在复制活动中配置 SQL Server
本文概述了如何使用数据管道中的复制活动从/向 SQL Server 复制数据。
支持的配置
有关复制活动下每个选项卡的配置,请分别转到以下各部分。
常规
若要配置“常规”设置选项卡,请参阅“常规”设置指导。
Source
SQL Server 支持复制活动的“源”选项卡下的以下属性。
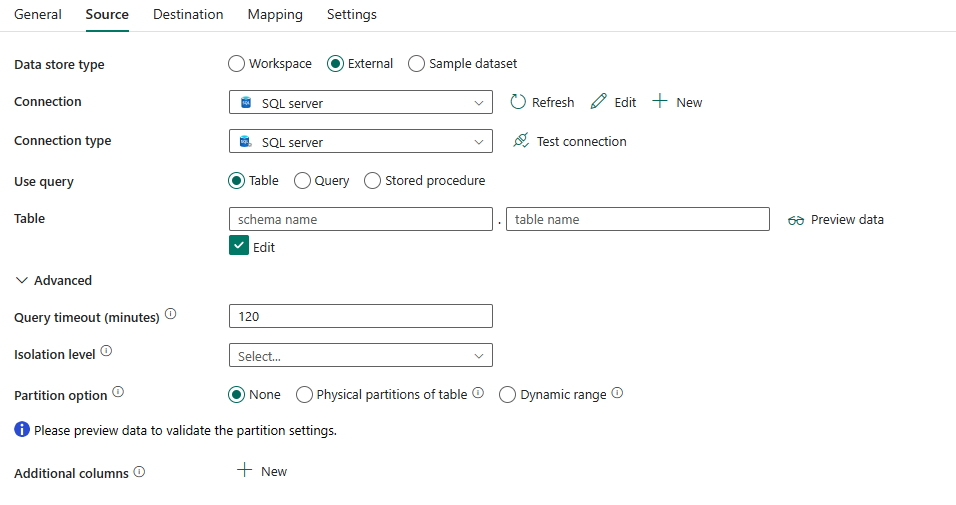
需要以下属性:
数据存储类型:选择“外部”。
连接:从连接列表中选择 SQL Server 连接。 如果连接不存在,则通过选择“新建”创建新的 SQL Server 连接。
连接类型:选择“SQL Server”。
使用查询:指定用于读取数据的方式。 可以选择“表”、“查询”或“存储过程”。 以下列表介绍了每个设置的配置:
表:从指定的表读取数据。 从下拉列表中选择源表,或选择“编辑”以手动输入。
查询:指定使用自定义 SQL 查询读取数据。 示例为
select * from MyTable。 或选择铅笔图标以在代码编辑器中编辑。
存储过程:使用从源表读取数据的存储过程的名称。 最后一个 SQL 语句必须是存储过程中的 SELECT 语句。
存储过程名称:选中“编辑”框以从源表读取数据时,选择存储过程或手动指定存储过程名称。
存储过程参数:指定存储过程参数的值。 允许的值为名称或值对。 参数的名称和大小写必须与存储过程参数的名称和大小写匹配。 可以选择“导入参数”以获取存储过程参数。


在“高级”下,可以指定以下字段:
查询超时(分钟):指定查询命令执行的超时,默认值为 120 分钟。 如果为此属性设置了参数,则允许的值是时间跨度,例如“02:00:00”(120 分钟)。
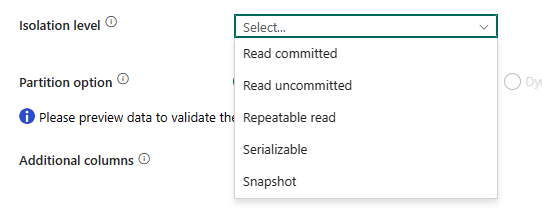
隔离级别:指定 SQL 源的事务锁定行为。 允许的值包括:“无”、“读取已提交的内容”、“读取未提交的内容”、“可重复读取”、“可序列化”或“快照”。 如果未指定,则使用数据库的默认隔离级别。 有关更多详细信息,请参阅 IsolationLevel Enum。
分区选项:指定用于从 SQL Server 加载数据的数据分区选项。 允许的值为:None(默认)、表的物理分区 和 动态范围。 启用分区选项(即,不是“无”)时,从 SQL Server 并发加载数据的并行度由“复制活动设置”选项卡中的“复制并行度”控制。
None: 选择此设置则不使用分区。
表的物理分区:使用物理分区时,将根据物理表定义自动确定分区列和机制。
动态范围:使用启用了并行的查询时,则需要范围分区参数 (
?DfDynamicRangePartitionCondition)。 示例查询:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition。分区列名称:以整数类型、日期类型或日期/时间类型(
int、smallint、bigint、date、smalldatetime、datetime、datetime2或datetimeoffset)指定源列的名称,范围分区将使用它进行并行复制。 如果未指定,系统会自动检测表的索引或主键并将其用作分区列。如果使用查询来检索源数据,请在 WHERE 子句中挂接
?DfDynamicRangePartitionCondition。 有关示例,请参阅从 SQL 数据库进行并行复制部分。分区上限:指定分区范围拆分的分区列的最大值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 有关示例,请参阅从 SQL 数据库进行并行复制部分。
分区下:指定分区范围拆分的分区列的最小值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 有关示例,请参阅从 SQL 数据库进行并行复制部分。
其他列:添加其他数据列以存储源文件的相对路径或静态值。 后者支持表达式。
请注意以下几点:
- 如果为源指定查询,则复制活动针对 SQL Server 源运行此查询以获取数据。 也可通过指定“存储过程名称”和“存储过程参数”来指定存储过程,前提是存储过程使用参数。
- 在源中使用存储过程检索数据时,请注意,如果存储过程设计为当传入不同的参数值时返回不同的架构,则从 UI 导入架构或使用自动表创建将数据复制到 SQL 数据库时,可能会遇到故障或出现意外的结果。
目标
SQL Server 在复制活动的“目标”选项卡下支持以下属性。
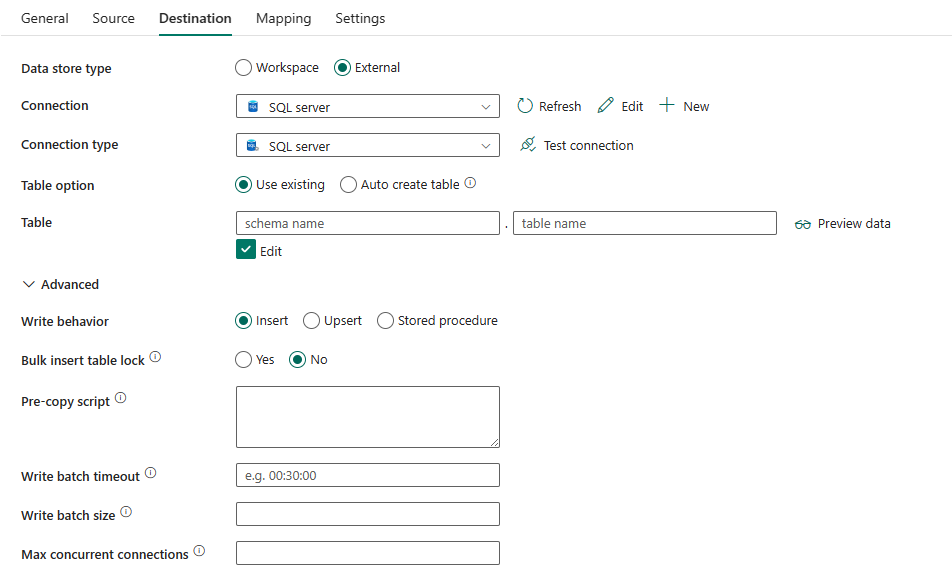
需要以下属性:
数据存储类型:选择“外部”。
连接:从连接列表中选择 SQL Server 连接。 如果连接不存在,则通过选择“新建”创建新的 SQL Server 连接。
连接类型:选择“SQL Server”。
表选项:可以选择“使用现有项”以使用指定的表。 或者选择“自动创建表”,这样即可在源架构中不存在该表时自动创建目标表,请注意,当存储过程用作写入行为时,不支持此选项。
如果选择“使用现有项”:
- 表:从下拉列表中选择目标数据库中的表。 或者,选中“编辑”以手动输入表名称。
如果选择:自动创建表:
- 表:指定自动创建的目标表的名称。
在“高级”下,可以指定以下字段:
写入行为:定义以基于文件的数据存储中的文件为源时的写入行为。 可以选择“插入”、“插入”或“存储过程”。
插入:选择此选项可使用插入写入行为将数据加载到 SQL Server 中。
更新插入:选择此选项使用更新插入写入行为将数据加载到 SQL Server 中。
使用 tempdb:指定是使用全局临时表还是物理表作为更新插入临时表。 默认情况下,服务使用全局临时表作为临时表,并会选中此属性。
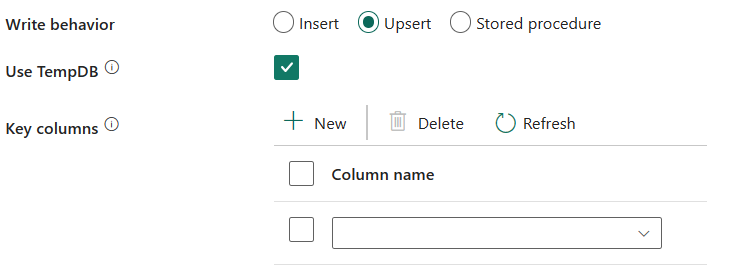
选择用户 DB 架构:未选中“使用 TempDB”时,如果使用的是物理表,请指定用于创建临时表的临时架构。
注意
必须具有创建和删除表的权限。 默认情况下,临时表将与目标表共享相同的架构。
键列:指定唯一行标识的列名称。 可使用单个键,也可使用一系列键。 如果未指定,将使用主键。
存储过程:使用定义如何将源数据应用于目标表的存储过程的名称。 此存储过程由每个批处理调用。 若要执行仅运行一次且与源数据无关的操作(例如删除或截断),请使用“复制前脚本”属性。
存储过程名称:选中“编辑”以从源表读取数据时,选择存储过程或手动指定存储过程名称。
存储过程参数:
- 标类型:指定要在存储过程中使用的表类型名称。 通过复制活动可以在具有此表类型的临时表中提供将移动的数据。 然后,存储过程代码可合并复制数据和现有数据。
- 表类型参数名称:指定存储过程中指定的表类型的参数名称。
- 参数:指定存储过程的参数值。 允许的值为名称或值对。 参数的名称和大小写必须与存储过程参数的名称和大小写匹配。 可以选择“导入参数”以获取存储过程参数。

大容量插入表锁:选择“是”或“否”(默认值)。 使用此设置可提高在不包含多个客户端索引的表上执行大容量插入操作期间的复制性能。 选择“插入”或“更新插入”作为写入行为时,可以指定此属性。 有关详细信息,请转到 BULK INSERT (Transact SQL)
复制前脚本:指定每次运行时,复制活动将数据写入到目标表之前要执行的脚本。 此属性可用于清理预先加载的数据。
写入批超时:指定超时前等待批插入操作完成的时间。允许的值为 timespan。 如果未指定值,则超时默认为“02:00:00”。
写入批处理大小:指定每个批要插入到 SQL 表中的行数。 允许的值为 integer(行数)。 默认情况下,该服务根据行大小动态确定适当的批大小。
最大并发连接:活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。

映射
对于“映射”选项卡配置,如果不将具有自动创建表的 SQL Server 应用为目的地,请转到映射。
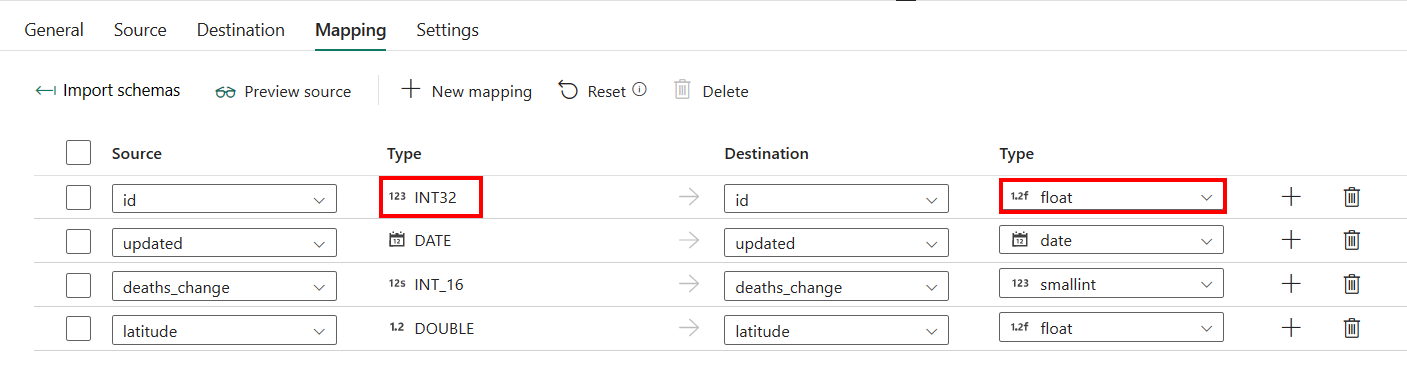
如果将具有自动创建表的 SQL Server 应用为目的地,则除了映射中的配置外,可以编辑目的地列的类型。 选择“导入架构”后,可以在目标中指定列类型。
例如,源中 ID 列的类型为 int,当映射到目的地列时,你可以将其更改为浮点类型。
设置
对于“设置”选项卡配置,请转到“设置”选项卡下的“配置其他设置”。
从 SQL 数据库进行并行复制
复制活动中的 SQL Server 连接器提供内置的数据分区,用于并行复制数据。 可以在复制活动的“源”表中找到数据分区选项。
启用分区复制时,复制活动将对 SQL Server 源运行并行查询,以按分区加载数据。 并行度由复制活动设置选项卡中的“复制并行度”控制。例如,如果将“复制并行度”设置为 4,则该服务会根据指定的分区选项和设置并行生成并运行 4 个查询,每个查询从 SQL Server 检索一部分数据。
建议同时启用并行复制和数据分区,尤其是从 SQL Server 加载大量数据时。 下面是适用于不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议将数据作为多个文件写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 方案 | 建议的设置 |
|---|---|
| 从包含物理分区的大型表进行完整加载。 | 分区选项:表的物理分区。 在执行期间,该服务将自动检测物理分区并按分区复制数据。 若要检查表是否有物理分区,可参考此查询。 |
| 从不包含物理分区但包含用于数据分区的整数或日期时间列的大型表进行完整加载。 | 分区选项:动态范围分区。 分区列(可选):指定用于对数据进行分区的列。 如果未指定,将使用主键列。 分区上限和分区下限(可选) :指定是否要确定分区步幅。 这不适用于筛选表中的行,表中的所有行都将进行分区和复制。 如果未指定,则复制活动将自动检测值,这可能需要花费很长时间,具体取决于“最小值”和“最大值”。 建议提供上限和下限。 例如,如果分区列“ID”的值范围为 1 至 100,并且将此值的下限设置为 20、上限设置为 80,并行复制设置为 4,服务将按 4 个分区(分区的 ID 范围分别为 <=20、[21, 50]、[51, 80] 和 >=81)检索数据。 |
| 使用自定义查询从不包含物理分区但包含用于数据分区的整数或日期/日期时间列的表加载大量数据。 | 分区选项:动态范围分区。 查询: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>。分区列:指定用于对数据进行分区的列。 分区上限和分区下限(可选) :指定是否要确定分区步幅。 这不适用于筛选表中的行,查询结果中的所有行都将进行分区和复制。 如果未指定,复制活动会自动检测该值。 例如,如果分区列“ID”的值范围为 1 至 100,并且将此值的下限设置为 20、上限设置为 80,并行复制设置为 4,服务将按 4 个分区(分区的 ID 范围分别为 <=20、[21, 50]、[51, 80] 和 >=81)检索数据。 下面是针对不同场景的更多示例查询: • 查询整个表: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• 使用列选择和附加的 where 子句筛选器从表中查询: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• 使用子查询进行查询: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• 在子查询中使用分区查询: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
使用分区选项加载数据的最佳做法:
- 选择独特的列作为分区列(如主键或唯一键),以避免数据倾斜。
- 如果表具有内置分区,请使用名为“表的物理分区”分区选项来提升性能。
检查物理分区的示例查询
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
如果表具有物理分区,你可看到“HasPartition”为“是”,如下所示。

表摘要
有关 SQL Server 复制活动的摘要和详细信息,请参阅下表。
源信息
| 名称 | 描述 | 值 | 必选 | JSON 脚本属性 |
|---|---|---|---|---|
| 数据存储类型 | 你的数据存储类型。 | 外部 | 是 | / |
| Connection | 与源数据存储的连接。 | < 你的连接 > | 是 | 连接 |
| 连接类型 | 你的连接类型。 选择“SQL Server”。 | SQL Server | 是 | / |
| 使用查询 | 自定义 SQL 查询读取数据。 | • 表 • 查询 • 存储过程 |
否 | / |
| 表 | 源数据表。 | < 表的名称> | 否 | 架构 表 |
| 查询 | 自定义 SQL 查询读取数据。 | < 你的查询 > | 否 | sqlReaderQuery |
| 存储过程名称 | 此属性是从源表读取数据的存储过程的名称。 最后一个 SQL 语句必须是存储过程中的 SELECT 语句。 | <存储过程名称> | 否 | sqlReaderStoredProcedureName |
| 存储过程参数 | 这些参数用于存储过程。 允许的值为名称或值对。 参数的名称和大小写必须与存储过程参数的名称和大小写匹配。 | < 名称或值对 > | 否 | storedProcedureParameters |
| 查询超时 | 查询命令执行的超时值。 | timespan (默认值为 120 分钟) |
否 | queryTimeout |
| 隔离级别 | 指定 SQL 源的事务锁定行为。 | • 读取已提交的内容 • 读取未提交的内容 • 可重复读取 • 可序列化 • Snapshot |
否 | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead • 可序列化 • Snapshot |
| 分区选项 | 用于从 SQL Server 加载数据的数据分区选项。 | • 无(默认值) • 表的物理分区。 • 动态范围 |
否 | partitionOption: • 无(默认值) • PhysicalPartitionsOfTable • DynamicRange |
| 分区列名称 | 具有整数类型、日期类型或日期/时间类型(int、smallint、bigint、date、smalldatetime、datetime、datetime2 或 datetimeoffset)的源列的名称,范围分区将使用它进行并行复制。 如果未指定,系统会自动检测表的索引或主键并将其用作分区列。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?DfDynamicRangePartitionCondition。 |
< 分区列名称 > | 否 | partitionColumnName |
| 分区上限 | 分区范围拆分的分区列的最大值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 | < 分区上限 > | 否 | partitionUpperBound |
| 分区下限 | 分区范围拆分的分区列的最小值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 | < 分区下限 > | 否 | partitionLowerBound |
| 其他列 | 添加其他数据列以存储源文件的相对路径或静态值。 后者支持表达式。 | • 姓名 • 值 |
否 | additionalColumns: • 名称 • 值 |
目标信息
| 名称 | 描述 | 值 | 必选 | JSON 脚本属性 |
|---|---|---|---|---|
| 数据存储类型 | 你的数据存储类型。 | 外部 | 是 | / |
| Connection | 与目标数据存储的连接。 | < 你的连接 > | 是 | 连接 |
| 连接类型 | 你的连接类型。 选择“SQL Server”。 | SQL Server | 是 | / |
| 表选项 | 指定如果目标表不存在,是否根据源模式自动创建目标表。 | • 使用现有 • 自动创建表 |
否 | tableOption: • autoCreate |
| 表 | 目标数据表。 | <表的名称> | 是 | 架构 表 |
| 写入行为 | 复制活动的写入行为,以将数据加载到 SQL Server 数据库。 | • 插入 • 更新插入 • 存储过程 |
否 | writeBehavior: • 插入 • 更新插入 sqlWriterStoredProcedureName、sqlWriterTableType, storedProcedureTableTypeParameterName、storedProcedureParameters |
| 使用 TempDB | 是使用全局临时表还是物理表作为更新插入的临时表。 | 已选择(默认)或未选择 | 否 | useTempDB: true(默认)或 false |
| 选择用户 DB 架构 | 在使用了物理表的情况下,用于创建临时表的临时架构。 注意:用户需要具有创建和删除表的权限。 默认情况下,临时表将与目标表共享相同的架构。 如果未选择“使用 TempDB”,则适用。 | 已选择(默认)或未选择 | 否 | interimSchemaName |
| 键列 | 唯一行标识的列名称。 可使用单个键,也可使用一系列键。 如果未指定,将使用主键。 | < 键列> | 否 | keys |
| 存储过程名称 | 定义如何将源数据应用于目标表的存储过程的名称。 此存储过程由每个批处理调用。 若要执行仅运行一次且与源数据无关的操作(例如删除或截断),请使用“复制前脚本”属性。 | < 存储过程名称 > | 否 | sqlWriterStoredProcedureName |
| 表类型 | 要在存储过程中使用的表类型名称。 通过复制活动可以在具有此表类型的临时表中提供将移动的数据。 然后,存储过程代码可合并复制数据和现有数据。 | < 表类型名称 > | 否 | sqlWriterTableType |
| 表类型参数名称 | 存储过程中指定的表类型的参数名称。 | < 表类型的参数名称 > | 否 | storedProcedureTableTypeParameterName |
| Parameters | 存储过程的参数。 允许的值为名称和值对。 参数的名称和大小写必须与存储过程参数的名称和大小写匹配。 | < 名称和值对 > | 否 | storedProcedureParameters |
| 大容量插入表锁 | 使用此设置可提高在不包含多个客户端索引的表上执行大容量插入操作期间的复制性能。 | “是”或“否”(默认值) | 否 | sqlWriterUseTableLock: true 或 false(默认) |
| 复制前脚本 | 指定每次运行时,复制活动将数据写入到目标表之前要执行的脚本。 此属性可用于清理预先加载的数据。 | < 复制前脚本 > (string) |
否 | preCopyScript |
| 写入批处理超时 | 超时前等待批插入操作完成的时间。 | timespan (默认值为“02:00:00”) |
否 | writeBatchTimeout |
| 写入批大小 | 每批要插入到 SQL 表中的行数。 默认情况下,该服务根据行大小动态确定适当的批大小。 | < 行数 > (整数) |
否 | writeBatchSize |
| 最大并发连接数 | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | < 并发连接的上限 > (整数) |
否 | maxConcurrentConnections |