反模式是一种看似有益的做法,但会导致工作流中的性能问题、资源效率低下和潜在故障。 通过了解并避免这些反模式,可以优化云端流以获得更好的性能和可靠性。
避免嵌套 For each 循环
嵌套的“对于每项”循环可能是云端流中的资源密集型操作,会影响性能和资源消耗。
- 执行时间:嵌套循环会迅速增加迭代总数。 例如,如果有两个循环,每个循环有 10 次迭代,则迭代总数变为 10 x 10 = 100。 这种指数式增长会延长流的执行时间,尤其是在每次迭代处理大型数据集或执行复杂操作的情况下。
- 限制和配额:Power Automate 强制执行限制和配额,如循环内允许的最大迭代次数和整体执行时间。 嵌套循环可以快速接近这些限制,导致流失败或限制,尤其是在处理大型数据集或频繁执行时。
- 性能影响:嵌套循环中的每次迭代都会消耗处理能力和内存。 随着迭代次数的增加,对系统资源的需求也会增加,这可能会减慢整个流的速度。
了解更多信息:并发循环和拆分限制
根据您的方案,可以通过处理父表中的相关记录来避免嵌套循环。 请考虑以下事项:
场景:外循环使用列表行操作从 ProductCategory 表中检索产品类别列表,其中 IsPromotion 列为 true。 然后,内循环处理外循环检索到的每个类别的产品表中的相关记录。
其他方法:使用 OData 查询扩展来简化这一流程。 这种方法允许您使用单个“对于每项”循环,将请求 Dataverse 的总数减少到只需一次 RetrieveMultiple 调用。
实现 OData 查询扩展:
- 使用扩展查询参数指定将 ProductCategory 表链接到产品表的查找列名称。 此方法在单个查询中检索相关记录。 例如,将扩展查询参数设置为
Products($select=ProductName,Price)。 - 使用 $select 参数限制从相关表返回的列。
- 使用过滤行参数直接对查找表的列应用条件,以检索和处理相关记录。 例如,将过滤行参数设置为
IsPromotion eq true。

避免无限循环
使用 Power Automate,流可以无限触发,例如当流更新触发它的同一个表时。
保存可能导致无限触发循环的流时,Power Automate 会向您发出警告。
要避免无限循环:
- 使用触发条件:触发条件可确保流仅在满足特定条件时运行,从而避免不必要的执行。 通过向触发器添加条件来实现触发器条件,以在流继续之前检查某些值或状态。 例如,如果您的流更新了状态字段,则可以将触发条件设置为仅在状态尚未设置为所需值时才运行流。
- 终止流:另一种方法是,如果检测到会导致无限循环的条件,则停止流继续运行。 使用终止操作可在满足特定条件时终止流。 如果数据流即将进入无限循环,这种方法可用作防止进一步操作的保障措施。 例如,如果流检测到它已处理记录,则可以自行终止以避免重新处理。
避免大量数据转换操作
处理大规模数据转换时,请考虑使用提取、转换、加载(ETL)过程。 例如,不要使用 Power Automate 云端流从大型 Excel 电子表格中读取数据,而是执行数据格式化或验证,然后将数据写入 Dataverse。 使用 Power Platform 数据流 或其他 ETL 工具可能更合适。
与云端流相比,数据流可高效处理大量数据,并为 ETL 任务提供更好的性能。 ETL 工具提供用于数据转换、验证和加载的专用功能,可以简化复杂的数据处理任务。
若要使用云端流中的业务流程逻辑管理数据负载,请将云端流与数据流结合起来。 操作步骤如下:
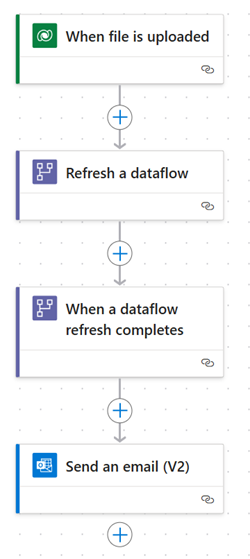
调用数据流刷新
- 操作:使用 Power Automate 中的数据流连接器触发刷新操作,并启动数据流中定义的 ETL 流程。
- 示例:设置一个云端流,根据计划(如每日)或事件(如新文件上传到 SharePoint 文件夹时)触发数据流刷新。
ETL 后操作
- 触发:使用 Power Automate 中的当数据流刷新完成时触发器,在 ETL 流程结束后执行操作。
- 示例:数据流完成后,使用云端流发送通知、更新记录或执行数据处理。
避免使用 For each 循环更新大量记录
当触发 Power Automate 中的流时,用户通常需要在数据源中创建或更新数千条记录。 许多用户使用“对于每项”循环按顺序处理每条记录,从而造成延迟和延时。
若要提高性能,请尝试以下两种方法:
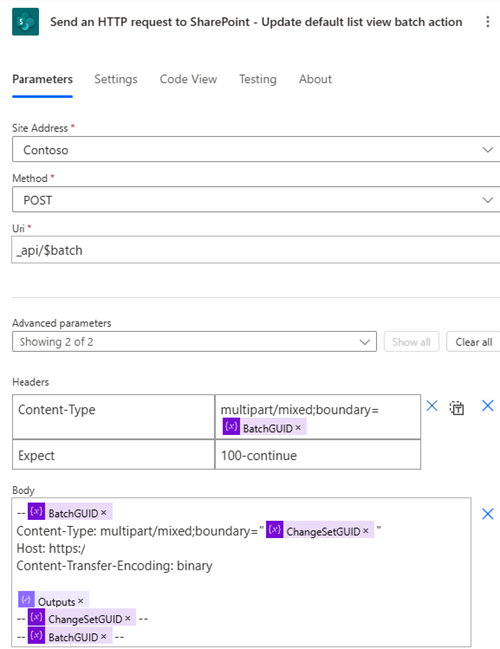
批量操作
- 描述:批量创建或更新记录。 许多连接器和服务都提供支持批处理请求的 API 终结点。 这种方法可将多个操作组合到一个 HTTP 请求中。
- 实现:使用批处理操作功能,一次发送多个创建或更新请求。 这些操作将按照批处理请求中指定的顺序依次执行。 响应的顺序与批操作中请求的顺序一致。
- 优点:减少发送到数据源的单个请求数量,最大限度地减少延迟并提高性能。
对于每项循环中的并行性
- 描述:在对于每项循环中启用并行处理功能,以同时处理多条记录。
- 实现:配置对于每项循环,以并行处理多达 50 条记录。 这种方法适用于不支持批处理操作的服务。
- 优点:通过同时处理多条记录,大大缩短整体处理时间。
有关发出批处理请求的信息,请参阅以下 REST API 文档:
在 Dataverse 中使用批量操作
使用 Dataverse 时,请使用批量操作 Web API 以减少所需操作的数量、简化流程并提高性能。
与批操作相比,批量操作 Web API 具有明显的优势。 以下是它们的不同之处:
- 批操作:虽然批操作是在单个请求中发布的,但它们是作为多个单独的操作执行的。 批次中的每个操作都是单独处理的。
- 批量操作:相反,批量操作是作为单个操作发布和执行的。 整个批量请求都算作一个操作,这样可以大大减少操作次数,提高效率。
调用批量操作:
- 使用带有 Microsoft Entra ID 的 HTTP:您可以使用通过 Microsoft Entra ID 进行身份验证的 HTTP 请求调用批量操作 Web API。
- 使用带有服务主体的 HTTP 连接器:或者,您也可以在使用服务主体时使用 Power Automate 中的 HTTP 连接器来调用这些 API。
在本例中,我们使用选择操作准备 JSON 格式的记录:

然后,我们使用带有 Microsoft Entra ID 的 HTTP,通过 CreateMultiple Web API 发布请求:
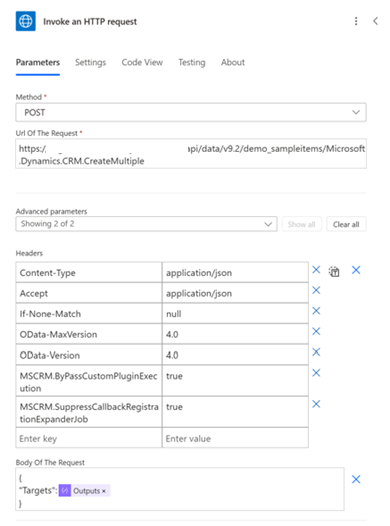
如果 JSON 输出中有 100 条记录,这种方法只会产生一个操作,而不是 Dataverse 中的 100 个创建行操作。