的命令。 此命令执行的高层步骤如图所示。
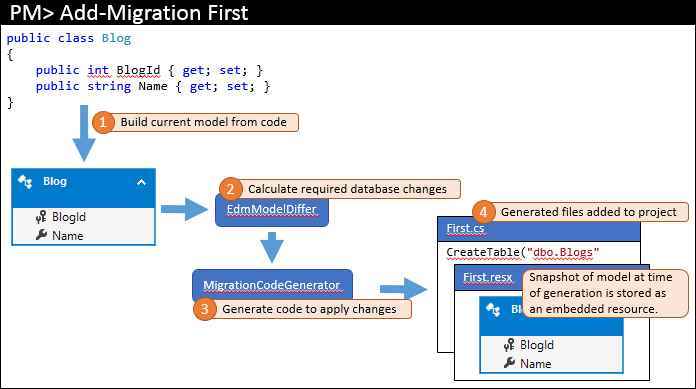
当前模型是根据您的代码计算而得 (1)。 然后,模型比较器计算需要的数据库对象 (2) - 因为这是首次迁移,所以模型比较器只使用一个空模型来进行比较。 所需的更改被传递给代码生成器,用于生成需要的迁移代码 (3)。接下来,将该代码添加到 Visual Studio 解决方案中 (4)。
除了存储在主代码文件中的实际迁移代码外,迁移还会生成一些额外的代码隐藏文件。 这些文件是迁移使用的元数据,而不是你应该编辑的内容。 其中一个文件是资源文件 (.resx),该文件包含生成迁移时的模型的快照。 下一步介绍如何使用。
此时,你可能会运行 Update-Database 将更改应用到数据库,然后再开始实现应用程序的其他区域。
后续迁移
稍后你再回来对模型做一些更改:在本示例中,我们将向 Blog 添加一个 Url 属性。 那时,你将发出一个命令(例如 Add-Migration AddUrl)来构建迁移,以应用相应的数据库更改。 该命令执行的主要步骤如下图所示。
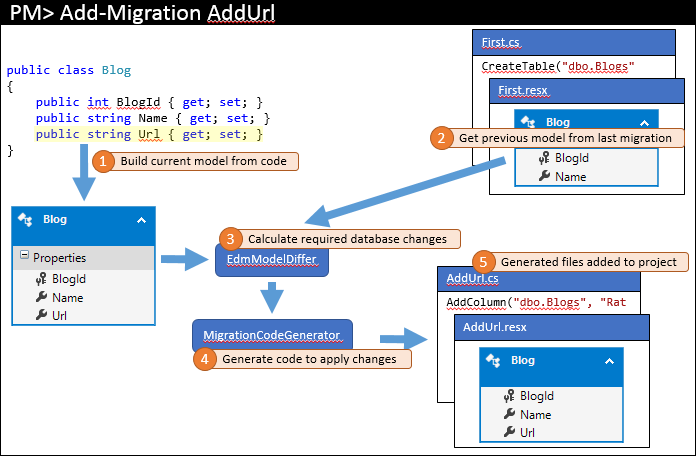
与上一次一样,当前模型是根据代码计算出的 (1)。 但是,这一次已有迁移,因此使用最新迁移中的模型作为上一个模型 (2)。 比较这两个模型,以查找需要的数据库更改 (3),然后将像前面那样完成此过程。
为你向项目添加的任何其他后续迁移使用相同的过程。
为什么要费心去做模型快照?
您可能想知道 EF 为什么费心使用模型快照,为什么不只是查看数据库。 如果是这样,请继续阅读。 如果不感兴趣,可以跳过此部分。
EF 保留模型快照的原因有很多:
- 它允许数据库偏离 EF 模型。 可以直接在数据库中做更改,也可以更改迁移中构建的代码来进行更改。 下面是几个实际的示例:
- 你希望向一个或多个表中添加插入和更新的列,但不希望 EF 模型中包含这些列。 如果迁移着眼于数据库,则每次你构建迁移时,它都会不断尝试删除这些列。 如果使用模型快照,EF 只会检测到对模型的合法更改。
- 你要更改用于更新的存储过程的正文,使其包括一些日志记录。 如果迁移查看数据库中的此存储过程,它将不断尝试将其重置为 EF 期望的定义。 通过使用模型快照,当你在 EF 模型中更改存储过程的结构时,EF 只会生成代码以修改该存储过程。
- 相同的原则适用于添加额外的索引,在数据库中添加额外的表,将 EF 映射到基于表的数据库视图等。
- EF 模型不仅仅包含数据库的结构。 拥有整个模型使迁移能查看有关模型中的属性和类的信息,以及它们如何映射到列和表。 此信息使迁移在它构建的代码中更智能。 例如,如果您更改属性映射的列名称,迁移可以通过识别该属性本身是相同的来检测重命名——如果仅有数据库模式信息,这点是无法实现的。
造成团队环境中出现问题的原因
当你是开发应用程序的一名开发人员时,上一部分中介绍的工作流非常有效。 如果你是唯一对模型进行更改的人,该工作流在团队环境中也能正常工作。 在这种情况下,你可以更改模型,生成迁移并将它们提交到源代码管理。 其他开发人员可以同步你的更改,并运行 Update-Database 来应用架构更改。
同时由多名开发人员更改 EF 模型并提交到源代码管理时,就会出现问题。 EF 缺乏的是一种出色的方法,用于将本地迁移与其他开发人员自你上次同步以来已提交到源代码管理的迁移合并在一起。
合并冲突示例
我们先看一看此类合并冲突的一个具体示例。 我们将继续使用前面所述的示例。 首先,假设前面部分中的更改已由最初的开发人员签入。 我们将跟踪两名开发人员对代码库的更改。
我们将通过多次更改来跟踪 EF 模型和迁移。 最初,这两名开发人员都已同步到源代码管理存储库,如下图中所述。
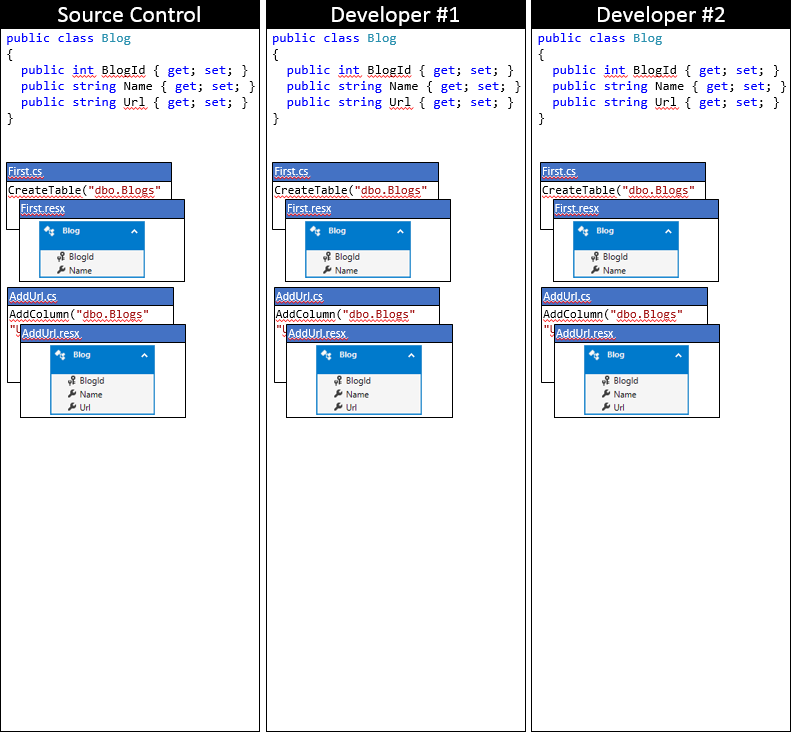
开发人员 #1 和开发人员 #2 现在都在各自的本地代码库中对 EF 模型执行一些更改。 开发人员 #1 向 Blog 添加一个 Rating 属性,并生成一个 AddRating 迁移,以便将更改应用于数据库。 开发人员 #2 向 Blog 添加一个 Readers 属性,并生成一个相应的 AddReaders 迁移。 这两个开发人员都运行 Update-Database,以将更改应用到本地数据库,然后继续开发应用程序。
注意
迁移以时间戳为前缀,因此我们的图形表示开发人员 #2 生成的 AddReaders 迁移位于开发人员 #1 生成的 AddRating 迁移之后。 是否由开发人员#1还是#2首先生成迁移对于在团队中工作的相关问题以及我们将在下一个部分中介绍的合并迁移的过程都没有影响。
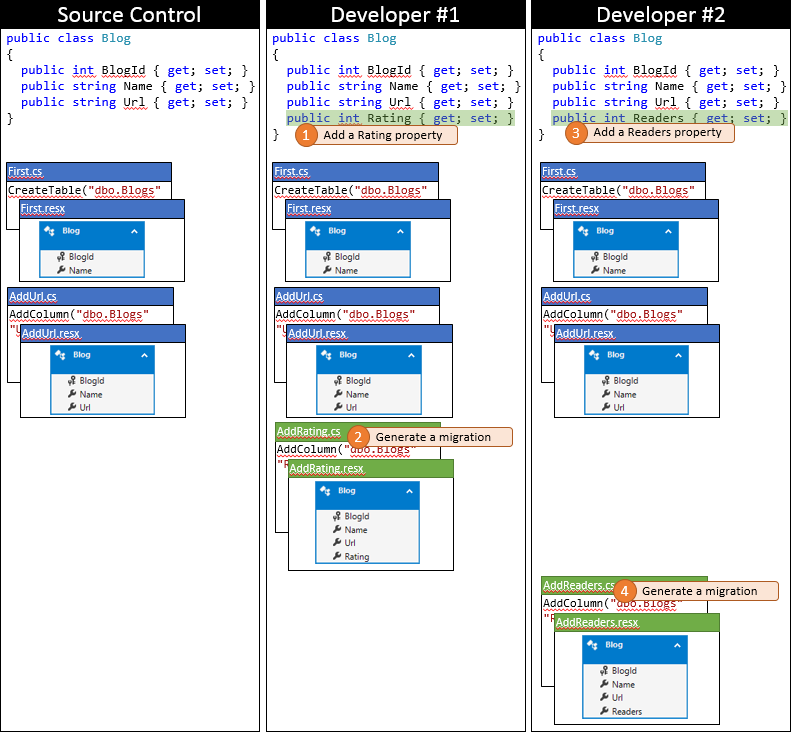
开发人员 #1 非常幸运,因为他们恰巧先提交更改。 在他们同步存储库后尚无他人签入,因此他们可以只提交更改而不执行任何合并。
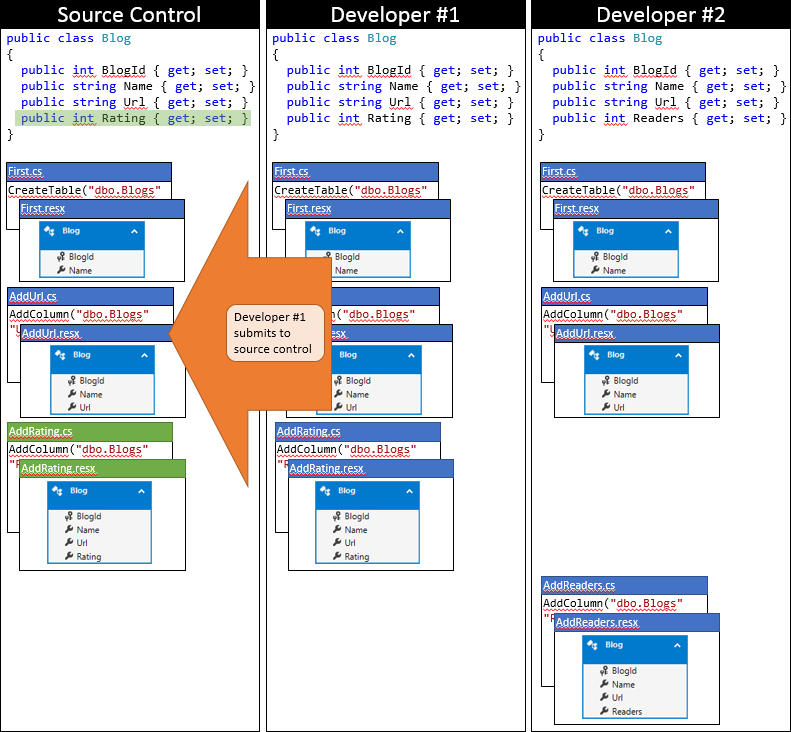
现在,该由开发人员 #2 提交了。 他们不太幸运。 因为其他人在他们同步之后提交了更改,所以他们需要拉取这些更改并进行合并。 源代码管理系统可能可以在代码级别自动合并更改,因为它们非常简单。 下图描绘了同步后开发人员 #2 的本地存储库的状态。
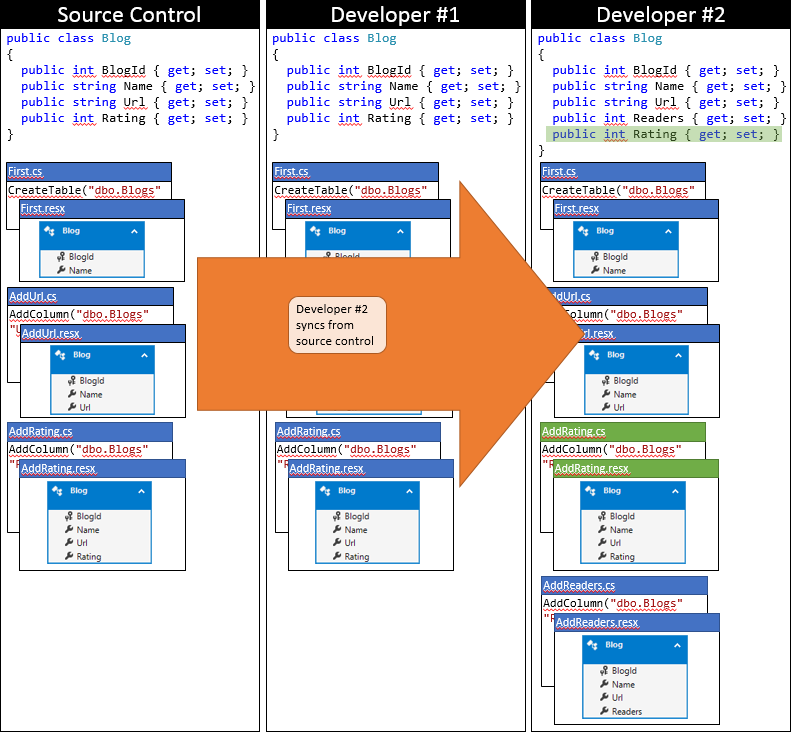
在此阶段,开发人员 #2 可以运行Update-Database命令,它将检测到新的AddRating迁移(尚未应用于开发人员 #2 的数据库),并执行应用。 现在,Rating 列已添加到 Blogs 表中,并且数据库与模型同步。
但也存在几个问题:
- 虽然 Update-Database 会应用 AddRating 迁移,但也会引发警告:无法更新数据库以匹配当前模型,因为有待处理的更改并且自动迁移被禁用。问题是,存储在最后一个迁移 (AddReader) 中的模型快照在 Blog 上丢失了 Rating 属性(因为生成迁移时,它不是模型的一部分)。 Code First 检测到最后一个迁移中的模型与当前模型不匹配,并引发警告。
- 运行应用程序会导致 InvalidOperationException,它指出“自创建数据库以来,支持 BloggingContext 上下文的模型已更改。请考虑使用 Code First 迁移来更新数据库…”同样,问题在于最后一个迁移中存储的模型快照与当前模型不匹配。
- 最后,我们预计现在运行Add-Migration会生成一个空白迁移(因为没有更改要应用于数据库)。 但由于迁移将当前模型与最后一个迁移的模型(缺少 Rating 属性)相比较,这实际上会生成另一个 AddColumn 调用以添加 Rating 列。 当然,在 Update-Database 期间,此迁移会失败,因为 Rating 列已存在。
解决合并冲突
好消息是,只要了解迁移的工作原理,手动处理合并就不太困难。 如果你直接跳到了这一节… 抱歉,你需要返回,先阅读本文的其余部分!
有两个选择,最简单是生成一个空白迁移,它将正确的当前模型作为快照。 第二个选项是更新最后一次迁移中的快照,以确保模型快照正确无误。 第二个选择稍微难一些,不适用于每一种情况;但它也更简洁,因为它不涉及添加额外的迁移。
选择 1:添加空白的“合并”迁移
在此选择中,我们生成一个空白迁移,目的仅仅是确保最新迁移中存储了正确的模型快照。
无论最后一个迁移由谁生成,我们都可以使用此选择。 在我们遵循的示例中,开发人员 #2 负责处理合并,并且碰巧生成了最新的迁移。 如果最后一个迁移是由开发人员 #1 生成的,同样可以使用这些步骤。 如果涉及多个迁移,这些步骤也适用。为了简化,我们只是考虑了两个迁移。
一旦你意识到需要从源代码管理中同步更改,就可以使用以下过程来实现这种方法。
- 确保已将本地代码库中未完成的模型更改记录到迁移文件中。 此步骤确保你在生成空白迁移时不会错过任何合法更改。
- 与源代码管理同步。
- 运行Update-Database来应用其他开发人员已签入的任何新迁移。 注意:如果未收到任何来自 Update-Database 命令的警告,说明没有来自其他开发人员的新迁移,并且无需执行任何进一步的合并。
- 运行 Add-Migration <pick_a_name> –IgnoreChanges(例如,Add-Migration Merge –IgnoreChanges)。 这会生成一个带有所有元数据(包括当前模型的快照)的迁移,但会忽略它在将当前模型与最后一个迁移中的快照进行比较时检测到的任何更改(也就是说,你得到一个空白的 Up 和 Down 方法)。
- 请运行Update-Database以使用更新后的元数据重新应用最新的迁移。
- 继续开发,或在运行单元测试后提交到版本控制系统。
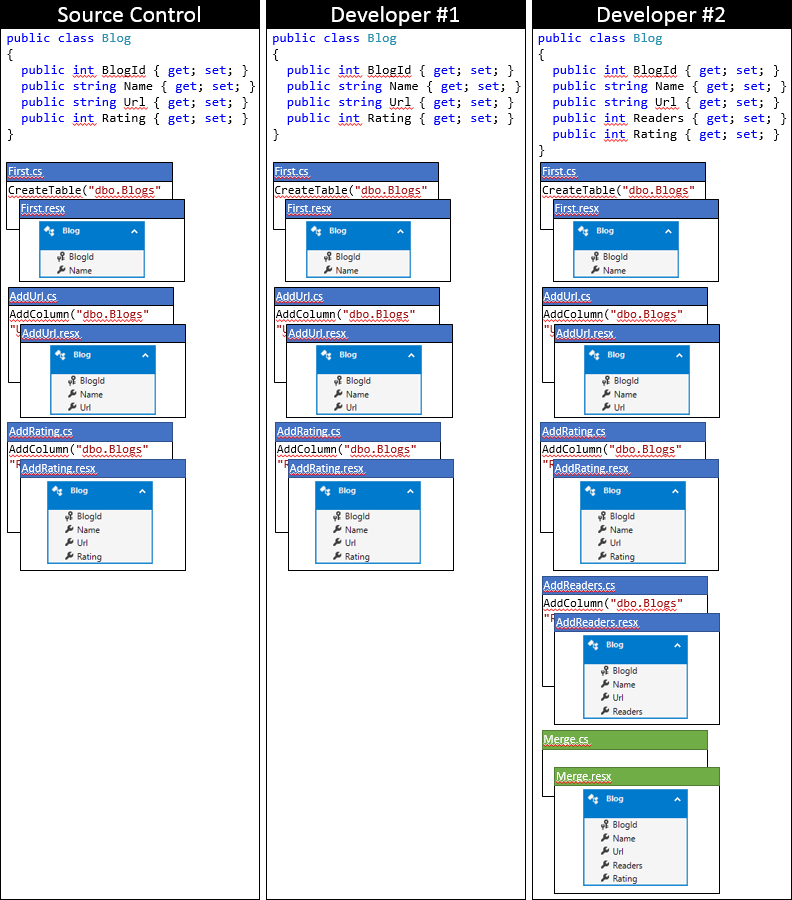
下面是使用这种方法后,开发人员 #2 的本地代码库的状态。
选择 2:更新最后一个迁移中的模型快照
此选项与第 1 种选项非常相似,但会删除不必要的空白迁移——说实话,谁会希望在解决方案中有多余的代码文件呢?
如果最后一个迁移仅存在于本地代码库中并且尚未被提交到源代码管理(例如,最后一个迁移是由执行合并操作的用户生成的),此方法才可行。 编辑其他开发人员可能已经应用到开发数据库的迁移元数据(甚至更糟糕的情况是已经应用到生产数据库),可能会导致意想不到的副作用。 在此过程期间,我们将回退本地数据库中的最后一个迁移,然后使用更新后的元数据重新应用它。
虽然最后一个迁移必须仅在本地代码库中进行,但在其之前的迁移的数量或顺序并无限制。 可以有来自多个不同开发人员的多个迁移,这些步骤同样适用 - 为了简单起见,我们只是以两个迁移为例以保持简单。
意识到需要从源代码管理中同步更改时,可以使用以下过程来实现这种方法。
- 确保将本地代码库中尚未完成的模型更改写入了迁移。 此步骤确保你在生成空白迁移时不会错过任何合法更改。
- 与源代码管理同步。
- 运行Update-Database来应用其他开发人员签入的任何新迁移。 注意:如果未收到任何来自 Update-Database 命令的警告,说明没有来自其他开发人员的新迁移,并且无需执行任何进一步的合并。
- 运行
Update-Database –TargetMigration (在我们一直跟随的示例中,这将是second_last_migration Update-Database –TargetMigration AddRating )。 这会将数据库回退到倒数第二个迁移的状态 - 实际上是从数据库取消应用最后一个迁移。 注意:必须执行此步骤才能安全地编辑迁移的元数据,因为元数据也存储在数据库的 __MigrationsHistoryTable 中。因此,如果最后一个迁移只位于本地代码库中,你应只使用此选择。如果其他数据库应用了最后一个迁移,则还必须回退这些数据库,然后重新应用最后一个迁移来更新元数据。 - 运行 Add-Migration <full_name_including_timestamp_of_last_migration>(在本例中,这类似于 Add-Migration 201311062215252_AddReaders)。 注意:需要包括时间戳,这样迁移才知道你要编辑现有迁移,而不是构建新迁移。这会更新最后一个迁移的元数据,以匹配当前模型。 该命令完成后,你将收到以下警告,但这正是你需要的。 “仅重新构建了迁移 ‘201311062215252_AddReaders’的设计器代码。若要重新构建整个迁移,请使用 -Force 参数。”
- 请运行Update-Database以使用更新后的元数据重新应用最新的迁移。
- 继续开发,或在运行单元测试后提交到版本控制系统。
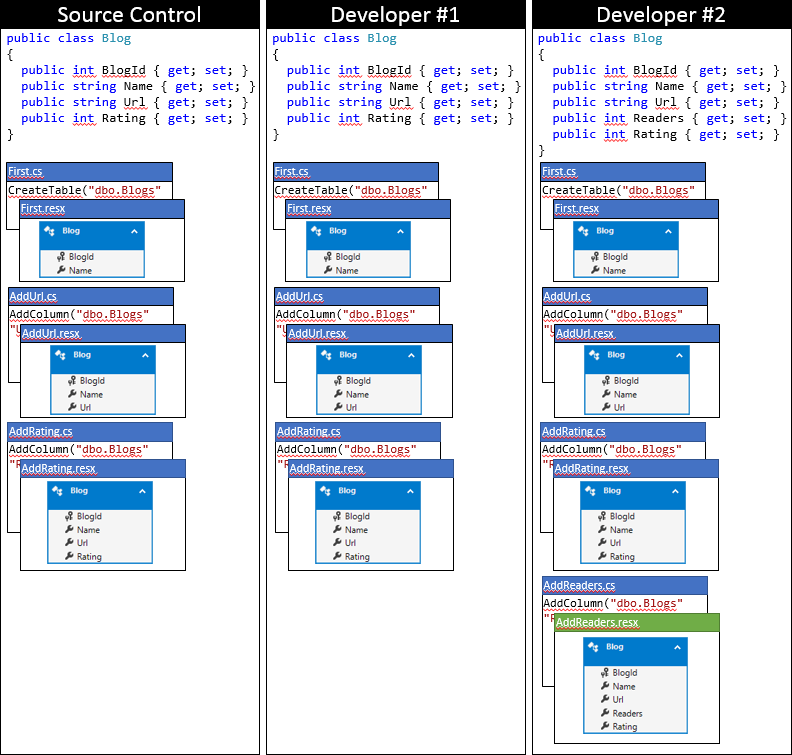
下面是使用这种方法后,开发人员 #2 的本地代码库的状态。
总结
在团队环境中使用 Code First 迁移存在一些难题。 但是,如果基本了解迁移的工作原理以及解决合并冲突的一些简单方法,就能轻松攻克这些难题。
根本问题在于存储在最后一个迁移中的元数据不正确。 这造成 Code First 错误地检测到当前模型和数据库架构不匹配,并在最后一个迁移中构建错误的代码。 可以通过使用正确的模型生成空白迁移,或更新最新迁移中的元数据来克服这种情况。