支撑大小调整、优化和故障排除的核心概念。 如果你不熟悉 Fabric 中的 Spark,请先阅读此内容。
常规注意事项
场景:你对 Spark 不熟悉。 注意事项是什么
| 用例 | 最佳做法 |
|---|---|
| 使用优化的序列化格式 | 建议:优先选择 Avro、Parquet 或者 ORC(Optimized Row Columnar)这样的格式,因为它们嵌入架构、具有更高的压缩率,并且优化存储和处理效率。 在 Fabric 平台中,使用 Delta 格式,以确保原子性、一致性、隔离性、持久性(ACID)以及性能优势。 |
| 请谨慎使用 XML/JSON | 不要依赖大型 JavaScript 对象表示法(JSON)或可扩展标记语言(XML)文件的架构推理,因为 Spark 读取整个数据集来推断架构,这会减慢处理速度,消耗大量内存。 在读取 JSON/XML 时,提供静态主架构,或使用 .option("samplingRatio", 0.1) 加快读取速度,但请注意,如果示例不代表完整数据集,读取可能会失败。 一种更安全的方法是从具有代表性的样本中推断出架构,并将该架构保留用于所有读取操作。避免分析大型 XML 文件。 由于标记处理和类型强制转换,XML 分析本身运行速度会变慢。 |
| 优化联接和筛选 | 请在联接之前应用列修剪和行级筛选,以减少数据混洗处理和内存使用量。 使用 DataFrame API 时,Catalyst 优化器会自动处理谓词下推。 避免弹性分布式数据集 (RDD) API,因为它们绕过催化剂优化。 |
| 首选DataFrame而不是RDD | 要做到:在大多数操作中使用数据帧而不是 RDD。 数据帧使用 Catalyst 优化器和 Tungsten 执行引擎来高效执行。 |
| 启用自适应查询执行(AQE) | 启用 AQE 以动态优化洗牌分区,并自动处理数据倾斜问题。 |
执行程序内存管理
方案:你想要了解性能优化的执行程序内存管理。
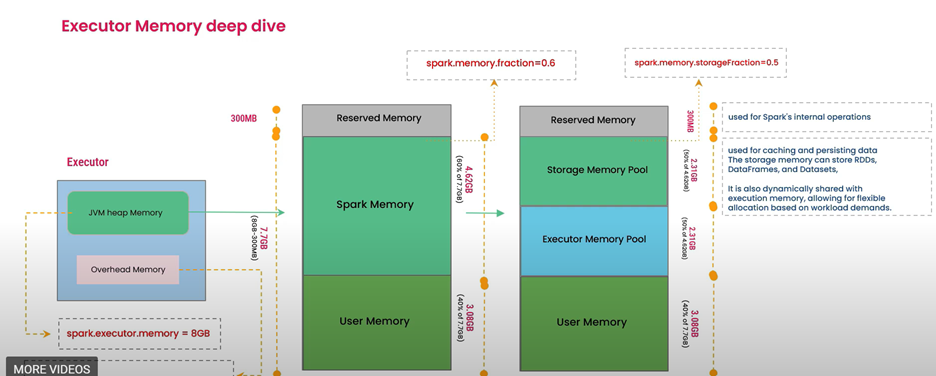
即使执行程序配置了 56 GB 内存,Spark 也不允许将其全部直接用于用户数据。 Spark Core 划分和管理执行程序内存:
保留内存: 为系统和 Spark 内部开销保留的固定部分(例如 Java 虚拟机(JVM),内部部分。
用户内存: 存储用户定义的函数(UDF)、局部变量、数据结构(列表、地图、字典)和计算期间创建的对象。
存储内存: 用于保存缓存/持久化数据、广播变量以及可缓存的 shuffle 数据。
执行内存: 用于中间计算(随机计算、联接、排序、聚合)。
动态内存共享: 存储和执行内存之间的边界是可移动的。 Spark 可以将内存从一个区域借给另一个区域,从而允许灵活的内存使用。
泄漏: 当存储或执行内存需求超出借款后可用的内存时发生。 这会强制数据到磁盘,这可能会影响性能。

内存不足(OOM)错误
场景:Spark 作业因内存不足(OOM)错误而失败。
驱动程序 OOM:
当 Spark 驱动程序超出其分配的内存时,会发生驱动程序 OOM 错误。
常见原因:驱动程序密集型操作,例如collect()、countByKey()或将大量数据拉入驱动程序内存中的大型toPandas()调用。
缓解:尽可能避免驱动程序密集型操作。 如果不可避免,请增加驱动程序大小和基准以查找最佳配置。
执行程序内存不足(OOM):
当 Spark 执行程序超出其分配的内存时,会发生执行程序 OOM 错误。
常见原因:大型数据集上的内存和计算密集型转换(例如,宽联接、聚合、随机排列)或缓存/持久化数据集,这些数据集超出了执行程序的可用内存(执行 + 存储区域)。
缓解:如有必要,增加执行程序内存,优化 Spark 内存分数(spark.memory.fraction,spark.memory.storageFraction),并选择性地保留。 确保缓存的数据适合可用内存。
数据倾斜
偏差的症状:
- 在 Spark UI 中,某些任务的执行时间比其他任务更长(阶段任务显示长尾效应)。
- 阶段指标中位数和最大任务时间之间的较大差距。
- 对于几个分区,具有大型随机读取或写入大小的阶段。
常见原因:
- 联接/组键(热键)的数据分布不均衡。
- 数据卷的分区不正确或分区太少。
- 生成大型记录或多个 null/空键的上游数据异常。
缓解:
- 重新分区或合并以提高分区并行度和平衡大小。
- 使用键加盐或自定义分区,以跨分区分散热点键。
- 使用 AQE(自适应查询执行)合并洗牌后分区并启用偏斜连接优化。
- 对小型查找表使用广播连接以完全避免数据混洗。
- 在成本高昂的阶段之前保留均衡的中间数据集,然后重新运行作业。
UDF 最佳做法
场景:需要应用无法通过内置 DataFrame 函数表示的自定义逻辑。
尽可能使用 Spark 数据帧 API。 Catalyst 优化器优化内置函数,并在 JVM 上本机运行它们,从而提供最佳性能。
如果必须使用 UDF(用户定义的函数),请避免常规 PySpark Python UDF。 相反,请考虑以下替代方法:
Pandas UDF(也称为矢量化 UDF):使用 Apache Arrow 在 JVM 和 Python 之间高效传输数据。 Pandas UDF 允许矢量化作,与逐行 Python UDF 相比,性能显著提高。
Scala/Java UDF:直接在 JVM 上运行,避免 Python 序列化开销。 Scala/Java UDF 通常优于 Python UDF。
请谨慎使用 Python UDF。 每个执行程序都会启动单独的 Python 进程,需要在 JVM 和 Python 之间对数据进行序列化和反序列化。 这会产生性能瓶颈,尤其是在规模上。
错误日志记录
方案:在 Fabric Spark 中记录错误日志的最佳实践
使用
log4j而不是print()给司机带来沉重负担。 使用log4j时,可以访问驱动程序日志中的日志并搜索它们(例如,使用记录器名称,例如:PySparkLogger)。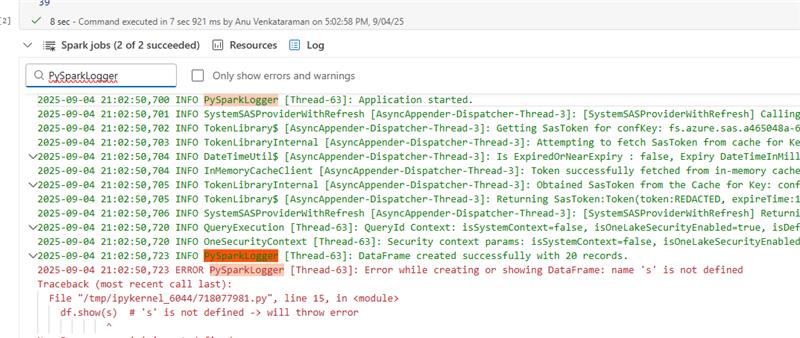
在 try 和 except 块中包装读取、写入和转换。 使用
logger.error处理异常,使用logger.info发送进度消息。Python 日志记录: 非常适合记录仅在 Spark 驱动程序上执行的代码中的作、状态更新或调试信息。 Python 的日志记录模块不会传播到执行程序日志。 请参阅 开发、执行和管理笔记本文档。
Spark log4j: 在 Spark 中,log4j 是可靠的生产级别应用程序日志记录标准,因为它与 Spark 的驱动程序/执行程序日志天然集成。
PySpark 中的 log4j 用法示例:
import traceback # Get log4j logger log4jLogger = spark._jvm.org.apache.log4j logger = log4jLogger.LogManager.getLogger("PySparkLogger") logger.info("Application started.") try: # Create DataFrame with 20 records data = [(f"Name{i}", i) for i in range(1, 21)] # 20 records df = spark.createDataFrame(data, ["name", "age"]) logger.info("DataFrame created successfully with 20 records.") df.show(s) # 's' is not defined -> will throw error but the application will not fail except Exception as e: logger.error(f"Error while creating or showing DataFrame: {str(e)}\n{traceback.format_exc()}")错误监控中心化:
在环境中使用诊断发射器扩展(使用 Azure Log Analytics 监视 Apache Spark 应用程序),并将其附加到运行 Spark 应用程序的 Notebook。 发出器可以将事件日志、自定义日志(如 log4j)和指标发送到 Azure Log Analytics/Azure 存储/Azure 事件中心。 将 log4j 名称传递给属性:
spark.synapse.diagnostic.emitter.\<destination\>.filter.loggerName.match.此外,为了调试,还可以将失败的行/记录收集到 Lakehouse (LH) 表,以捕获记录级别的错误数据。
