提示 API 是一种实验性 Web API,允许你从网站或浏览器扩展的 JavaScript 代码中提示 (SLM) ,该模型内置于 Microsoft Edge 中。 使用提示 API 生成和分析文本或基于用户输入创建应用程序逻辑,并发现将提示工程功能集成到 Web 应用程序中的创新方法。
详细内容:
- 提示 API 的可用性
- 提示 API 的替代项和优势
- 内置于 Microsoft Edge 中的小型语言模型
- Phi-4-mini 模型
- Aion-1.0-指令模型
- 启用提示 API
- 查看工作示例
- 使用提示 API
- 发送反馈
- 另请参阅
提示 API 的可用性
从版本 138.0.3309.2 开始,Microsoft Edge Canary 和 Edge 开发通道中提供了提示 API 作为开发人员预览版。
提示 API 旨在帮助发现用例并了解内置 SLM 的挑战。 此 API 预计将由其他实验性 API 成功,用于特定 AI 支持的任务,例如编写帮助和文本翻译。 若要详细了解这些其他 API,请参阅:
提示 API 的替代项和优势
若要在网站和浏览器扩展中利用 AI 功能,还可以使用以下方法:
将网络请求发送到基于云的 AI 服务,例如Azure AI 解决方案。
使用 Web 神经网络 (WebNN) API 或 ONNX Runtime for Web 运行本地 AI 模型。
提示 API 使用在同一设备上运行的 SLM,该设备使用模型的输入和输出 (即本地) 。 与基于云的解决方案相比,这具有以下优势:
降低成本: 使用云 AI 服务不产生任何费用。
网络独立性: 除了初始模型下载,提示模型时没有网络延迟,也可以在设备脱机时使用。
改进的隐私: 模型的数据输入永远不会离开设备,也不会收集这些数据来训练 AI 模型。
提示 API 使用由 Microsoft Edge 提供并内置于浏览器中的模型,该模型与自定义本地解决方案(例如基于 WebGPU、WebNN 或 WebAssembly 的解决方案)具有其他优势:
共享一次性成本: 首次调用 API 并在浏览器中运行的所有网站之间共享 API 时,将下载浏览器提供的模型,从而降低用户和开发人员的网络成本。
简化 Web 开发人员的用法: 内置模型可以使用简单的 Web API 来运行,不需要 AI/ML 专业知识或使用第三方框架。
内置于 Microsoft Edge 中的小型语言模型
在 Microsoft Edge Canary 和 Dev 通道中,从版本 138.0.3309.2 开始,提示 API 使用内置于 Microsoft Edge 中的 Phi-4-mini 模型。
从版本 150.0.4070 开始,提示 API 还可用于预发布 Aion-1.0-指令模型,该模型也内置于 Microsoft Edge 中。 Aion-1.0-指令是一种比 Phi-4-mini 更小、更快、更高效的模型,通过 CPU 推理在功能较差的 GPU 或没有 GPU 的设备上受支持。 如果设备的性能等级不足以支持 Phi-4-mini,则可以测试预发行版 Aion-1.0-指令模型。
若要了解有关这两个模型以及如何启用 Aion-1.0-指令的详细信息,请阅读以下部分。
Phi-4-mini 模型
提示 API 允许提示 Phi-4-mini,它内置于 Microsoft Edge 中。 Phi-4-mini 是一种功能强大的小语言模型,擅长于基于文本的任务。 若要了解有关 Phi-4-mini 及其功能的详细信息,请参阅 microsoft/Phi-4-mini-指令中的模型卡。
免责声明
与其他语言模型一样,Phi 系列模型的行为方式可能不公平、不可靠或冒犯性。 若要详细了解模型的 AI 注意事项,请参阅 负责任的 AI 注意事项。
硬件要求
提示 API 开发人员预览版适用于具有硬件功能的设备,这些设备可生成具有可预测的质量和延迟的 SLM 输出。 提示 API 当前仅限于:
操作系统:Windows 10 或 11 以及 macOS 13.3 或更高版本。
存储: 包含 Edge 配置文件的卷上至少有 20 GB 可用。 如果可用存储空间低于 10 GB,则将删除该模型,以确保其他浏览器功能有足够的空间正常运行。
GPU: 5.5 GB 或更多 VRAM。
网络: 无限制的数据计划或非计量连接。 如果使用按流量计费的连接,则不会下载模型。
若要检查设备是否支持提示 API 开发人员预览版,请参阅下面的启用提示 API 并检查设备性能类。
由于提示 API 的实验性质,你可能会发现特定硬件配置存在问题。 如果发现特定硬件配置存在问题,请在 MSEdgeExplainers 存储库 中打开新问题 来提供反馈。
Phi-4-mini 模型的可用性
网站首次调用需要设备内模型的 API 时,需要首次下载 Phi-4-mini 模型。 创建新的提示 API 会话时,可以使用监视器选项监视 Phi-4-mini 模型的下载。 若要了解详细信息,请参阅下面的 监视模型下载进度。
Aion-1.0-指令模型
在 Microsoft Edge Canary 或 Edge Dev 中,从版本 150.0.4070 开始,提示 API 还可用于预发行版 Aion-1.0-指令模型,该模型内置于 Microsoft Edge 中。
与 Phi-4-mini 相比,这种 Aion-1.0-指令模型更小、更快、更高效,并且通过 CPU 推理在功能较差的 GPU 或无 GPU 的设备上受支持。
Aion-1.0-指令预计将在 2026 年 7 月作为开放源代码模型提供。
为提示 API 启用 Aion-1.0-指令
默认情况下,提示 API 使用 Phi-4-mini 模型。 若要在 Microsoft Edge Canary 或 Edge Dev 中使用 Aion-1.0-指令,请启用 “启用设备预发行版”语言模型 标志,如以下步骤中所述。 启用此标志后,Aion-1.0-指令会替代 Phi-4-mini 作为提示 API 的默认模型。
请确保使用最新版本的 Edge Canary 或 Edge Dev (版本 150.0.4070 或更高版本) 。 请参阅 成为Microsoft Edge 预览体验成员。
在 Edge Canary 或 Edge Dev 中,打开一个新选项卡或窗口,然后转到
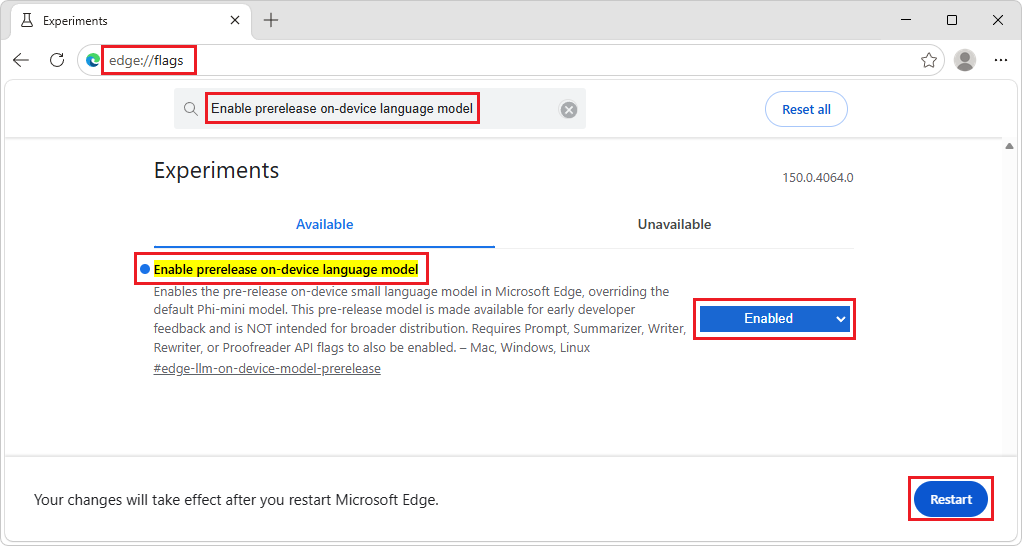
edge://flags。在页面顶部的搜索框中,输入 “启用设备预发行版语言模型”。
在 “启用设备预发行版语言模型 ”下拉列表中,选择“ 已启用”,然后单击“ 重启 ”按钮:
若要检查 Aion-1.0-指令用作设备语言模型,请转到
edge://on-device-internals,单击“模型状态”,检查将“模型名称”设置为“Aion-1.0-指令”。
免责声明
Microsoft Edge 150.0.4070 中提供了 Aion-1.0-指令模型,用于早期开发人员测试和反馈。 除了上面列出的负责任 AI 注意事项外,请注意,鉴于其预发布状态,模型行为和功能可能会发生更改。
Aion-1.0-指令模型的可用性
网站首次调用需要设备内模型的 API 时,需要初始下载 Aion-1.0-指令模型。 创建新的提示 API 会话时,可以使用监视器选项监视 Aion-1.0-指令模型的下载。 若要了解详细信息,请参阅下面的 监视模型下载进度。
启用提示 API
若要在 Microsoft Edge 中使用提示 API,请执行以下操作:
请确保使用最新版本的 Microsoft Edge Canary 或 Edge Dev (版本 138.0.3309.2 或更高版本) 。 请参阅 成为Microsoft Edge 预览体验成员。
在 Edge Canary 或 Edge Dev 中,打开一个新选项卡或窗口,然后转到
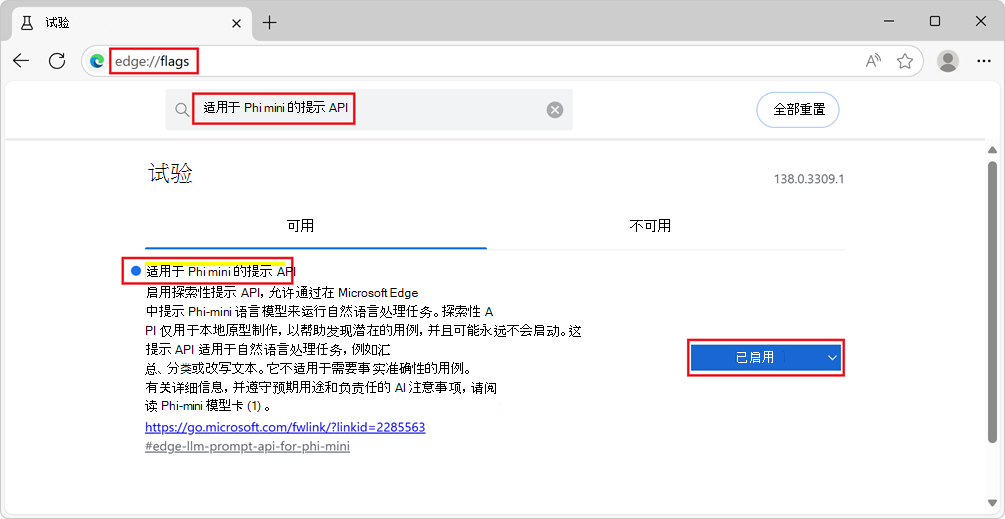
edge://flags/。在搜索框中,在页面顶部输入 “设备语言模型的提示 API”。
筛选页面以显示匹配标志。
在 “设备语言模型的提示 API”下,选择“ 已启用”:
(可选)若要在本地记录可能对调试问题有用的信息,还可以启用 “启用设备 AI 模型调试日志” 标志。
重启 Edge Canary 或 Edge 开发。
若要检查设备是否满足提示 API 开发人员预览版的硬件要求,请打开新选项卡,转到
edge://on-device-internals,然后检查设备性能类值。如果设备性能类为 “高 ”或“更高”,则设备上应支持提示 API。
如果设备性能类为 “中” 或 “低”,则仅通过预发布 Aion-1.0-指令模型支持提示 API,该模型从 Edge 版本 150.0.4070 开始可用。 若要测试 Aion-1.0-指令模型,请参阅上面的 为提示 API 启用 Aion-1.0-指令。
如果发现这些模型存在问题,请在 MSEdgeExplainers 存储库中 创建新问题 。
查看工作示例
若要查看操作中的提示 API,并查看使用 API 的现有代码,请执行以下操作:
在 Edge Canary 或 Edge Dev 中,打开选项卡或窗口,然后转到 “提示 API”操场。
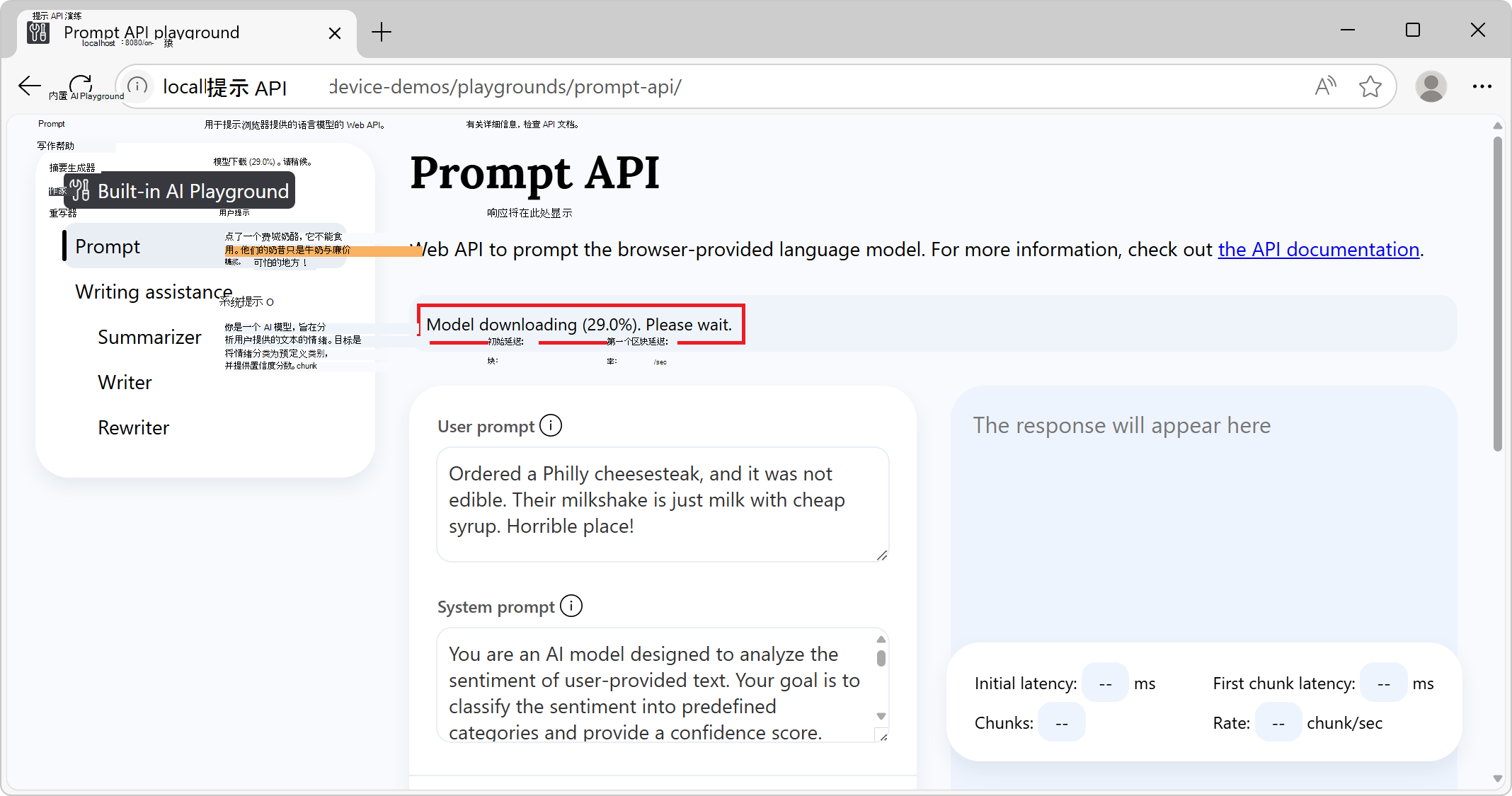
在左侧 的内置 AI 操场 导航中,已选择 “提示 ”。
在顶部的信息横幅中,检查状态:它最初读取模型下载,请稍候:
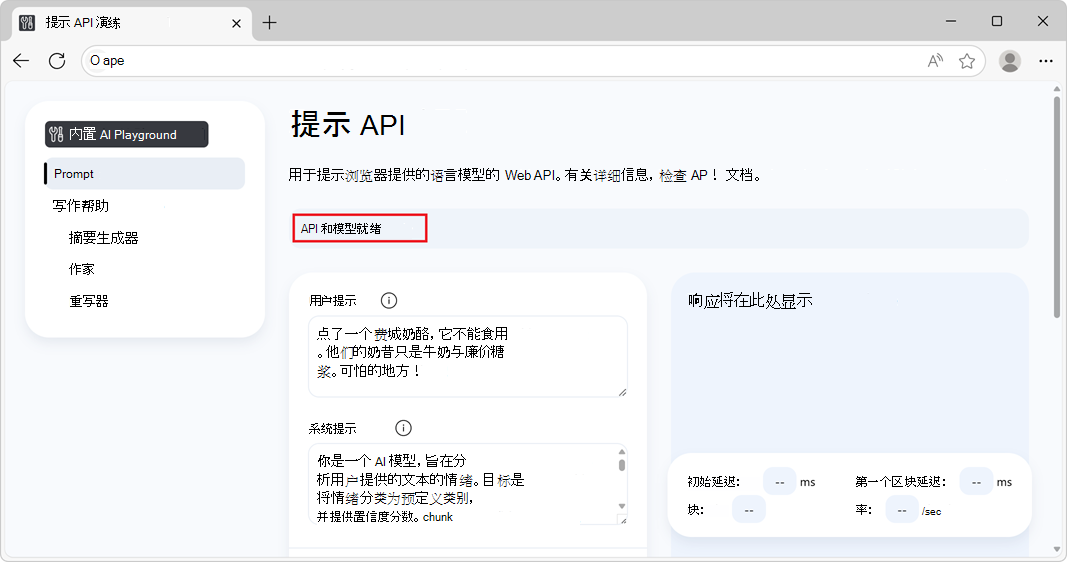
下载模型后,信息横幅将读取 API 和模型就绪,指示可以使用 API 和模型:
如果模型下载未启动,请重启Microsoft Edge,然后重试。
仅在满足某些硬件要求的设备上支持提示 API。 有关详细信息,请参阅上面的 硬件要求。
(可选)更改提示设置值,例如:
- 用户提示
- 系统提示
- 响应约束架构
- 更多设置>N-shot 提示说明
单击页面底部的 “提示” 按钮。
响应在页面的响应部分中生成:
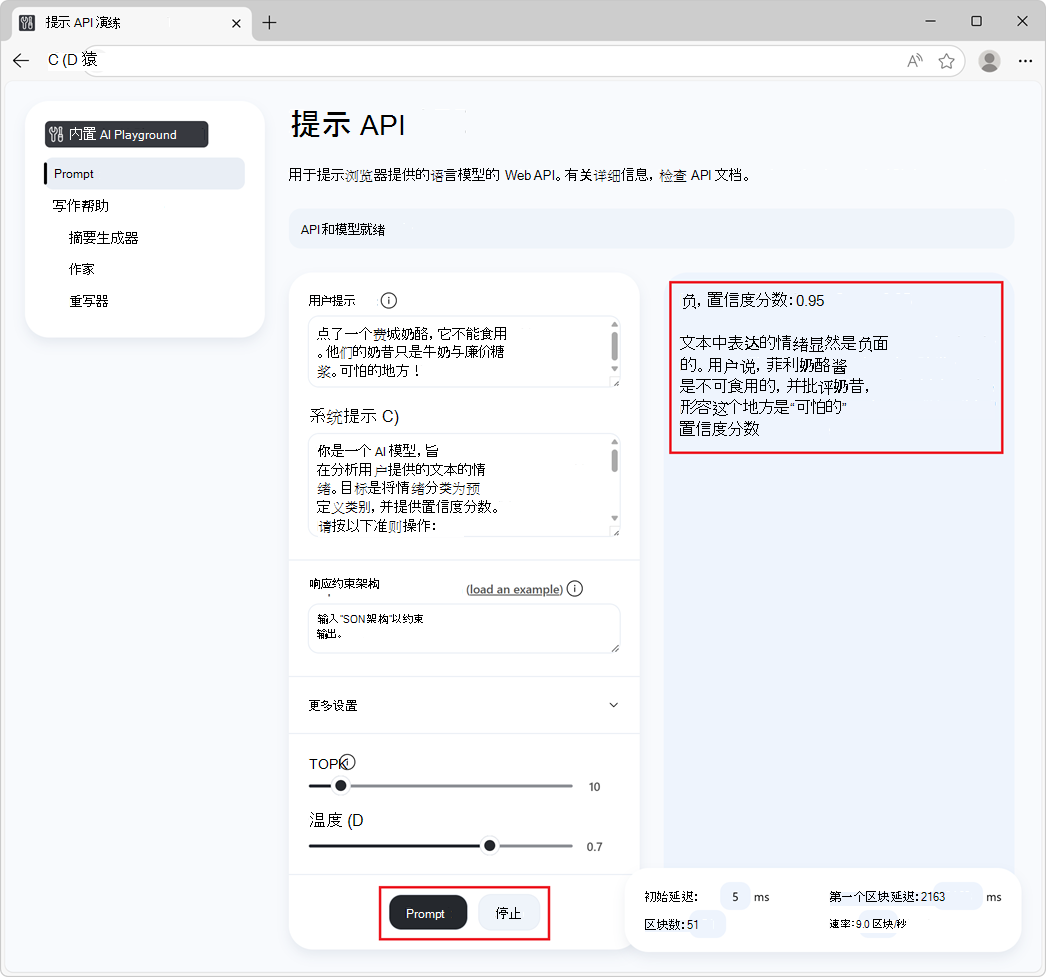
若要停止生成响应,请随时单击“ 停止 ”按钮。
另请参阅:
- /built-in-ai/ - 内置 AI 操场的源代码和自述文件,包括提示 API 操场。
使用提示 API
检查 API 是否已启用
在网站或扩展的代码中使用 API 之前,检查通过测试 对象的存在来启用 APILanguageModel:
if (!LanguageModel) {
// The Prompt API is not available.
} else {
// The Prompt API is available.
}
检查是否可以使用模型
仅当设备支持运行模型,并且语言模型和模型运行时已由 Microsoft Edge 下载后,才能使用提示 API。
若要检查是否可以使用 API,请使用 LanguageModel.availability() 方法:
const availability = await LanguageModel.availability();
if (availability == "unavailable") {
// The model is not available.
}
if (availability == "downloadable" || availability == "downloading") {
// The model can be used, but it needs to be downloaded first.
}
if (availability == "available") {
// The model is available and can be used.
}
创建新会话
创建会话会指示浏览器在内存中加载语言模型,以便可以使用它。 在提示语言模型之前,请使用 create() 方法创建新会话:
// Create a LanguageModel session.
const session = await LanguageModel.create();
若要自定义模型会话,可以将选项传递给 create() 方法:
// Create a LanguageModel session with options.
const session = await LanguageModel.create(options);
可用的选项包括:
monitor,以跟踪模型下载的进度。initialPrompts,以提供有关将发送到模型的提示的模型上下文,并建立用户/助手交互模式,模型应遵循将来的提示。
下面介绍了这些选项。
监视模型下载进度
可以使用 选项跟踪模型下载 monitor 进度。 当模型尚未完全下载到要使用的设备上时,这将非常有用,以通知网站用户他们应该等待。
// Create a LanguageModel session with the monitor option to monitor the model
// download.
const session = await LanguageModel.create({
monitor: m => {
// Use the monitor object argument to add an listener for the
// downloadprogress event.
m.addEventListener("downloadprogress", event => {
// The event is an object with the loaded and total properties.
if (event.loaded == event.total) {
// The model is fully downloaded.
} else {
// The model is still downloading.
const percentageComplete = (event.loaded / event.total) * 100;
}
});
}
});
为模型提供系统提示
若要定义系统提示(这是一种在生成文本以响应提示时提供模型说明的方法),请使用 initialPrompts 选项。
创建新会话时提供的系统提示会保留会话的整个存在状态,即使上下文窗口由于提示太多而溢出也是如此。
// Create a LanguageModel session with a system prompt.
const session = await LanguageModel.create({
initialPrompts: [{
role: "system",
content: "You are a helpful assistant."
}]
});
将 { role: "system", content: "You are a helpful assistant." } 提示置于 第 0 个位置之外的任何位置 initialPrompts ,将拒绝并显示 TypeError。
使用 initialPrompts 的 N-shot 提示
选项initialPrompts还允许你提供用户/助手交互的示例,你希望模型在出现提示时继续使用这些交互。
此方法也称为 N-shot 提示 ,对于使模型生成的响应更具确定性非常有用。
// Create a LanguageModel session with multiple initial prompts, for N-shot
// prompting.
const session = await LanguageModel.create({
initialPrompts: [
{ role: "system", content: "Classify the following product reviews as either OK or Not OK." },
{ role: "user", content: "Great shoes! I was surprised at how comfortable these boots are for the price. They fit well and are very lightweight." },
{ role: "assistant", content: "OK" },
{ role: "user", content: "Terrible product. The manufacturer must be completely incompetent." },
{ role: "assistant", content: "Not OK" },
{ role: "user", content: "Could be better. Nice quality overall, but for the price I was expecting something more waterproof" },
{ role: "assistant", content: "OK" }
]
});
克隆会话以使用相同的选项再次启动对话
克隆现有会话以提示模型,而无需了解先前的交互,但使用相同的会话选项。
如果想要使用上一个会话中的选项,但不影响先前响应的模型,克隆会话非常有用。
// Create a first LanguageModel session.
const firstSession = await LanguageModel.create({
initialPrompts: [
role: "system",
content: "You are a helpful assistant."
]
});
// Later, create a new session by cloning the first session to start a new
// conversation with the model, but preserve the first session's settings.
const secondSession = await firstSession.clone();
提示模型
若要提示模型,请在创建模型会话后使用 session.prompt() 或 session.promptStreaming() 方法。
等待最终响应
方法 prompt 返回一个承诺,该承诺在模型完成文本生成以响应提示后解析:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model and wait for the response to be generated.
const result = await session.prompt(promptString);
// Use the generated text.
console.log(result);
在生成令牌时显示令牌
方法 promptStreaming 立即返回流对象。 使用流在生成响应令牌时显示这些令牌:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model.
const stream = session.promptStreaming(myPromptString);
// Use the stream object to display tokens that are generated by the model, as
// they are being generated.
for await (const chunk of stream) {
console.log(chunk);
}
可以在同一会话对象中多次调用 prompt 和 promptStreaming 方法,以继续生成基于该会话中模型先前交互的文本。
使用 JSON 架构或正则表达式约束模型输出
若要使模型响应的格式更具确定性且更易于以编程方式使用,请在提示模型时使用 responseConstraint 选项。
选项 responseConstraint 接受 JSON 架构或正则表达式:
若要使模型使用遵循给定架构的字符串化 JSON 对象进行响应,请将 设置为
responseConstraint要使用的 JSON 架构。若要使模型使用与正则表达式匹配的字符串进行响应,请将 设置为
responseConstraint该正则表达式。
以下示例演示如何使模型使用遵循给定架构的 JSON 对象响应提示:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Define a JSON schema for the Prompt API to constrain the generated response.
const schema = {
"type": "object",
"required": ["sentiment", "confidence"],
"additionalProperties": false,
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "negative", "neutral"],
"description": "The sentiment classification of the input text."
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "A confidence score indicating certainty of the sentiment classification."
}
}
}
;
// Prompt the model, by providing a system prompt and the JSON schema in the
// responseConstraints option.
const response = await session.prompt(
"Ordered a Philly cheesesteak, and it was not edible. Their milkshake is just milk with cheap syrup. Horrible place!",
{
initialPrompts: [
{
role: "system",
content: "You are an AI model designed to analyze the sentiment of user-provided text. Your goal is to classify the sentiment into predefined categories and provide a confidence score. Follow these guidelines:\n\n- Identify whether the sentiment is positive, negative, or neutral.\n- Provide a confidence score (0-1) reflecting the certainty of the classification.\n- Ensure the sentiment classification is contextually accurate.\n- If the sentiment is unclear or highly ambiguous, default to neutral.\n\nYour responses should be structured and concise, adhering to the defined output schema."
},
],
responseConstraint: schema
}
);
运行上述代码将返回一个响应,其中包含字符串化的 JSON 对象,例如:
{"sentiment": "negative", "confidence": 0.95}
然后,可以通过使用 函数分析响应,在代码逻辑中使用 JSON.parse() 响应:
// Parse the JSON string generated by the model and extract the sentiment and
// confidence values.
const { sentiment, confidence } = JSON.parse(response);
// Use the values.
console.log(`Sentiment: ${sentiment}`);
console.log(`Confidence: ${confidence}`);
每个提示发送多条消息
除了字符串之外, prompt 和 promptStreaming 方法还接受对象数组,这些对象用于发送具有自定义角色的多个消息。 发送的对象应采用 的形式 { role, content },其中 role 为 user 或 assistant,并且 content 是消息。
例如,在同一提示中提供多个用户消息和助手消息:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model by sending multiple messages at once.
const result = await session.prompt([
{ role: "user", content: "First user message" },
{ role: "user", content: "Second user message" },
{ role: "assistant", content: "The assistant message" }
]);
停止生成文本
若要在 解决 由 返回的承诺之前或在 由 session.prompt()session.promptStreaming() 返回的流结束之前中止提示,请使用 AbortController 信号:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Create an AbortController object.
const abortController = new AbortController();
// Prompt the model by passing the AbortController object by using the signal
// option.
const stream = session.promptStreaming(myPromptString , {
signal: abortController.signal
});
// Later, perhaps when the user presses a "Stop" button, call the abort()
// method on the AbortController object to stop generating text.
abortController.abort();
销毁会话
销毁会话,让浏览器知道你不再需要语言模型,以便可以从内存中卸载该模型。
可以通过两种不同的方式销毁会话:
- 通过使用
destroy()方法。 - 通过使用
AbortController。
使用 destroy () 方法销毁会话
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Later, destroy the session by using the destroy method.
session.destroy();
使用 AbortController 销毁会话
// Create an AbortController object.
const controller = new AbortController();
// Create a LanguageModel session and pass the AbortController object by using
// the signal option.
const session = await LanguageModel.create({ signal: controller.signal });
// Later, perhaps when the user interacts with the UI, destroy the session by
// calling the abort() function of the AbortController object.
controller.abort();
发送反馈
提示 API 开发人员预览版旨在帮助发现浏览器提供的语言模型的用例。
我们有兴趣了解:
- 你打算使用提示 API 的方案范围。
- 提示 API 的任何问题。
- 语言模型的任何问题。
- 新的特定于任务的 API 是否有用。
若要发送有关方案和要实现的任务的反馈,请向 提示 API 反馈问题添加注释。
如果在改用 API 时发现任何问题,请在存储库中报告。
还可以在 W3C Web 机器学习工作组存储库中参与有关提示 API 设计的讨论。
另请参阅
- 提示 API 草稿规范
- webmachinelearning/prompt-api GitHub 存储库
- 使用编写辅助 API 编写、重写和汇总文本
- 使用校对 API 更正文本中的语法、拼写和标点错误
- 使用翻译器 API 翻译文本
- /built-in-ai/ - 内置 AI 操场的源代码和自述文件,包括提示 API 操场。