适用于:✅ Fabric 数据工程和数据科学
Fabric 数据工程中的资源配置文件可帮助你在不手动优化的情况下获得优化的 Spark 计算配置。 通过选择主要用例、数据量和其他几个高级输入来描述工作负荷。 然后,Fabric 根据经过验证的最佳做法和内部性能数据生成建议的配置,包括节点大小、自动缩放设置和运行时版本。
为何使用资源配置文件
资源配置文件提供以下内容:
- 从一开始就进行了优化:第一个 Spark 会话在针对工作负荷优化的计算上运行,无需迭代基准测试。
- 一致性:工作区中的所有 Spark 作业共享相同的性能优化配置。
- 更好的性价比:适当大小的资源可减少浪费并提高吞吐量。
- 降低操作开销:优化周期更少,支持升级更少。
先决条件
若要配置资源配置文件,必须具有工作区的 管理员 角色。
资源概要配置
若要为工作区配置资源配置文件,请执行以下操作:
转到工作区,然后选择 “工作区设置”。
在左窗格中展开 数据工程/科学 ,然后选择 Spark 设置。
若要获取建议的计算配置以优化资源使用情况,请在“ 针对用例优化”下,选择“ 入门”。
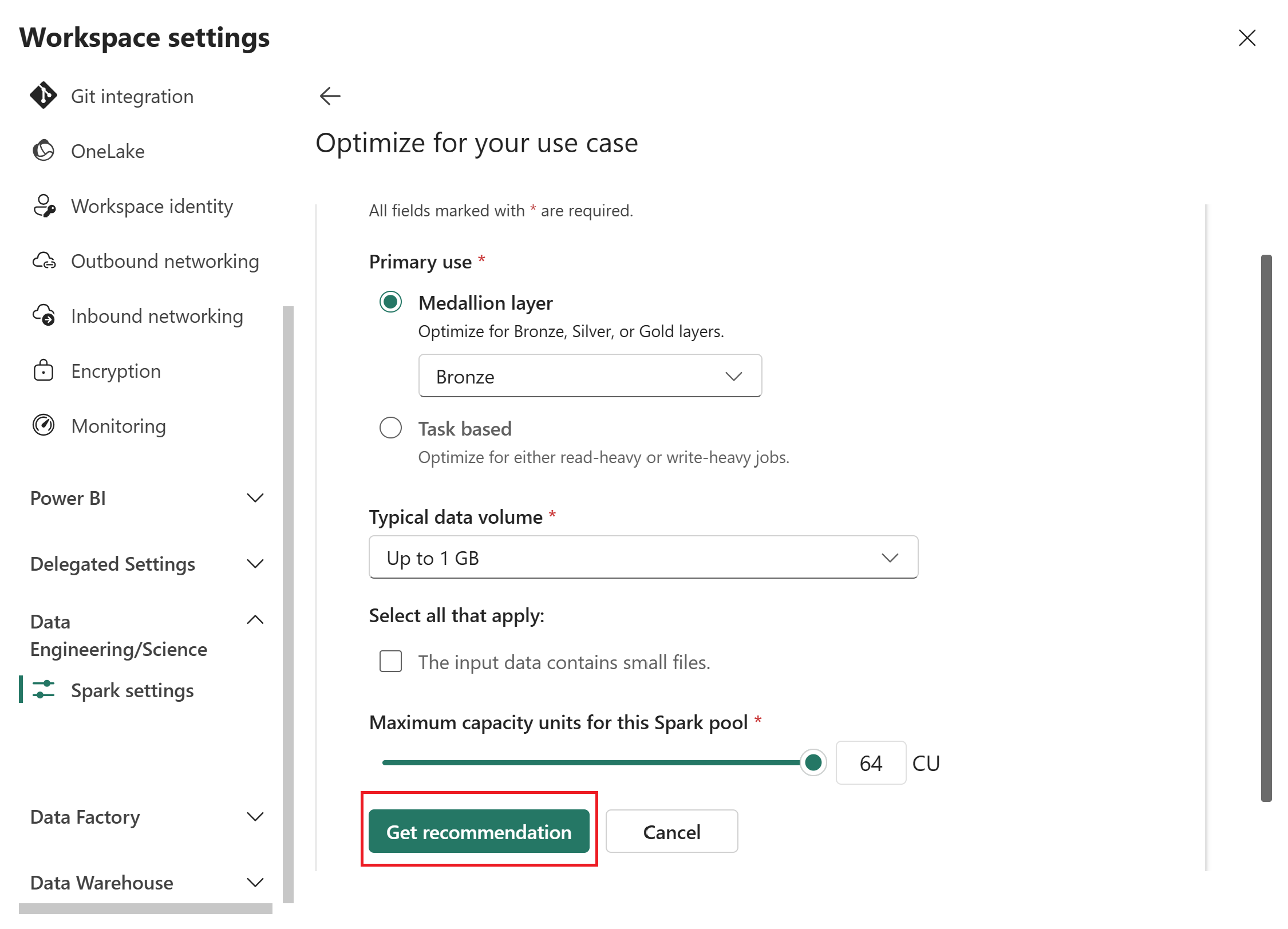
在“ 优化用例 ”页中,提供以下输入:
- 主要用例:选择Medallion 层或基于任务,然后从下拉列表中选择特定选项。 奖牌层选项为 铜牌、 银牌或 金牌。 基于任务的选项是“读取优化”或“写入优化”。 有关选择用例的指导,请参阅 主要用例参考。
- 典型数据卷:从下拉列表中选择卷:最多 1 GB、10 GB、100 GB、1 TB 或超过 1 TB。
- 最大容量单位(CU):使用滑块设置 Spark 池的最大 CU 限制。
选择“ 获取建议”。
Fabric 根据输入生成优化配置。
审查建议。 建议包含两个类别的数值:
- Spark 池:池类型、节点系列、节点大小、自动缩放和动态执行程序分配。
- 环境:运行时版本、Spark 驱动程序核心和内存、Spark 执行程序核心、内存和实例。
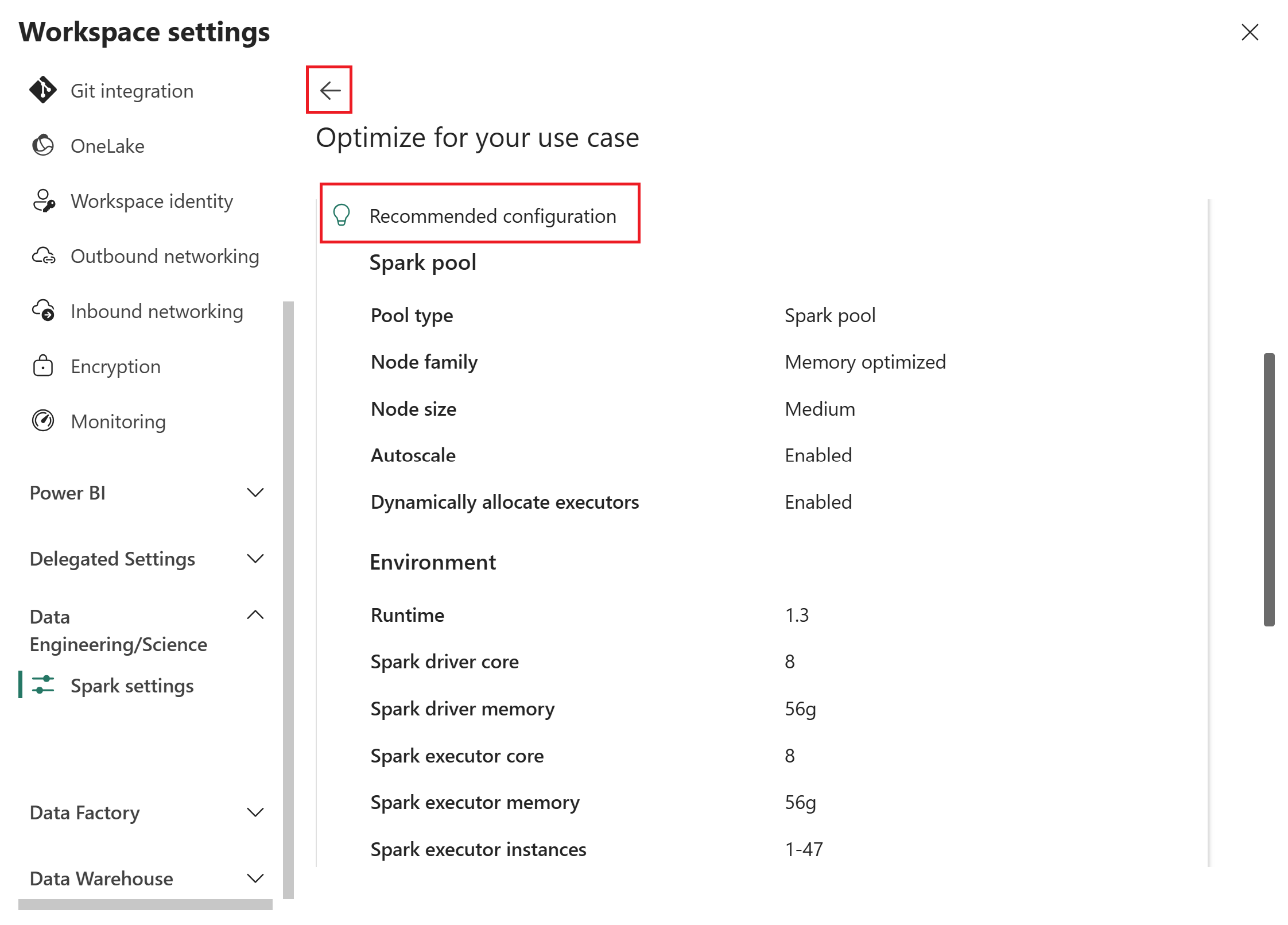
如果要调整输入,请选择后退箭头以返回到上一页,更新所选内容,然后再次选择“ 获取建议 ”。
输入配置的 Spark 池名称和环境,然后选择“应用”将其保存到工作区。
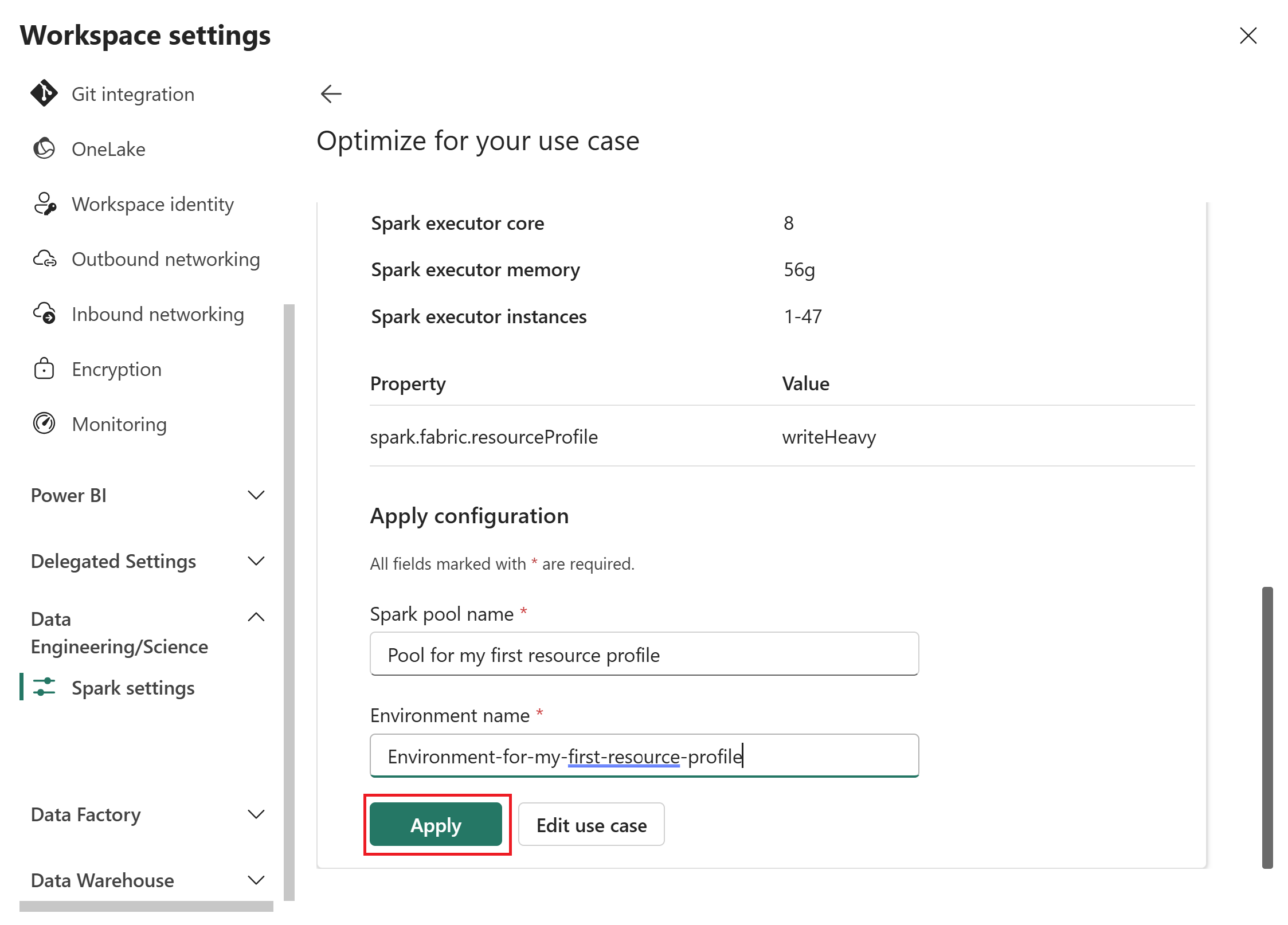




应用资源配置文件后,Fabric 会使用建议的设置创建自定义 Spark 池。
注释
如果工作区还没有自定义池,则新池会自动设置为 工作区的默认池。 如果工作区已有默认池,则需要在 Spark 工作区设置中手动切换到新池。 活动会话在重新启动之前不会受到影响。
主要用例参考
配置资源配置文件时,使用以下指南选择正确的主要用例输入:
徽章层
如果您的数据管道遵循奖牌架构模式,请选择 奖牌层,在这种模式下,数据通过铜(原始)、银(已清理)和金(特选)阶段移动。 每个选项都会调整计算,以适应该阶段典型的读/写特性。
| 用例 | 何时使用 |
|---|---|
| 青铜 | 原始数据引入、高写入吞吐量、多种格式 |
| 银 | 清理和丰富化,使用适度的联接实现平衡的读写操作 |
| 金 | 聚合和报告,针对分析和 Power BI 进行读取优化 |
基于任务
如果负载不遵循奖牌模式,或者由单一访问模式主导,请选择任务导向。 例如,将此选项用于独立的 ETL 作业、交互式分析笔记本或流式处理管道。
| 用例 | 何时使用 |
|---|---|
| 读取优化 | 频繁读取和查询、交互式笔记本 |
| 写入优化 | 大规模引入、ETL 管道、流式处理 |