Fabric 用户数据函数编程模型定义在 Fabric 中创作函数的模式和概念。
fabric-user-data-functions SDK 实现此编程模型,提供创作和发布可运行函数所需的功能。 SDK 还支持与 Fabric 生态系统中的其他项(如 Fabric 数据源)无缝集成。
此库在 PyPI 中公开发布并在用户数据函数项中预安装。
本文介绍如何使用 SDK 生成可以使用 REST API 从 Fabric 门户、其他 Fabric 项或外部应用程序调用的函数。 你通过实际示例了解编程模型和关键概念。
小窍门
有关所有类、方法和参数的完整详细信息,请参阅 SDK 参考文档。
开始使用 SDK
本部分介绍用户数据函数 SDK 的核心组件,并介绍如何构建函数。 你了解所需的导入、修饰器和函数可以处理的输入和输出数据类型。
用户数据函数 SDK
SDK fabric-user-data-functions 提供在 Python 中创建用户数据函数所需的核心组件。
必需的导入和初始化
每个用户数据文件都必须导入 fabric.functions 模块并初始化执行上下文:
import datetime
import fabric.functions as fn
import logging
udf = fn.UserDataFunctions()
@udf.function()修饰器
使用 @udf.function() 修饰器标记的函数可以从 Fabric 门户、另一个 Fabric 项或外部应用程序调用。 具有此修饰器的函数必须指定返回类型。
示例:
@udf.function()
def hello_fabric(name: str) -> str:
logging.info('Python UDF trigger function processed a request.')
logging.info('Executing hello fabric function.')
return f"Welcome to Fabric Functions, {name}, at {datetime.datetime.now()}!"
帮助函数
不能直接调用没有 @udf.function() 修饰器的 Python 方法。 它们只能从被修饰的函数中调用,并充当辅助函数。
示例:
def uppercase_name(name: str) -> str:
return name.upper()
支持的输入类型
可以为函数定义输入参数,例如 str、int、float 等基元数据类型。支持的输入数据类型为:
| JSON 类型 | Python 数据类型 |
|---|---|
| 字符串 | str |
| 日期/时间字符串 | 日期/时间 |
| 布尔值 | 布尔 |
| 数字 | int、float |
| 数组 | list[],例如 list[int] |
| 对象 | dict |
| 对象 | pandas 数据框架 (DataFrame) |
| 对象 或 对象的数组 | pandas 系列 |
注释
若要使用 pandas DataFrame 和 Series 类型,请进入 Fabric 门户,找到您的工作区,然后打开用户数据功能项。 选择 库管理,搜索 fabric-user-data-functions 包,并将其更新到版本 1.0.0 或更高版本。
支持的输入类型的请求正文示例:
{
"name": "Alice", // String (str)
"signup_date": "2025-11-08T13:44:40Z", // Datetime string (datetime)
"is_active": true, // Boolean (bool)
"age": 30, // Number (int)
"height": 5.6, // Number (float)
"favorite_numbers": [3, 7, 42], // Array (list[int])
"profile": { // Object (dict)
"email": "alice@example.com",
"location": "Sammamish"
},
"sales_data": { // Object (pandas DataFrame)
"2025-11-01": {"product": "A", "units": 10},
"2025-11-02": {"product": "B", "units": 15}
},
"weekly_scores": [ // Object or Array of Objects (pandas Series)
{"week": 1, "score": 88},
{"week": 2, "score": 92},
{"week": 3, "score": 85}
]
}
支持的输出类型
支持的输出数据类型为:
| Python 数据类型 |
|---|
| str |
| 日期/时间 |
| 布尔 |
| int、float |
| list[data-type],例如 list[int] |
| dict |
| 没有 |
| pandas 系列 |
| pandas 数据框架 (DataFrame) |
编写函数
语法要求和限制
编写用户数据函数时,必须遵循特定的语法规则,以确保函数正常工作。
参数命名
-
使用 camelCase:参数名称必须使用 camelCase 命名约定,并且不能包含下划线。 例如,请使用
productName而不是product_name。 -
保留关键字:不能将保留的 Python 关键字或以下特定于 Fabric 的关键字用作参数名称或函数名称:
req,context以及reqInvocationId。
参数要求
需要类型批注:所有参数都必须包含类型批注(例如,
name: str)。默认值:支持默认参数值。 可以在 Fabric 用户数据函数中定义默认参数,使代码更易于调用和维护。 具有默认值的参数在调用时是可选的;需要不带默认值的参数。 支持以下类型作为默认值:
默认类型 Notes String 任何 JSON 可序列化字符串。 日期时间字符串 在函数签名中指定为字符串。 在调用时,运行时将字符串解析为 datetime。 使用 ISO 8601 格式(例如,2025-12-31T23:59:59Z)进行一致的明确分析。布尔 True或False。Integer 任何整数值。 Float 任何浮点值。 列表 必须是 JSON 可序列化的。 首选 None在签名中,并在函数中分配实际默认值,以避免共享可变默认值。字典 必须是 JSON 可序列化的。 首选 None在签名中,并在函数中分配实际默认值。pandas 数据框架 (DataFrame) 作为 SDK 转换为 pandas 类型的 JSON 对象提供。 fabric-user-data-functions需要版本 1.0.0 或更高版本。pandas 系列 作为 JSON 对象数组提供,SDK 会将其转换为 pandas 类型。 fabric-user-data-functions需要版本 1.0.0 或更高版本。语法
@udf.function() def function_name( requiredParam: str, optionalStr: str = "hello", optionalDate: datetime.datetime = "2025-01-01T00:00:00Z", # specify as a string; the runtime parses it to datetime at invocation time optionalBool: bool = True, optionalInt: int = 10, optionalFloat: float = 1.5, optionalList: list | None = None, # assign real default inside the function optionalDict: dict | None = None, # assign real default inside the function ) -> dict: optionalList = optionalList or [1, 2, 3] optionalDict = optionalDict or {"key": "value"} return {"param": requiredParam}默认值必须为 JSON 可序列化(不支持集和元组)。 对于列表或字典默认值,在
None签名中使用,并在函数中分配实际默认值,以避免共享可变默认值。 对于日期/时间默认值,请使用 ISO 8601 格式(例如,2025-12-31T23:59:59Z)。 将 pandas DataFrame 或 Series 用作默认版本需要fabric-user-data-functions1.0.0 或更高版本。
函数要求
-
需要返回类型:具有
@udf.function()修饰器的函数必须指定返回类型批注(例如,-> str)。 -
必需的导入:您的函数需要
import fabric.functions as fn语句和udf = fn.UserDataFunctions()初始化才能正常工作。
正确的语法示例
@udf.function()
def process_order(orderNumber: int, customerName: str, orderDate: str) -> dict:
return {
"order_id": orderNumber,
"customer": customerName,
"date": orderDate,
"status": "processed"
}
如何编写异步函数
在代码中的函数定义上添加异步装饰器。 借助函数 async ,可以通过同时处理多个任务来提高应用程序的响应能力和效率。 它们非常适合管理大量 I/O 绑定操作。 此示例函数使用 pandas 从 lakehouse 读取 CSV 文件。 函数采用文件名作为输入参数。
import pandas as pd
# Replace the alias "<My Lakehouse alias>" with your connection alias.
@udf.connection(argName="myLakehouse", alias="<My Lakehouse alias>")
@udf.function()
async def read_csv_from_lakehouse(myLakehouse: fn.FabricLakehouseClient, csvFileName: str) -> str:
# Connect to the Lakehouse
connection = myLakehouse.connectToFilesAsync()
# Download the CSV file from the Lakehouse
csvFile = connection.get_file_client(csvFileName)
downloadFile = await csvFile.download_file()
csvData = await downloadFile.readall()
# Read the CSV data into a pandas DataFrame
from io import StringIO
df = pd.read_csv(StringIO(csvData.decode('utf-8')))
# Display the DataFrame
result=""
for index, row in df.iterrows():
result=result + "["+ (",".join([str(item) for item in row]))+"]"
# Close the connection
csvFile.close()
connection.close()
return f"CSV file read successfully.{result}"
使用数据
与 Fabric 数据源的数据连接
SDK 允许引用 数据连接 ,而无需在代码中编写连接字符串。
fabric.functions 库提供两种方法来处理数据连接:
- fabric.functions.FabricSqlConnection:支持在 Fabric 中使用 SQL 数据库,包括 SQL Analytics 终结点和 Fabric 仓库。
- fabric.functions.FabricLakehouseClient:可用于操作湖屋,并提供一种方法连接到湖屋中的表和文件。
若要引用与数据源的连接,需要使用 @udf.connection 修饰器。 可以采用以下任何格式应用它:
@udf.connection(alias="<alias for data connection>", argName="sqlDB")@udf.connection("<alias for data connection>", "<argName>")@udf.connection("<alias for data connection>")
@udf.connection 的参数为:
-
argName,连接在函数中使用的变量的名称。 -
alias,使用“管理连接”菜单添加的连接的别名。 - 如果
argName和alias的值相同,则可以使用@udf.connection("<alias and argName for the data connection>")。
示例
# Where demosqldatabase is the argument name and the alias for my data connection used for this function
@udf.connection("demosqldatabase")
@udf.function()
def read_from_sql_db(demosqldatabase: fn.FabricSqlConnection)-> list:
# Connect to the SQL database
connection = demosqldatabase.connect()
cursor = connection.cursor()
# Replace with the query you want to run
query = "SELECT * FROM (VALUES ('John Smith', 31), ('Kayla Jones', 33)) AS Employee(EmpName, DepID);"
# Execute the query
cursor.execute(query)
# Fetch all results
results = cursor.fetchall()
# Close the cursor and connection
cursor.close()
connection.close()
return results
Fabric 项目或 Azure 资源的通用连接
SDK 支持通过用户数据函数项所有者身份创建到 Fabric 项目或 Azure 资源的通用连接。 此功能生成一个Microsoft Entra ID令牌,其中包含项目所有者的身份和指定的受众类型。 此令牌用于对支持该受众类型的 Fabric 项或Azure资源进行身份验证。 此方法提供与使用 “管理连接”功能 中的托管连接对象类似的编程体验,但仅适用于连接中提供的受众类型。
此功能使用带有以下参数的 @udf.generic_connection() 修饰器。
| 参数 | 说明 | 价值 |
|---|---|---|
argName |
传递给函数的变量的名称。 用户需要在函数的参数中指定此变量,并使用其类型fn.FabricItem |
例如,如果为 argName=CosmosDb,则函数应包含此参数 cosmosDb: fn.FabricItem |
audienceType |
为其创建连接的受众类型。 此参数与 Fabric 项或Azure服务的类型相关联,并确定用于连接的客户端。 | 此参数 CosmosDb 的允许值为或 KeyVault。 |
使用通用连接连接到 Fabric Cosmos DB 容器
通用连接使用 CosmosDB 受众类型支持原生 Fabric Cosmos DB 项。 包含的用户数据函数 SDK 提供了一种名为 get_cosmos_client 的帮助程序方法,用于在每次调用时获取单一实例 Cosmos DB 客户端。
可以按照以下步骤使用泛型连接连接到 Fabric Cosmos DB 项 :
转到 Fabric 门户,找到工作区,并打开用户数据函数项。 选择 Library 管理,搜索
azure-cosmos库并安装它。 有关详细信息,请参阅 “管理库”。转到 Fabric Cosmos DB 项 设置。
检索 Fabric Cosmos DB 终结点 URL。
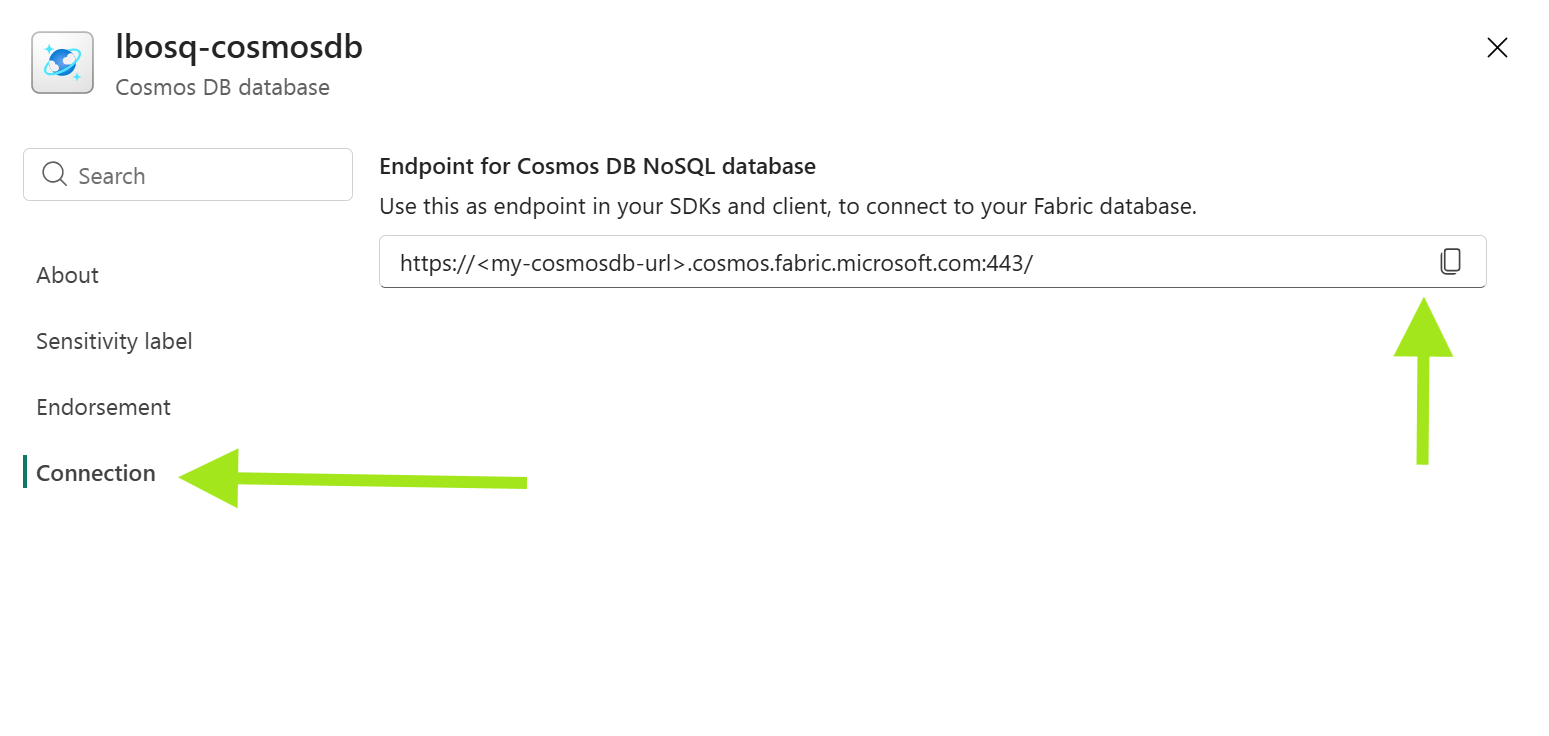
转到 用户数据功能选项。 使用以下示例代码连接到 Fabric Cosmos DB 容器,并使用 Cosmos DB 示例数据集运行读取查询。 替换以下变量的值:
-
COSMOS_DB_URI使用 Fabric Cosmos DB 终结点。 - 将
DB_NAME填入您的 Fabric Cosmos DB 项目名称。
from fabric.functions.cosmosdb import get_cosmos_client import json @udf.generic_connection(argName="cosmosDb", audienceType="CosmosDB") @udf.function() def get_product_by_category(cosmosDb: fn.FabricItem, category: str) -> list: COSMOS_DB_URI = "YOUR_COSMOS_DB_URL" DB_NAME = "YOUR_COSMOS_DB_NAME" # Note: This is the Fabric item name CONTAINER_NAME = "SampleData" # Note: This is your container name. In this example, we are using the SampleData container. cosmosClient = get_cosmos_client(cosmosDb, COSMOS_DB_URI) # Get the database and container database = cosmosClient.get_database_client(DB_NAME) container = database.get_container_client(CONTAINER_NAME) query = 'select * from c WHERE c.category=@category' #"select * from c where c.category=@category" parameters = [ { "name": "@category", "value": category } ] results = container.query_items(query=query, parameters=parameters) items = [item for item in results] logging.info(f"Found {len(items)} products in {category}") return json.dumps(items)-
通过提供类别名称(例如在调用参数中)
Accessory。


注释
还可以使用这些步骤通过帐户 URL 和数据库名称连接到 Azure Cosmos DB 数据库。 用户数据函数所有者帐户需要获得该 Azure Cosmos DB 帐户的访问权限。
使用泛型连接连接到Azure 密钥保管库
泛型连接支持使用KeyVault 受众类型连接到 Azure 密钥保管库。 这种类型的连接要求 Fabric 用户数据函数所有者有权连接到Azure 密钥保管库。 可以使用此连接按名称检索密钥、机密或证书。
可以连接到 Azure 密钥保管库,通过以下步骤检索客户端机密以使用泛型连接调用 API:
转到 Fabric 门户,找到工作区,并打开用户数据函数项。 选择 Library 管理,然后搜索并安装
requests和azure-keyvault-secrets库。 有关详细信息,请参阅 “管理库”。转到 Azure portal 中的 Azure 密钥保管库 资源,然后检索密钥、机密或证书的名称和
Vault URI。
回到您的Fabric 用户数据函数项并使用此示例。 在此示例中,我们从Azure 密钥保管库检索机密以连接到公共 API。 替换以下变量的值:
- 使用在上一步中检索到的
KEY_VAULT_URLVault URI。 -
KEY_VAULT_SECRET_NAME以您的机密名称。 -
API_URL变量,其中包含要连接到的 API 的 URL。 此示例假定你连接到接受 GET 请求的公共 API,并采用以下参数api-key和request-body。
from azure.keyvault.secrets import SecretClient from azure.identity import DefaultAzureCredential import requests @udf.generic_connection(argName="keyVaultClient", audienceType="KeyVault") @udf.function() def retrieveNews(keyVaultClient: fn.FabricItem, requestBody:str) -> str: KEY_VAULT_URL = 'YOUR_KEY_VAULT_URL' KEY_VAULT_SECRET_NAME= 'YOUR_SECRET' API_URL = 'YOUR_API_URL' credential = keyVaultClient.get_access_token() client = SecretClient(vault_url=KEY_VAULT_URL, credential=credential) api_key = client.get_secret(KEY_VAULT_SECRET_NAME).value api_url = API_URL params = { "api-key": api_key, "request-body": requestBody } response = requests.get(api_url, params=params) data = "" if response.status_code == 200: data = response.json() else: print(f"Error {response.status_code}: {response.text}") return f"Response: {data}"- 使用在上一步中检索到的
通过在代码中提供请求正文来测试或运行此函数。

高级功能
编程模型定义了高级模式,可更好地控制函数。 SDK 通过类和方法实现这些模式,使你能够:
- 访问关于谁调用了你的函数以及调用方式的元数据
- 使用结构化错误响应处理自定义错误情境
- 与 Fabric 变量库集成,以便进行集中配置管理
注释
用户数据函数对请求大小、执行超时和响应大小具有服务限制。 有关这些限制及其强制实施方式的详细信息,请参阅 服务详细信息和限制。
使用 UserDataFunctionContext 获取调用属性
SDK 包括对象 UserDataFunctionContext 。 此对象包含函数调用元数据,可用于为不同的调用机制(例如门户调用与 REST API 调用)创建特定的应用逻辑。
下表显示了 UserDataFunctionContext 对象的属性:
| 属性名称 | 数据类型 | 说明 |
|---|---|---|
| invocation_id | 字符串 | 绑定到用户数据函数调用项的唯一 GUID。 |
| 执行用户 | 对象 | 用于授权调用的用户信息的元数据。 |
executing_user 对象包含以下信息:
| 属性名称 | 数据类型 | 说明 |
|---|---|---|
| OID (对象标识符) | 字符串 (GUID) | 用户的对象 ID,它是请求者的不可变标识符。 这是用于跨应用程序调用此函数的用户或服务主体的验证标识。 |
| 租户ID | 字符串 (GUID) | 用户登录到的租户的 ID。 |
| 首选用户名 | 字符串 | 调用用户的首选用户名,由用户设置。 此值是可变的。 |
若要access UserDataFunctionContext 参数,必须在函数定义顶部使用以下修饰器:@udf.context(argName="<parameter name>")
示例
@udf.context(argName="myContext")
@udf.function()
def getContext(myContext: fabric.functions.UserDataFunctionContext)-> str:
logging.info('Python UDF trigger function processed a request.')
return f"Hello oid = {myContext.executing_user['Oid']}, TenantId = {myContext.executing_user['TenantId']}, PreferredUsername = {myContext.executing_user['PreferredUsername']}, InvocationId = {myContext.invocation_id}"
使用 UserThrownError 引发已处理的错误
开发函数时,可以使用 SDK 中提供的类引发预期的错误响应 UserThrownError 。 此类的一个用法是管理用户提供的输入无法通过业务验证规则的情况。
示例
import datetime
@udf.function()
def raise_userthrownerror(age: int)-> str:
if age < 18:
raise fn.UserThrownError("You must be 18 years or older to use this service.", {"age": age})
return f"Welcome to Fabric Functions at {datetime.datetime.now()}!"
类 UserThrownError 构造函数采用两个参数:
-
Message:此字符串作为错误消息返回给调用此函数的应用程序。 - 属性字典将返回到调用此函数的应用程序。
从 Fabric 变量库获取变量
Microsoft Fabric中的 Fabric 变量库是一个集中存储库,用于管理可在工作区内的不同项中使用的变量。 它允许开发人员高效自定义和共享项配置。 如果还没有变量库,请参阅 “创建和管理变量库”。
若要在函数中使用变量库,请从用户数据函数项向其添加连接。 变量库与数据源(如 SQL 数据库和 Lakehouses)一起显示在 OneLake 目录中。
按照以下步骤在函数中使用变量库:
- 在用户数据函数项中,添加连接到变量库。 在 OneLake 目录中,找到并选择变量库,然后选择 “连接”。 请注意 Fabric 为连接生成的 别名 。
- 为变量库项添加连接修饰器。 例如,
@udf.connection(argName="varLib", alias="<My Variable Library Alias>")并将别名替换为变量库项目中新添加的连接。 - 在函数定义中,包含一个类型为
fn.FabricVariablesClient的参数。 此客户端提供使用变量库项所需的方法。 - 使用
getVariables()方法从变量库获取所有变量。 - 若要读取变量的值,请使用
["variable-name"]或.get("variable-name")。
示例
在此示例中,我们模拟生产环境和开发环境的配置方案。 此函数使用从变量库检索的值设置storage路径,具体取决于所选环境。 变量库包含一个名为ENV的变量,用户可以在其中设置值dev或prod。
@udf.connection(argName="varLib", alias="<My Variable Library Alias>")
@udf.function()
def get_storage_path(dataset: str, varLib: fn.FabricVariablesClient) -> str:
"""
Description: Determine storage path for a dataset based on environment configuration from Variable Library.
Args:
dataset_name (str): Name of the dataset to store.
varLib (fn.FabricVariablesClient): Fabric Variable Library connection.
Returns:
str: Full storage path for the dataset.
"""
# Retrieve variables from Variable Library
variables = varLib.getVariables()
# Get environment and base paths
env = variables.get("ENV")
dev_path = variables.get("DEV_FILE_PATH")
prod_path = variables.get("PROD_FILE_PATH")
# Apply environment-specific logic
if env.lower() == "dev":
return f"{dev_path}{dataset}/"
elif env.lower() == "prod":
return f"{prod_path}{dataset}/"
else:
return f"incorrect settings define for ENV variable"