本文介绍如何在 Microsoft Fabric 中为分析工作负荷创建自定义 Apache Spark 池。 借助 Apache Spark 池,可以根据需求创建定制的计算环境,以便获得最佳性能和资源使用。
指定自动缩放的最小节点和最大节点数。 当作业的计算需求发生变化时,系统会获取和停用节点,因此缩放效率高,性能会提高。 Spark 池会自动调整执行程序的数量,因此无需手动设置它们。 系统根据数据量和作业计算需求更改执行程序计数,因此你可以专注于工作负荷,而不是性能优化和资源管理。
小窍门
配置 Spark 池时,节点大小由 容量单位(CU)确定,表示分配给每个节点的计算容量。 有关节点大小和 CU 的详细信息,请参阅本指南中的 “节点大小选项” 部分。
先决条件
若要创建自定义 Spark 池,请确保你对工作区具有管理员访问权限。 容量管理员在容量管理员设置的 Spark 计算部分中启用“自定义工作区池”选项。 有关详细信息,请参阅 Fabric 容量的 Spark 计算设置。
创建自定义 Spark 池
若要创建或管理与工作区关联的 Spark 池,请执行以下操作:
转到工作区并选择“工作区设置”。
选择 数据工程/科学 选项以展开菜单,然后选择 Spark 设置。

选择“新建池”选项。 在“创建池”屏幕中,对 Spark 池命名。 此外,请选择 节点系列,并根据工作负荷的计算要求从可用大小(小型、中型、大型、X 大型和 XX 大型)中选择 节点 大小。
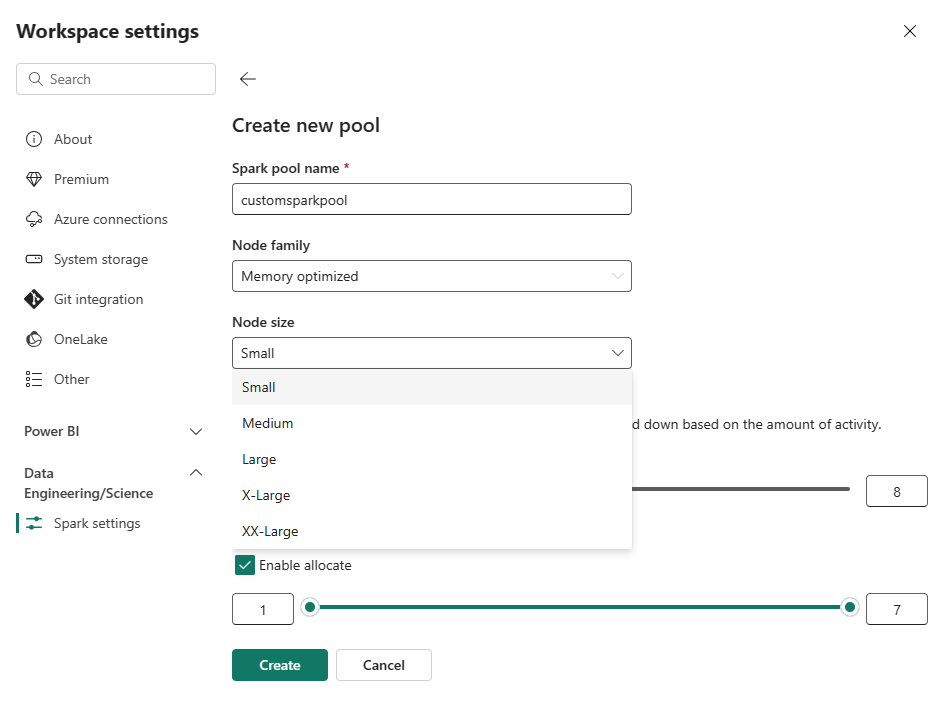
可以将自定义池的最小节点配置设置为 1。 由于 Fabric Spark 为具有单个节点的群集提供可还原的可用性,因此无需担心作业故障、故障期间会话丢失或为较小的 Spark 作业支付计算费用。
可以为自定义 Spark 池启用或禁用自动缩放。 启用自动缩放后,池会动态获取新节点,达到用户指定的最大节点限制,然后在作业执行后移除它们。 此功能通过根据作业要求调整资源来确保更好的性能。 你可以调整节点的大小,这些节点适合作为 Fabric 容量 SKU 的一部分购买的容量单位。
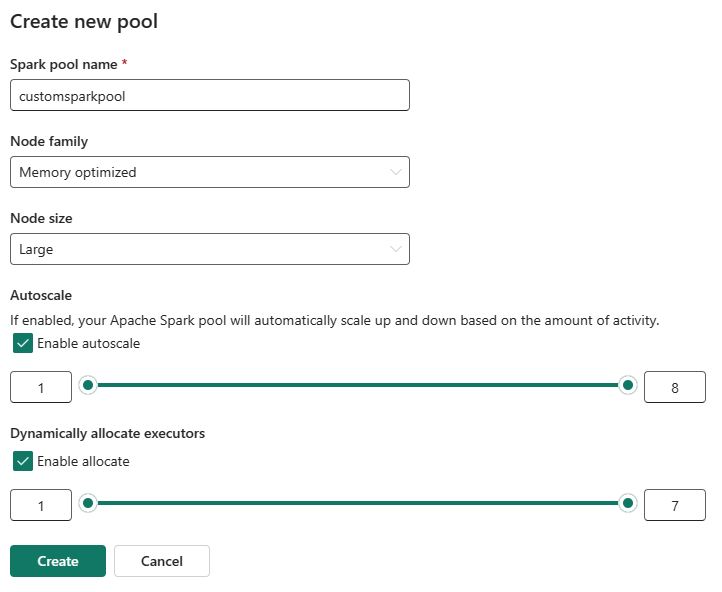
可以使用滑块调整执行程序的数量。 每个执行程序都是一个 Spark 进程,用于运行任务并在内存中保存数据。 增加执行程序可以提高并行度,但它也会增加群集的大小和启动时间。 还可以选择为 Spark 池启用动态执行程序分配,该池会自动确定用户指定的最大边界内的最佳执行程序数。 此功能根据数据量调整执行程序的数量,从而提高了性能和资源利用率。



这些自定义池的默认自动暂停时间是在非活动状态持续时间到期后为2分钟。 达到自动暂停持续时间后,会话将过期,群集将取消分配。 将据节点数和使用自定义 Spark 池的持续时间向你收费。
注意
Microsoft Fabric 中的自定义 Spark 池目前支持最大节点限制 200。 配置自动缩放或设置手动节点计数时,请确保最小值和最大值保持在此限制范围内。 超出此限制将导致池创建或更新期间出现验证错误。
节点大小选项
设置自定义 Spark 池时,请从以下节点大小中进行选择:
| 节点大小 | 容量单位(CU) | 内存 (GB) | DESCRIPTION |
|---|---|---|---|
| 小型 | 4 | 32 | 用于轻型开发和测试作业。 |
| 中等 | 8 | 64 | 对于常规任务量和典型操作。 |
| 大 | 16 | 128 | 对于内存密集型任务或大型数据处理作业。 |
| X-大 | 32 | 256 | 对于需要大量资源的最苛刻的 Spark 工作负载。 |
注意
Microsoft Fabric Spark 池中的容量单位(CU)表示分配给每个节点的计算容量,而不是实际消耗量。 容量单位不同于基于 SQL 的 Azure 资源中使用的 VCore(虚拟核心)。 CU 是 Fabric 中的 Spark 池的标准术语,而 VCore 对于 SQL 池更为常见。 调整节点大小时,利用 CU 来确定 Spark 工作负载的分配容量。
相关内容
- 从 Apache Spark 公共文档中了解详细信息。
- 请在 Microsoft Fabric中,开始设置
Spark 工作区管理。