本教程需要 15 分钟,介绍如何使用 Dataflow Gen2 以增量方式将数据聚集到湖屋中。
以增量方式在数据目标中聚集数据需要一种技术,以便仅将新的或更新的数据加载到数据目标中。 此技术可以通过使用查询基于数据目标筛选数据来完成。 本教程介绍如何创建数据流以将数据从 OData 源加载到湖屋中,以及如何向数据流添加查询以基于数据目标筛选数据。
本教程中的大致步骤如下:
- 创建数据流以将数据从 OData 源加载到湖屋中。
- 向数据流添加查询,以基于数据目标筛选数据。
- (可选)使用笔记本和管道重新加载数据。
先决条件
必须具有已启用 Microsoft Fabric 的工作区。 如果还没有此类工作区,请参阅创建工作区。 此外,本教程假定你在 Dataflow Gen2 中使用关系图视图。 若要检查你是否使用图表视图,请在顶部功能区中转到“视图”,并确保选择“图表视图”。
创建数据流以将数据从 OData 源加载到湖屋中
在本部分,你需要创建一个数据流,以将数据从 OData 源加载到湖屋中。
在工作区中创建新的湖屋。
在工作区中创建新的数据流 Gen2。
将新源添加到数据流。 选择 OData 源并输入以下 URL:
https://services.OData.org/V4/Northwind/Northwind.svc
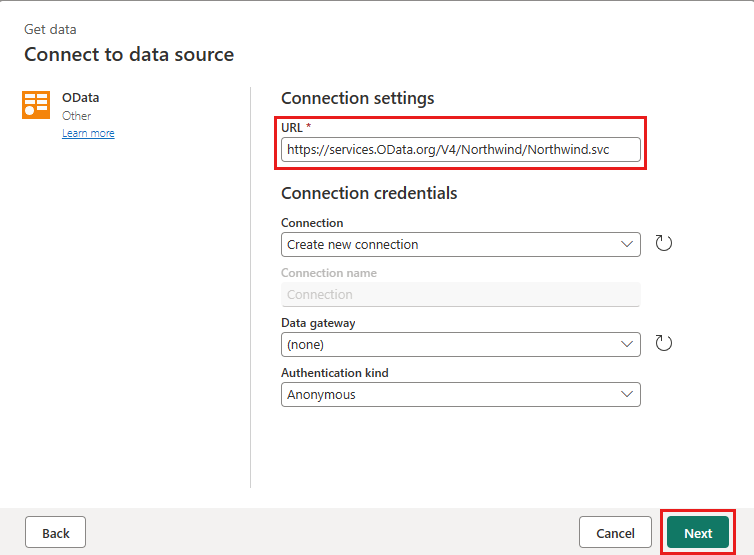
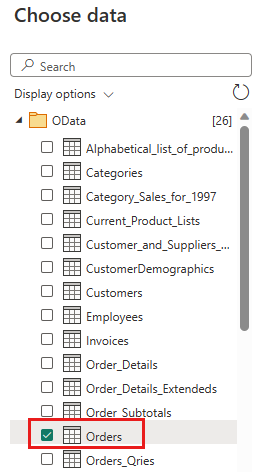
选择订单表,然后选择“下一步”。
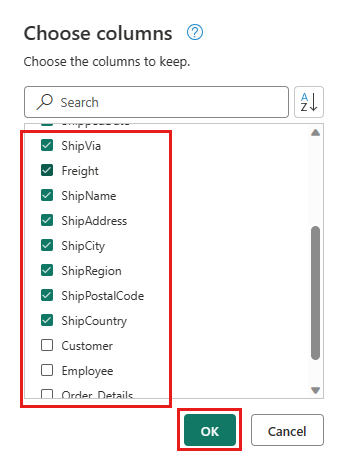
选择要保留的以下列:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
将
OrderDate、RequiredDate和ShippedDate的数据类型更改为datetime。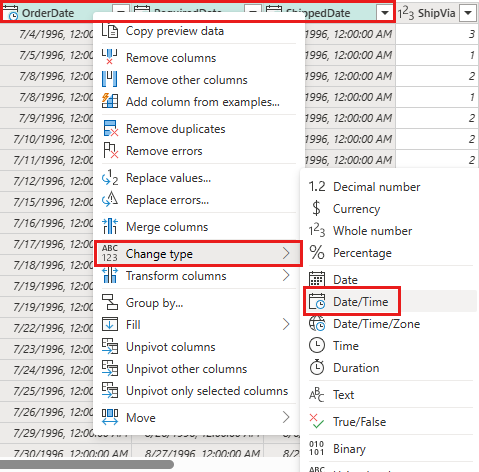
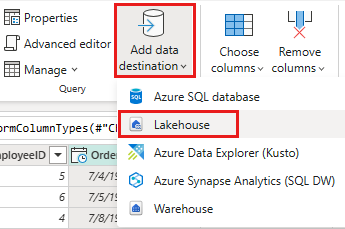
使用以下设置将数据目标设置为湖屋:
- 数据目标:
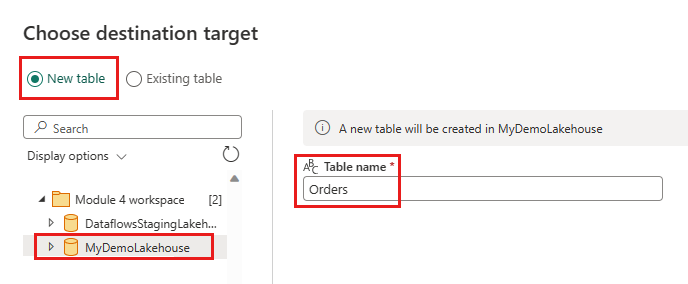
Lakehouse - 湖屋:选择在步骤 1 中创建的湖屋。
- 新表名:
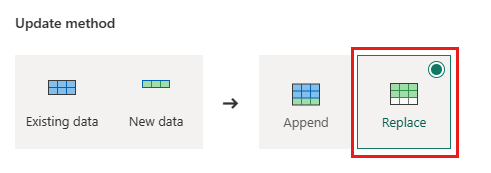
Orders - 更新方法:
Replace
- 数据目标:
选择“下一步”并发布数据流。



你已创建用于将数据从 OData 源加载到湖屋中的数据流。 此数据流在下一部分中用于向数据流添加查询,以基于数据目标筛选数据。 之后,可以使用该数据流通过笔记本和管道重新加载数据。
向数据流添加查询,以基于数据目标筛选数据
本部分将向数据流添加查询,以基于目标湖屋中的数据筛选数据。 该查询在数据流刷新开始时获取湖屋中的最大 OrderID,并使用最大 OrderId 以仅从源中获取具有较高 OrderId 的订单附加到数据目标。 这假设订单根据 OrderID 按升序添加到源中。 如果不是这种情况,可以使用其他列来筛选数据。 例如,可以使用 OrderDate 列来筛选数据。
注意
OData 筛选器是从数据源接收数据后在 Fabric 中应用的,但是,对于 SQL Server 这样的数据库源,筛选器是在提交到后端数据源的查询中应用的,并且只有经过筛选的行才会返回到服务。
刷新数据流后,重新打开在上一部分创建的数据流。
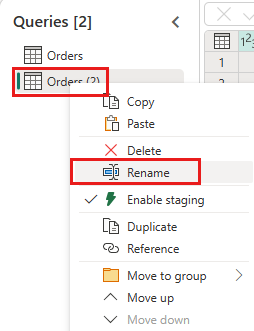
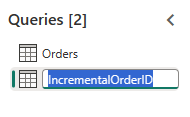
创建名为
IncrementalOrderID的新查询,并从在上一部分创建的湖屋的订单表中获取数据。
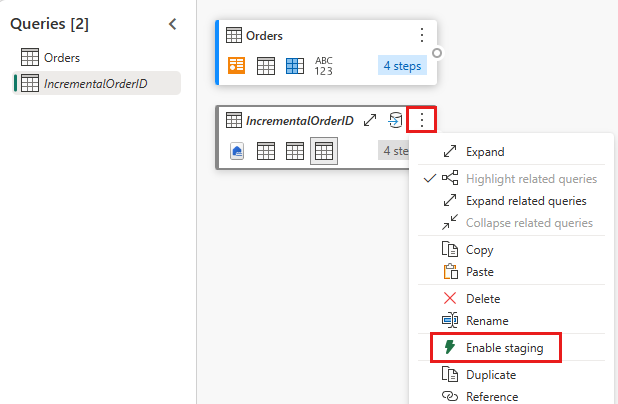
禁用此查询的暂存。
在数据预览中,右键点击
OrderID列并选择“向下钻取”。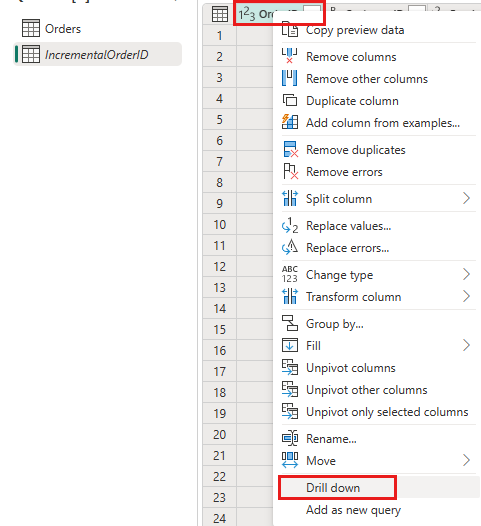
在功能区中,选择“列出工具” ->“统计信息”->“最大值”。
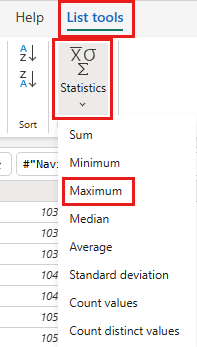
现在,你有一个返回湖屋中最大 OrderID 的查询。 此查询用于筛选 OData 源中的数据。 下一部分将向数据流添加一个查询,以根据湖屋中的最大 OrderID 筛选来自 OData 源的数据。
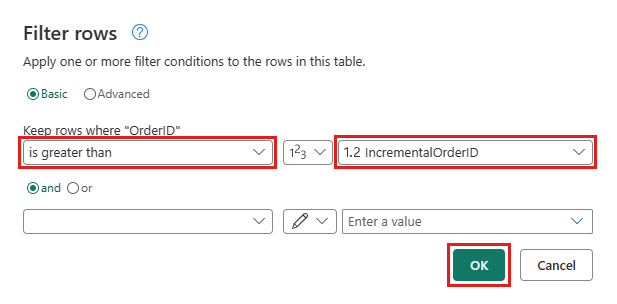
返回到订单查询并添加一个新步骤来筛选数据。 使用以下设置:
- 列:
OrderID - 运算:
Greater than - 值:参数
IncrementalOrderID

- 列:
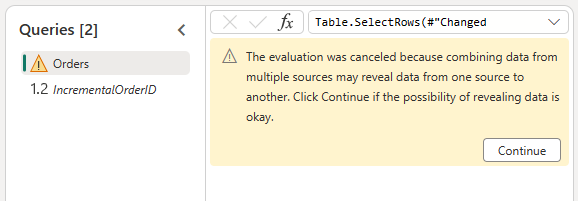
通过确认以下对话框,允许合并来自 OData 源和 Lakehouse 的数据:
更新数据目标以使用以下设置:
- 更新方法:
Append

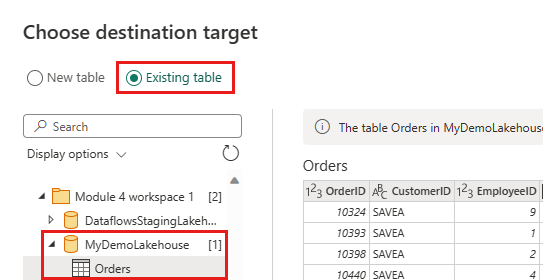
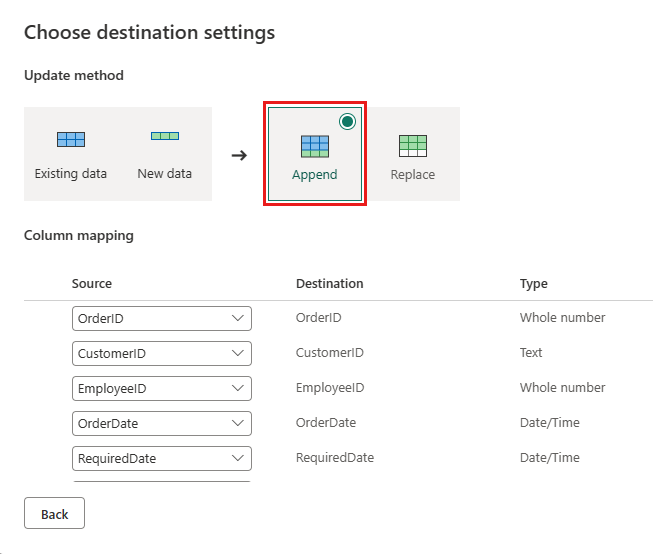
- 更新方法:
发布数据流。
数据流现在包含一个查询,该查询基于湖屋中的最大 OrderID 筛选 OData 源中的数据。 这意味着只会将新的或更新的数据加载到湖屋中。 下一部分将使用该数据流通过笔记本和管道重新加载数据。
(可选)使用笔记本和管道重新加载数据
(可选)可以使用笔记本和管道重新加载特定数据。 使用笔记本中的自定义 python 代码,可以从湖屋中删除旧数据。 然后,通过创建一个管道,首先在其中运行笔记本并按顺序运行数据流,可将 OData 源中的数据重新加载到湖屋中。 笔记本支持多种语言,但本教程使用 PySpark。 Pyspark 是适用于 Spark 的 Python API,在本教程中用于运行 Spark SQL 查询。
在工作区中创建一个新笔记本。
将以下 PySpark 代码添加到笔记本中:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))运行笔记本以验证数据是否已从湖屋中删除。
在工作区中创建新管道。
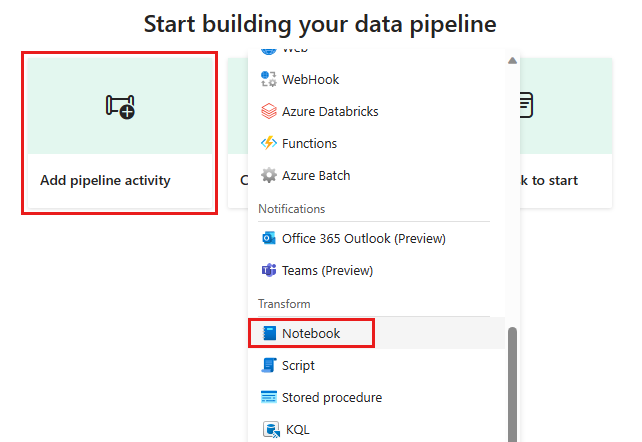
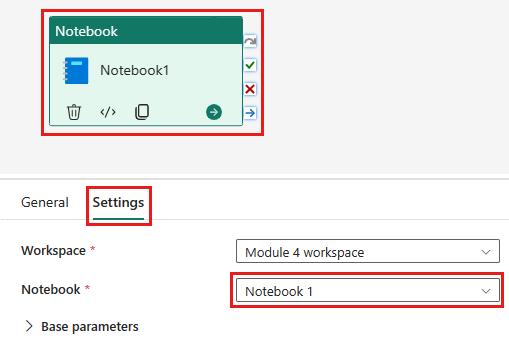
将新的笔记本活动添加到管道,并选择在上一步中创建的笔记本。
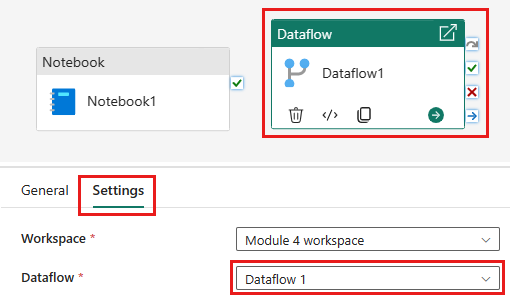
将新的数据流活动添加到管道,并选择在上一部分创建的数据流。
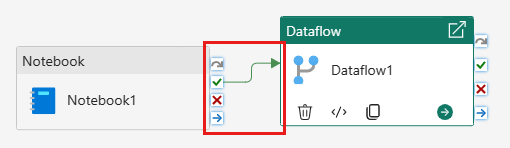
使用成功触发器将笔记本活动链接到数据流活动。
保存并运行管道。


现在,你有一个用于从湖屋中删除旧数据,并将 OData 源中的数据重新加载到湖屋中的管道。 通过此设置,可以定期将数据从 OData 源重新加载到 lakehouse 中。