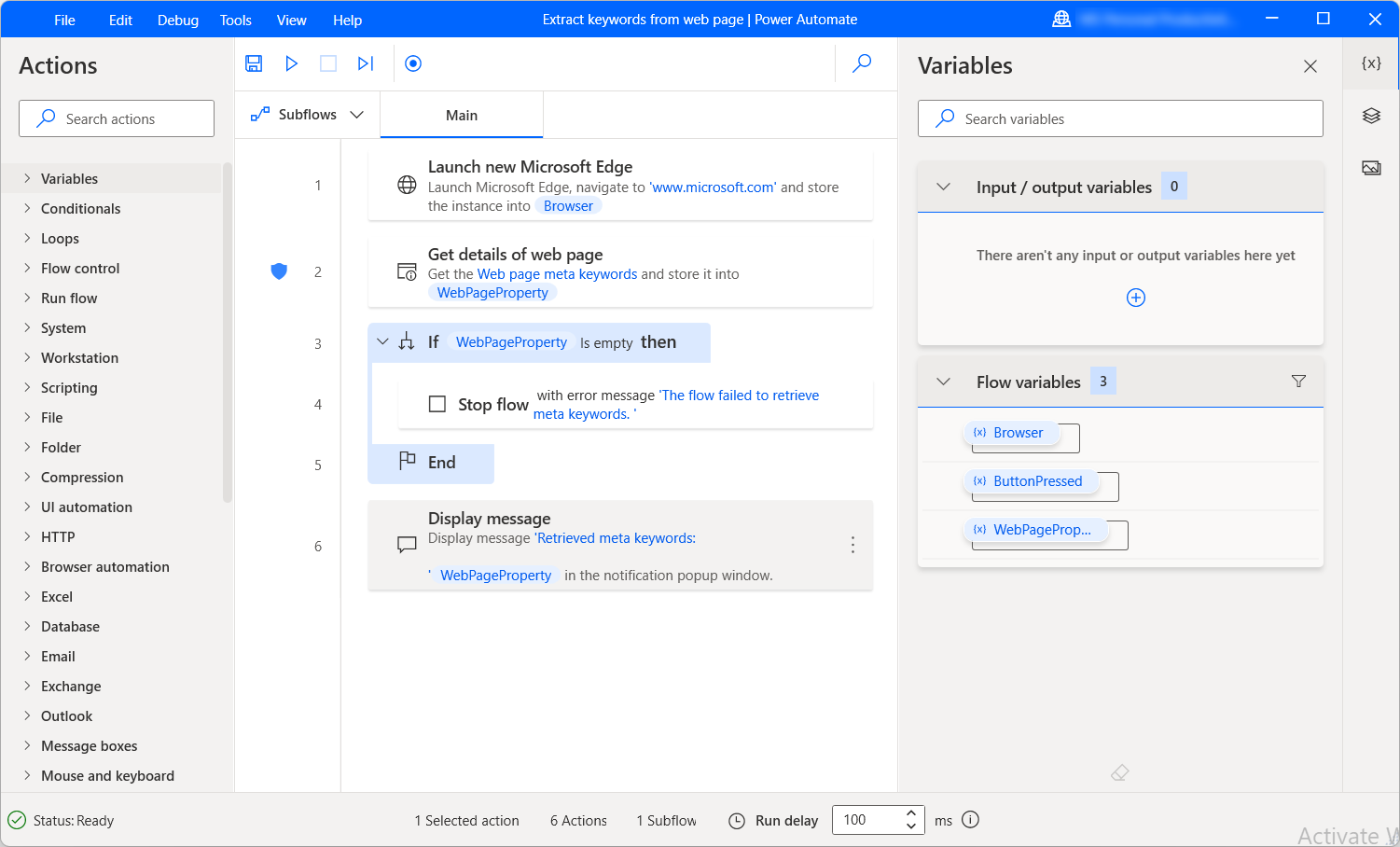
提取有关网页的信息是大多数 Web 相关流中的一项基本功能。 获取网页详细信息操作允许您从网页检索各种详细信息并在桌面流中进行处理。
要使用此操作,您需要一个已创建的浏览器实例,该实例指定您要从中提取详细信息的网页。 可以使用任何浏览器启动操作创建浏览器实例。
选择适当的浏览器实例后,选择要从网页中提取的信息。 获取网页详细信息操作提供了六个不同的选项:
- 网页的说明
- 网页的元关键字
- 网页的标题
- 网页的文本
- 网页的源代码
- 网页的 URL 地址
检索到的信息存储在名为 WebPageProperty 的文本变量中以供以后使用。
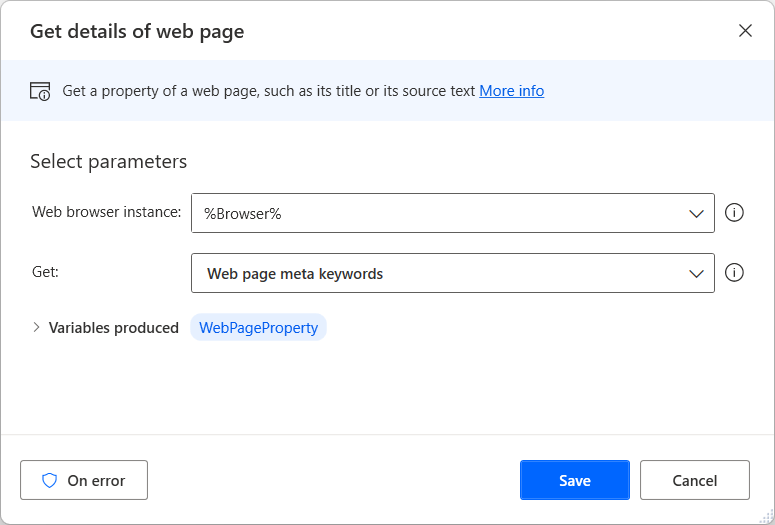
防止在检索详细信息时出错
虽然大多数属性实际上会存在于每个网页上,但在某些情况下,获取网页详细信息操作无法检索选择的详细信息。 例如,没有元关键字的网页很常见。
如果您不确定网页上是否存在某个属性,请配置获取网页详细信息操作的出错时选项以在失败后继续运行流。 要查找有关操作错误处理的更多信息,请参阅处理桌面流中的错误。
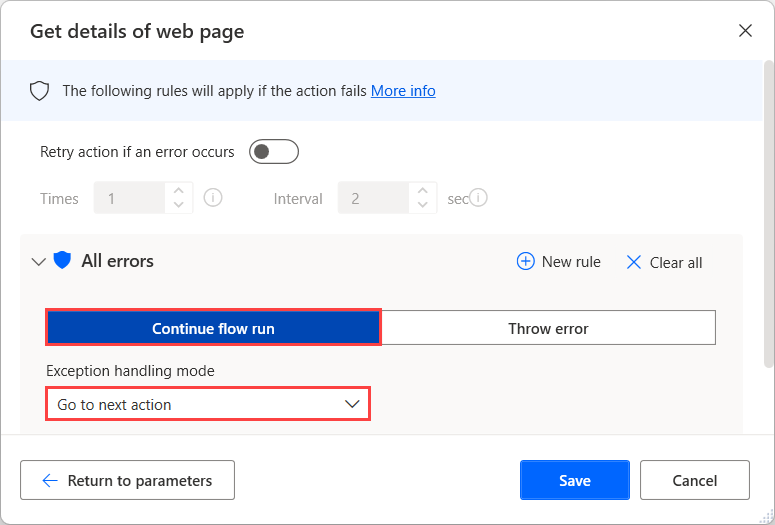
要确定数据提取是否成功,请使用 If 条件检查 WebPageProperty 变量是否为空。
此条件允许您针对成功和不成功的数据提取情况实现不同的功能。 您可以在使用条件中找到有关条件的详细信息。
以下示例子流从网页中检索可用的元关键字并将它们显示在消息框中。 如果提取不成功,流将停止并返回错误消息。