使用快捷转换将结构化文件转换为可查询的 Delta 表。 如果源数据已采用 CSV、Parquet 或 JSON 等表格格式,则文件转换会自动复制该数据并将其转换为 Delta Lake 格式,以便可以使用 SQL、Spark 或 Power BI 对其进行查询,而无需生成 ETL pipelines。
有关需要 AI 处理的非结构化文本文件(如摘要、翻译或情绪分析),请参阅快捷方式转换(AI 提供支持)。
快捷转换始终与源数据 保持同步 。 Fabric Spark 计算 执行转换,并将 OneLake 快捷方式引用的数据复制到托管 Delta 表中。 借助自动架构处理、深度平展功能和对多种压缩格式的支持,快捷转换消除了生成和维护 ETL 管道的复杂性。
注释
快捷转换目前以 公共预览版提供 ,可能会更改。
为何使用快捷转换?
- 自动转换 – Fabric 在无需进行手动管道编排的情况下将源文件复制并转换为 Delta 格式。
- 频繁同步 – Fabric 每两分钟轮询一次快捷方式,并同步更改。
- Delta Lake 输出 – 生成的表与任何 Apache Spark 引擎兼容。
- 继承的治理 – 快捷方式继承 OneLake 世系、权限和Microsoft Purview 策略。
先决条件
| 要求 | 详细信息 |
|---|---|
| Microsoft Fabric 产品型号 | 支持 Lakehouse 工作负载的容量或体验版。 |
| 源数据 | 包含同质 CSV、Parquet 或 JSON 文件的文件夹。 |
| 工作区角色 | 参与者 或更高级别。 |
支持的源、格式和目标
OneLake 支持的所有数据源都得到支持。
| 源文件格式 | 目的地 | 支持的扩展 | 支持的压缩类型 | 备注 |
|---|---|---|---|---|
| CSV (UTF-8、UTF-16) | Lakehouse / Tables 文件夹中的 Delta Lake 表 | .csv、.txt(分隔符)、.tsv(制表符分隔)、.psv(管道分隔) | .csv.gz,.csv.bz2 | 不支持 .csv.zip 和 .csv.snappy。 |
| Parquet | Lakehouse / Tables 文件夹中的 Delta Lake 表 | .parquet | .parquet.snappy、.parquet.gzip、.parquet.lz4、.parquet.brotli、.parquet.zstd | |
| JSON | Lakehouse / Tables 文件夹中的 Delta Lake 表 | .json、.jsonl、.ndjson | .json.gz、.json.bz2、.jsonl.gz、.ndjson.gz、.jsonl.bz2、.ndjson.bz2 | 不支持 .json.zip 和 .json.snappy。 |
设置快捷转换
在 Lakehouse 中,在“表”部分选择“新建表快捷方式”,即快捷方式转换(预览版)。 选择源(例如,Azure Data Lake、Azure Blob Storage、Dataverse、Amazon S3、GCP、SharePoint、OneDrive 等)。
选择文件、配置转换和创建快捷方式 – 浏览到指向包含 CSV 文件的文件夹的现有 OneLake 快捷方式、配置参数并启动创建。
- CSV 文件中的分隔符 – 选择用于分隔列的字符(逗号、分号、管道、制表符、和号、空格)。
- 第一行作为标题 - 指示第一行是否包含列名。
- 表快捷方式名称 – 提供友好名称;Fabric 在 /Tables 下创建它。
在 “管理快捷方式监控中心”中通过跟踪刷新和查看日志,以确保透明性。

Fabric Spark 计算将数据复制到 Delta 表,并在 “管理”快捷 窗格中显示进度。 Lakehouse 项目中提供了快捷转换功能。 它们在 Lakehouse /Tables 文件夹中创建 Delta Lake 表。
同步的工作原理
初始加载后,Fabric Spark 计算:
- 每两分钟轮询一次快捷目标。
- 检测 新的或修改的文件 ,并相应地追加或覆盖行。
- 检测 已删除的文件 并删除相应的行。
监视并排查
快捷转换包括监视和错误处理,以帮助跟踪引入状态和诊断问题。
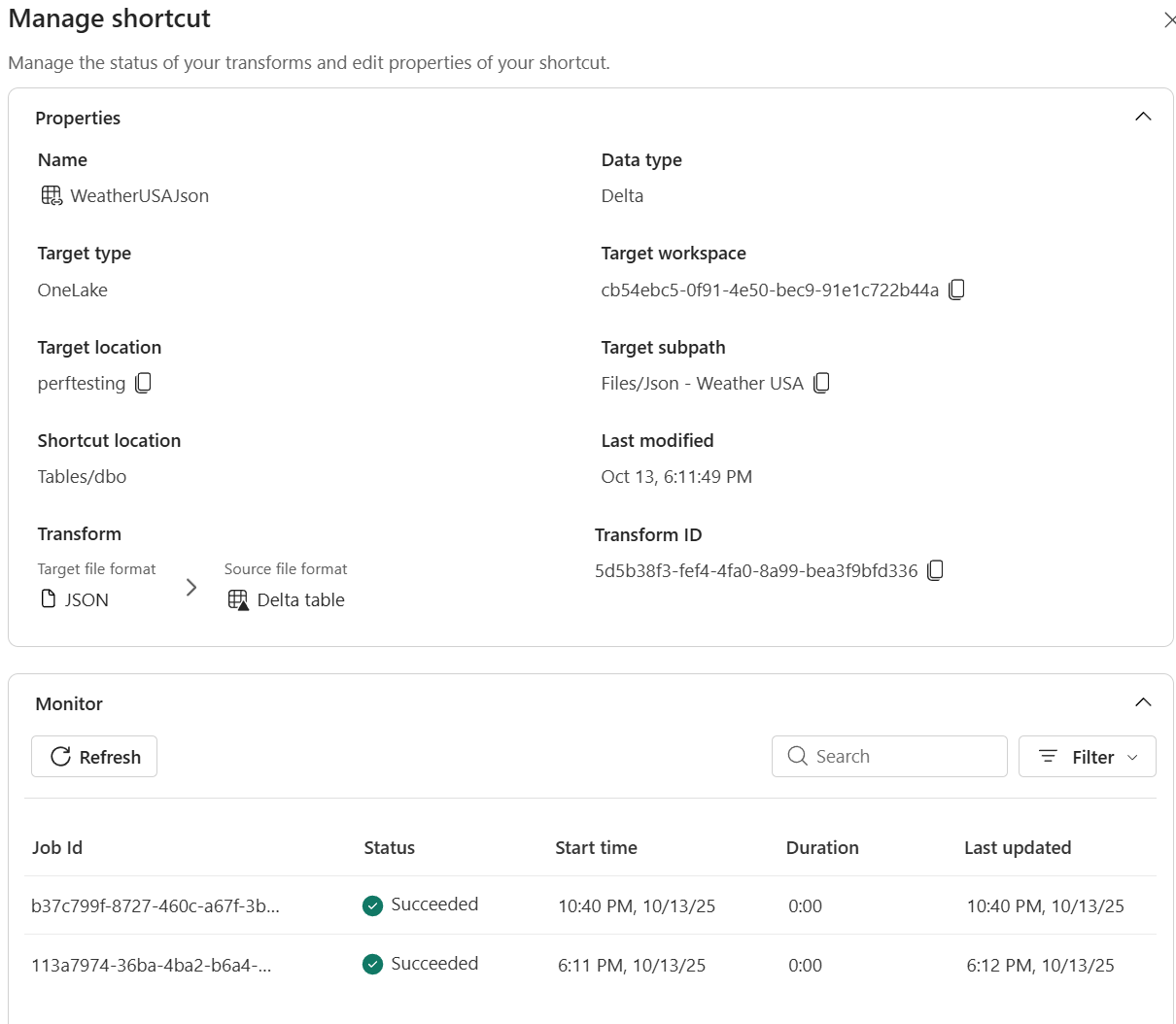
打开 Lakehouse 并右键单击支撑您转换的快捷方式。
选择“ 管理快捷方式”。
在详细信息窗格中,可以查看:
- 状态 – 上次扫描结果和当前同步状态。
- 刷新历史记录 – 按时间顺序排列的同步操作列表,其中包括行计数和任何错误详细信息。
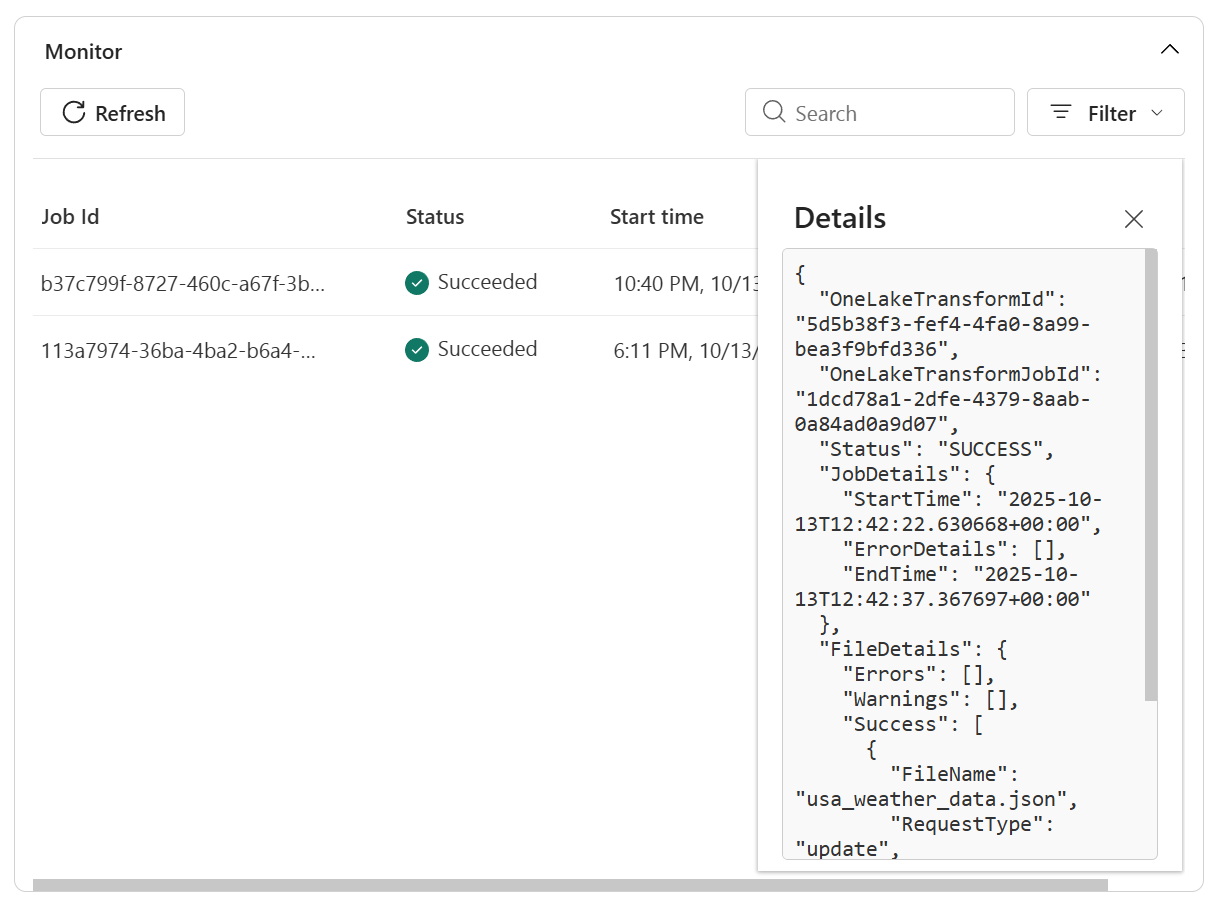
在日志中查看更多详细信息,以便进行故障排除
局限性
快捷方式转换的当前限制:
-
源格式: 仅支持 CSV、JSON 和 Parquet 文件。
- CSV 不支持的数据类型: 混合数据类型列、Timestamp_Nanos、复杂逻辑类型 - MAP/LIST/STRUCT、原始二进制
- Parquet 不支持的数据类型: Timestamp_nanos、具有 INT32/INT64 的十进制数、INT96、未分配的整数类型 - UINT_8/UINT_16/UINT_64、复杂逻辑类型 - MAP/LIST/STRUCT
- JSON 不支持的数据类型: 数组中的混合数据类型、JSON 内的原始二进制数据块、Timestamp_Nanos
- 文件架构一致性: 文件必须共享相同的架构。
- 工作区可用性: 仅在 Lakehouse 项(而不是数据仓库或 KQL 数据库)中可用。
- 写入操作: 转换经过读取优化, 不支持在转换目标表上直接使用MERGE INTO或DELETE语句。
- 在 JSON 中平展数组数据类型: 数组数据类型在 Delta 表中保留,并且可以通过 Spark SQL 和 Pyspark 访问这些数据。 对于进一步的转换,可以使用 Fabric Materialized Lake Views 来处理银层。
- 在 JSON 中,嵌套结构被平展至五层深度。 更深入的嵌套需要预处理。
使用 Fabric 路线图 和 Fabric 更新博客 了解新功能和版本。
清理
若要停止同步,请从 Lakehouse Explorer 中删除快捷方式转换。
删除转换不会删除基础文件。