适用于:Microsoft Fabric 中的✅ 仓库
本文重点介绍 Fabric 数据仓库体系结构中的功能和创新,这些功能和创新可提升其性能、可伸缩性和成本效益。
Fabric 数据仓库在融合数据平台中的面向未来的架构上运行。 使用开放式 Delta 存储格式和 OneLake 集成,Fabric 数据仓库中的数据可供分析。
体系结构概述

Fabric 数据仓库是专为大规模分析而构建的,包含以下构建基块:
| 构建基块 | 说明 |
|---|---|
| 统一查询优化器 | 为分布式云环境生成最佳执行计划,而不考虑用户创作的 SQL 查询的质量。 |
| 分布式查询处理 | 通过快速自动缩放云基础结构支持大规模并行查询执行,从而立即为查询提供所需的计算资源。 单独的 SELECT 和 DML 工作负载分别使用不同的池,以实现高效且隔离的执行。 |
| 查询执行引擎 | 基于 SQL 的引擎,用于对大量数据执行分析查询,具有快速性能和高并发性。 |
| 元数据和事务管理 | 元数据驻留在前端、后端以及本地 SSD 缓存和远程 OneLake 存储中。 支持 并发事务并确保 ACID 符合性。 |
| OneLake 中的存储 | 使用 开放式 Delta 表格式(采用具有安全开放存储的 Lakehouse 模型)实现的日志结构化表。 |
| Fabric 平台 | Fabric 平台提供 统一的身份验证和安全模型、 监视和 审核。 Fabric 数据仓库可自动提供给其他 Fabric 平台服务以满足业务需求,包括 Power BI、数据工厂中的数据管道、实时智能等。 |
统一查询优化器引擎
Fabric 数据仓库中的统一查询优化器是决定运行 SQL 查询的最智能方法的引擎。
提交查询时,统一查询优化器将查看执行查询的可能方法:如何联接表、移动数据的位置以及如何使用 CPU、内存和网络等资源。 统一查询优化器不只是选择第一个选项,它通过在这些因素和可用元数据和统计信息中评估成本,在允许的时间内选择最佳计划。
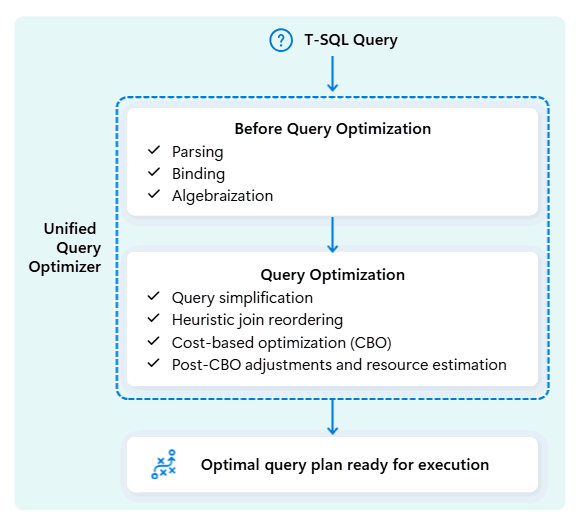
优化查询的执行计划时,统一查询优化器会一次性考虑所有内容:查询的形状、表的数据分布以及在本地移动数据与处理的成本。 统一查询优化器可以做出智能权衡,例如决定是否广播小型表比洗牌大表便宜。 这意味着更少的不必要的数据混排,更好地使用计算,以及更快的性能,即使对于复杂或编写不当的 T-SQL 查询也是如此。
一致的性能不需要开发人员花时间进行手动 T-SQL 查询优化。 例如,无需手动确定查询中的最佳 JOIN 顺序。 如果 SQL 首先列出大型表和较小的高度选择性数据表,优化器可以自动切换其位置以提高性能。 它将使用较小的表作为匹配行的起点(“构建”端),并使用较大的表作为需要搜索的对象(检查匹配项的“探测”端)。 此方法可最大程度地减少内存使用率、减少数据移动并提高并行度,同时仍提供准确的结果。
随着工作负荷的发展,统一查询优化器不断学习过去的查询执行,优化其优化算法以提供最佳性能。 无论复杂程度如何,用户都可以自动从快速查询执行中受益,而无需进行干预。
分布式查询处理引擎
在 Fabric 数据仓库中,分布式查询处理引擎将计算资源分配给查询计划中的任务。 分布式查询处理引擎可以跨计算节点计划任务,以便每个节点都运行查询计划的一部分,从而实现并行执行以提高性能。 大型数据集上的复杂报表可以从分布式查询处理中受益。
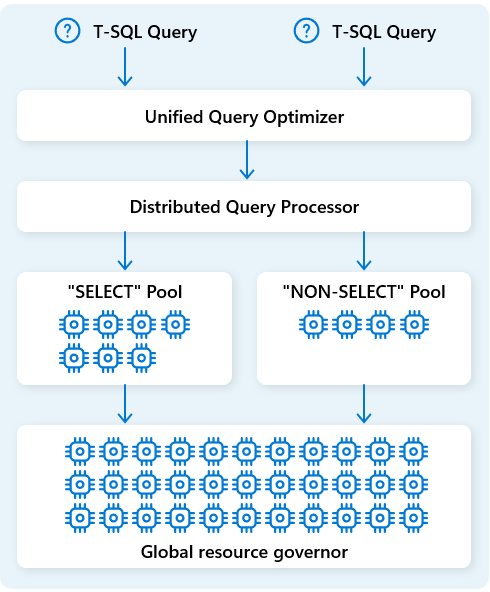
为了进一步优化资源,分布式查询处理引擎将计算资源分为两个池:用于 SELECT 查询和数据引入任务(NON-SELECT 查询)。 每个工作负荷都根据需要接收专用资源。 这意味着,例如,你的夜间 ETL 作业不会导致上午的仪表板延迟。
借助云中的快速节点预配,分布式查询处理引擎可自动纵向扩展或缩减计算资源,以响应查询量、数据大小和查询复杂性的变化。 Fabric 数据仓库对多 PB 规模的小型数据集或数据具有并行处理功能。
查询执行引擎
查询执行引擎是一个进程,用于运行分配给各个计算节点的分布式执行计划的一部分。 查询执行引擎基于 SQL Server 和 Azure SQL 数据库用于使用 批处理模式 执行和 列式 数据格式的相同引擎,以便以最佳成本高效分析大数据。
查询执行引擎直接从 Fabric OneLake 中存储的 Delta Parquet 文件读取数据,并利用多个缓存层(内存和 SSD)加速查询性能,并确保查询以最佳速度执行。 查询执行引擎处理内存中的数据,并在必要时从 SSD 缓存或 OneLake 存储检索其他数据。
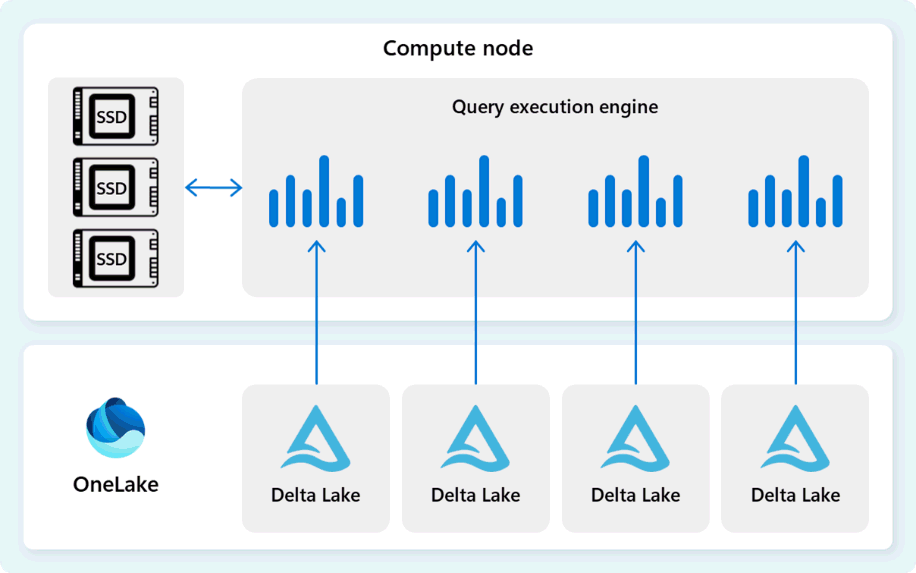
在处理数据时,查询执行引擎执行列和行组消除以跳过与查询无关的段。 此优化可减少从文件和内存缓存扫描的数据量,从而最大程度地减少资源使用率并提高整体执行时间。
查询执行引擎擅长筛选和聚合数十亿行,支持新式数据仓库解决方案中使用的通用数据分析模式。 批处理模式执行利用现代 CPU 并行处理多行的能力,大幅减少开销,使查询运行速度比传统的逐行执行快数百倍。
元数据和事务管理
仓库引擎使用元数据来描述表架构、文件组织、版本历史记录和事务状态。 此元数据允许仓库引擎有效地管理和查询数据。 Fabric 数据仓库提供可靠且全面的元数据和事务管理体系结构,扩展 OLTP 事务管理器以协调高度并发的元数据作并确保 ACID 符合性。
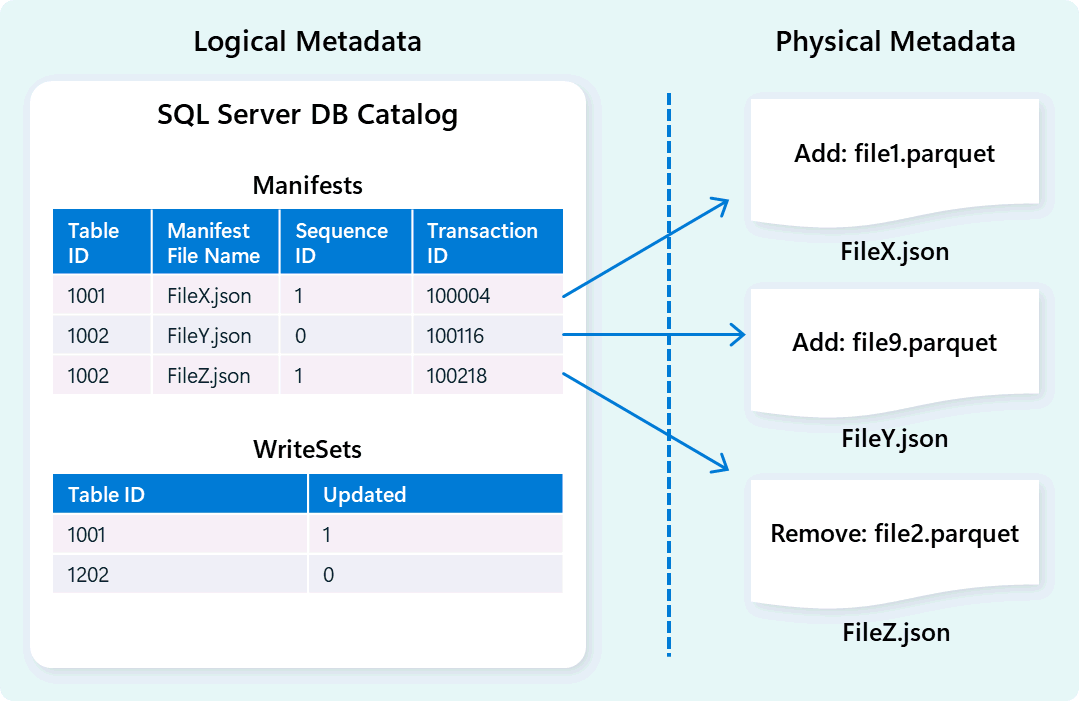
此设计可实现事务状态的快速可靠导航,支持具有高并发性的工作负荷,同时确保一致性。
存储和数据引入
Fabric 数据仓库使用具有开源 Delta 格式的 Lakehouse 体系结构,实现可缩放、安全、高性能的存储。 Delta 表格式支持数据版本控制,通过 时间旅行 和 零复制克隆 即时访问历史快照,以实现安全测试和回滚操作。 用户数据存储在 OneLake 中,允许所有 Fabric 引擎在不冗余的情况下有效地访问共享数据。
基于此基础,Fabric 数据仓库旨在提供最佳的数据引入性能,重点是简单性和灵活性。 该引擎通过 自动数据压缩有效地管理表数据存储,该压缩功能将后台的碎片文件合并,以减少不必要的数据扫描。 其智能数据分布方法将数据划分为微分区单元格,以提高并行处理并提高查询结果。 这些功能可以自主运行,无需手动调整。