敏感信息 预生成模型 分析和检测文档中的关键信息,然后选择性地提取信息。 该模型识别各种格式的文档,并 检测敏感信息,例如个人和财务标识号、物理地址和电子邮件地址以及电话号码。
设置敏感信息模型
若要创建和配置敏感信息模型,请执行以下步骤:
按照 在 Syntex 中创建模型 中的说明创建敏感信息模型。 然后继续执行以下步骤以完成模型。
注意
创建敏感信息模型时,你会注意到,与其他模型不同,你没有用于选择内容类型或应用敏感度或保留标签的选项。 如果需要关联内容类型,则需要创建其他模型类型。 将来的版本中将提供应用安全标签的功能。
在 “模型 ”页上的 “添加要检测的实体 ”部分中,选择“ 添加实体”。
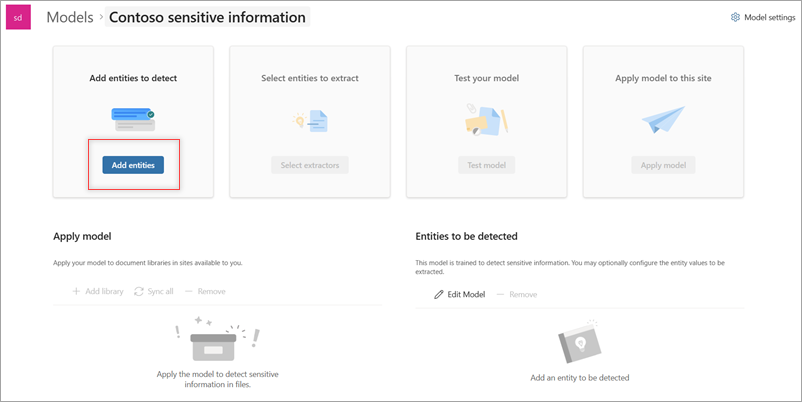
在 “配置检测 ”页上:
选择要用于此模型的语言。 每个模型只能选择一种语言。
从支持的实体列表中,选择要检测的一个或多个敏感信息实体,然后选择“ 下一步”。
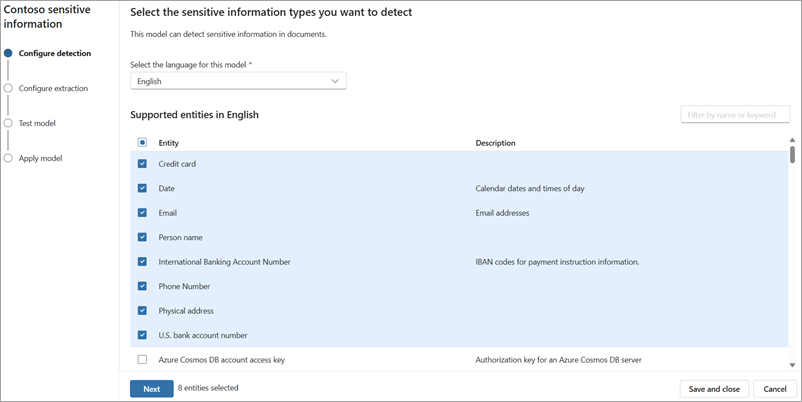
在 “配置提取 ”页上,可以看到选择检测的敏感信息实体的列表。 选择要提取到列中的实体,然后选择“ 下一步”。
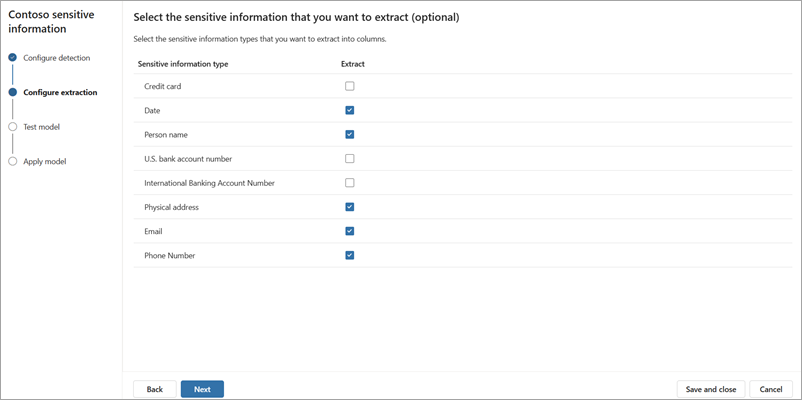
在“ 测试模型 ”页上,测试模型以确保它检测并提取所需的实体。 选择“ +添加文件 ”以选择示例文件以测试模型。
注意
此模型不会检测或提取加密文件的信息。
在 “应用模型 ”页上,选择“ +添加库”,选择要应用此模型的库,然后选择“ 添加”。
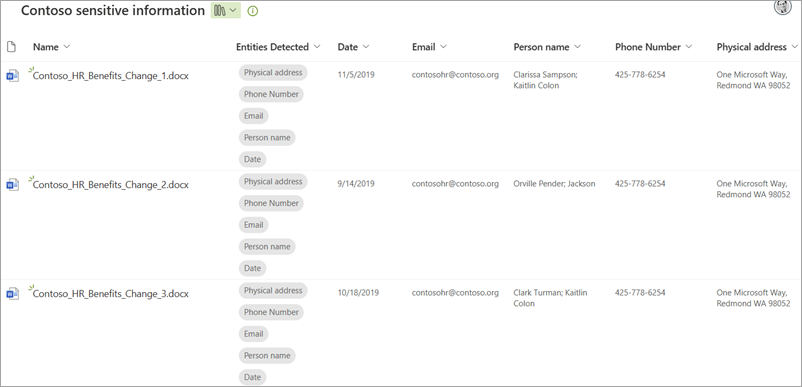
在文档库中,检测到的实体显示在“ 检测到的实体” 列中,选择提取的实体显示在各自的列中。
有关文件类型、语言、光学字符识别以及此预生成模型的其他注意事项的信息,请参阅 SharePoint 中预生成文档处理的要求和限制。