Microsoft Fabric 数据工厂中的 ORC 格式
本文介绍了如何在 Microsoft Fabric 数据工厂的数据管道中配置 ORC 格式。
支持的功能
以下活动和连接器支持使用 ORC 格式作为源和目标。
复制活动中的 ORC 格式
若要配置 ORC 格式,请在数据管道复制活动的源或目标中选择连接,然后在“文件格式”下拉列表中选择“ORC”。 选择“设置”以进一步配置此格式。
ORC 格式作为源
在“文件格式”部分选择“设置”后,弹出的“文件格式设置”对话框中将显示以下属性。
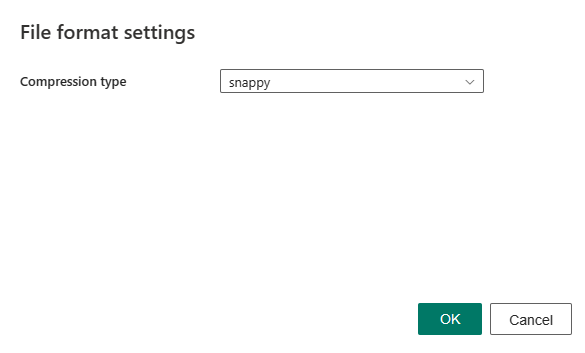
- 压缩类型:在下拉列表中选择用于读取 ORC 文件的压缩编解码器。 可以选择“无”、“zlib”或“snappy”。
ORC 格式作为目标
选择“设置”后,弹出的“文件格式设置”对话框中将显示以下属性。
- 压缩类型:在下拉列表中选择用于写入 ORC 文件的压缩编解码器。 可以选择“无”、“zlib”或“snappy”。
在“目标”选项卡中的“高级”设置下,将显示以下与 ORC 格式相关的属性。
- 每个文件的最大行数:在将数据写入到文件夹时,可选择写入多个文件,并指定每个文件的最大行数。 指定要为每个文件写入的最大行数。
- 文件名前缀:配置“每个文件的最大行数”时适用。 在将数据写入多个文件时,指定文件名前缀,生成的模式为
<fileNamePrefix>_00000.<fileExtension>。 如果未指定,将自动生成文件名前缀。 如果源是基于文件的存储或已启用分区选项的数据存储,则此属性不适用。
表摘要
以 ORC 作为源
使用 ORC 格式时,复制活动“源”部分将支持以下属性。
| 名称 | 描述 | 值 | 必选 | JSON 脚本属性 |
|---|---|---|---|---|
| 文件格式 | 要使用的文件格式。 | ORC | 是 | 类型(在 datasetSettings 下):Orc |
| 压缩类型 | 用来读取 ORC 文件的压缩编解码器。 | 无 zlib snappy |
否 | orcCompressionCodec: 无 zlib snappy |
ORC 作为目标
使用 ORC 格式时,复制活动“目标”部分支持以下属性。
| 名称 | 描述 | 值 | 必选 | JSON 脚本属性 |
|---|---|---|---|---|
| 文件格式 | 要使用的文件格式。 | ORC | 是 | 类型(在 datasetSettings 下):Orc |
| 压缩类型 | 用于写入 ORC 文件的压缩编解码器。 | 无 zlib snappy |
否 | orcCompressionCodec: 无 zlib snappy |
| 每个文件的最大行数 | 在将数据写入到文件夹时,可选择写入多个文件,并指定每个文件的最大行数。 指定要为每个文件写入的最大行数。 | <每个文件的最大行数> | 否 | maxRowsPerFile |
| 文件名前缀 | 配置“每个文件的最大行数”时适用。 在将数据写入多个文件时,指定文件名前缀,生成的模式为 <fileNamePrefix>_00000.<fileExtension>。 如果未指定,将自动生成文件名前缀。 如果源是基于文件的存储或已启用分区选项的数据存储,则此属性不适用。 |
<文件名前缀> | 否 | fileNamePrefix |
相关内容
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈