如果您已经熟悉 Power Automate Process Mining 桌面应用的基本功能,并了解流程挖掘的基础知识,则适合阅读本文。 它提供对计算方法的系统性介绍,之后您将能够定义所需的计算范围。
Power Automate Process Mining 中的指标
Process Mining 桌面应用提供了一组广泛的预定义标准指标(例如,事件数量、案例数量、案例平均持续时间、变体数量等)。 这些指标可以分为两个基本组:
聚合指标:最常见的结果。 显示 Process Mining 桌面应用中按所选上下文分组的计算值。
非聚合指标:显示每个数据元素的值,如事件、边缘或案例。
聚合度量
基于特定计算范围或上下文进行聚合或计算。 范围由 Process Mining 桌面应用中的不同分析视图定义。此示例使用流程图。
流程图是流程挖掘分析最常见的显示类型。 每个图元素 - 节点(活动)或路径(边缘)显示具有相同活动值的所有事件的聚合值。 在下面的示例中,您可以看到两个活动的表示形式:装配自行车和将零件发送给工程部。 对于这两个节点,显示的值表示数据集中的 109 个单个事件,并显示其所有聚合值。 在此案例中,它是事件的总数。
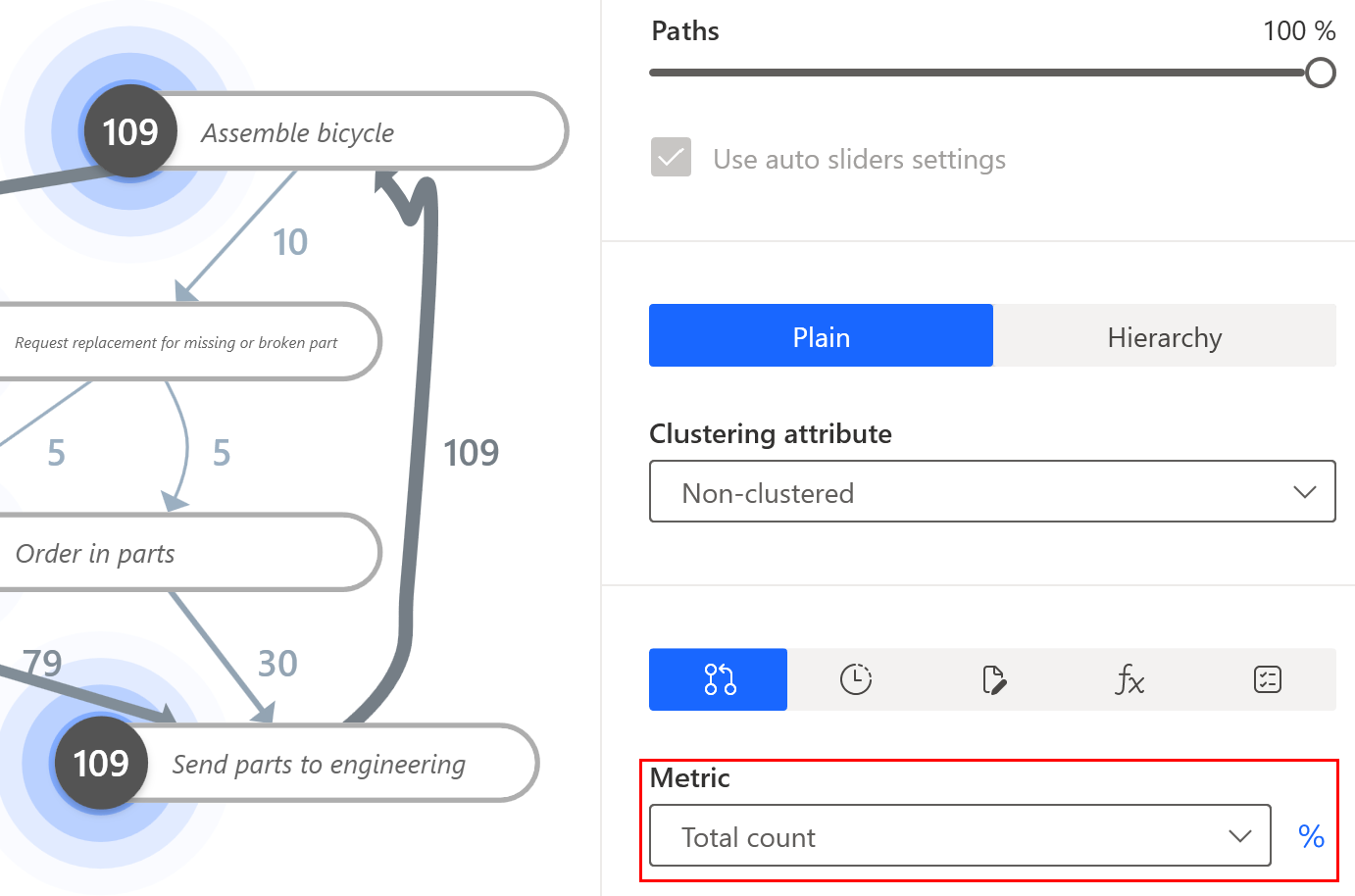
在右侧面板中选择另一个指标(最大持续时间)时,流程图显示 109 个具有活动装配自行车的事件中发生的最大持续时间,以及 109 个具有活动将零件发送给工程部的事件的最大持续时间。

每个属性的统计信息面板使用与流程图相同的聚合,其聚合每个属性值的结果。 如果您有资源(例如,统计信息面板中的用户属性),您可以看到实际视图中发生的每个用户的结果。
Process Mining 桌面应用按三个主要类别来显示聚合结果:
单个结果:通常每个实际数据集有一个全局值,例如,案例数。 输入是整个数据集,输出是单个结果。
每个案例的聚合:在统计信息中,案例概览面板结果按单个案例计算。 此类聚合的计算范围是案例事件或案例边缘。 输入是案例内的一组事件或边缘。 输出是一组结果,每个案例一个结果。
每个属性值的聚合:最常见的计算范围,由任何属性的流程图或统计信息面板表示。 输入是一组具有相同选定属性值的事件或边缘。 输出是一组结果,每个属性值一个结果。 默认流程图使用属性 activityName 计算具有相同 activityName 值的每组事件的结果。
在统计信息案例概览面板中,您可以看到视图中所有事件总数的全局单个结果。 在同一面板中,有所有案例的列表。 在案例表中,有一个名为事件计数的列。 这一次,此值表示案例中的事件数。 此分组称为按单个案例聚合。
在统计信息 activityName 面板中,有所有活动的列表。 活动表包含一个名为事件频率的列。 这一次,计算每个活动的事件计数。 此分组称为按属性值聚合。

我们在本文前面的聚合指标一节看到组装自行车和将零件发送给工程部活动的值 109。 所有三个指标类别的计算都是相同的,唯一的区别是计算范围。 第一个示例使用所有视图事件,计算单个结果。 第二个示例生成每个案例的结果,仅将每个结果用于给定案例中的事件。 最后一个示例为每个活动生成结果,并且仅使用具有给定活动值的事件的每个结果。
非聚合指标
聚合指标的主要区别在于,计算针对单个元素进行:无论是案例、事件还是边缘。 例如,如果为事件分配了资源属性,或者案例持续时间超出了定义的工作时间。 只有少数几个地方显示和提供了非聚合指标(和属性值):
案例概述的统计信息面板,其中显示每个案例的值。 请注意,所显示的指标是每个案例的聚合结果(基于给定案例中的事件),但从案例级别角度,这些指标是代表单个案例的非聚合指标。
案例/事件指标筛选器是显示非聚合值并可供用户使用的几个地方之一。
事件指标筛选器是显示和计算单个事件持续时间的良好示例。 事件筛选器单独处理每个事件,将按原样计算事件的属性或指标值。 Process Mining 桌面应用中的所有其他标准可视化都以某种聚合方式显示事件持续时间(例如,平均值、总计、最小值或最大值)。
自定义指标
自定义指标是由每个流程的用户定义的命名计算公式。 系统按照 Process Mining 桌面应用显示数据的标准方式应用此自定义指标。 以聚合和非聚合方式显示标准指标。 自定义指标必须遵从同一规则。 因此,有两种主要的不同类型的自定义指标:
标量(非聚合)公式—基于单个元素(如案例、边缘或事件)计算:简单标量公式的公式中不包含聚合运算。 在更为复杂的示例中,可以将聚合用作嵌套表达式的一部分(例如,将事件持续时间与所有事件的平均持续时间进行比较)。 重要的规则是标量公式的结果针对单个案例、边缘或事件生成。 单个结果不会被进一步分组,也不会被应用程序处理为聚合结果。
聚合公式—基于特定计算范围或“上下文”计算。 用户可以在公式中替换上下文: 聚合公式包含顶级计算级别的聚合运算符(例如,
AVG)。 Process Mining 桌面应用提供了一组标准聚合运算符 - 请参阅“自定义指标帮助”作为参考。 作为第一个参数的聚合运算使用计算范围。 这确定两个属性:考虑的输入数据集
结果的分组或粒度
输入数据集
您可以确定将数据集的哪一部分纳入计算。 只考虑属于同一活动的事件时需要计算流程图平均事件持续时间。
结果的分组或粒度
计算范围的另一个方面是确定结果的粒度。 整个视图中的平均事件持续时间是一个数字,结果计数正好是一。 计算流程图的值需要结果数量与流程图中的节点(例如,活动)数量一致。 我们已经知道,对于如何对结果进行分组,有三个主要类别:
- 单个全局结果
- 每个案例的聚合
- 每个属性值的聚合
自定义指标公式的一般形式
考虑以下任务:在手动输入订单编号且发票状态从未被拒绝的情况下,计算案例中的发票处理的每小时平均收入。
一般形式的逻辑分解
下表提供自定义指标的示例和说明。
| 示例 | 说明 |
|---|---|
| 聚合 | 聚合将多个结果(例如,每个案例)转换为单个值。 如果缺少聚合部分,我们有标量非聚合指标。 |
| 计算 | Process Mining 桌面应用中的标准计算为:Total(sum)、Mean(avg)、min、`max。两个属性的比值等高级计算需要通过自定义指标来完成。 |
| 数据筛选 | Process Mining 桌面应用中的筛选可以通过以下方式完成:筛选器、带条件运算符的自定义指标或带筛选器的业务规则。 |
示例显示在自定义指标中执行高级筛选的可能性。 为了简化示例,我们将重点关注聚合和计算部分。 当我们创建符合以下要求的视图筛选器时:订单编号是手动输入,发票状态从未被拒绝,我们可以简化任务。
简化的任务
为实际视图中的案例计算发票处理的每小时平均收入。
简化任务的逻辑分解
下表提供自定义指标的示例和说明。
| 示例 | 说明 |
|---|---|
| 聚合 | 聚合将多个结果(例如,每个案例)转换为单个值。 聚合的范围由上下文定义来定义。 |
| 计算 | Process Mining 桌面应用中的标准计算为:Total(sum)、Mean(avg)、min、max。两个属性的比值等高级计算需要通过自定义指标来完成。 |
| 数据筛选 | 简化筛选意味着范围或上下文定义。 |
聚合自定义指标的一般公式
Aggregation([Data filtration/scope], calculation)
将一般占位符替换为实际运算符和表达式:
Avg(ViewCases, 1.0 * InvoiceTotalAmountWithoutVAT / TOTALHOURS(Duration()))
聚合部分由简单平均运算符 (avg) 表示。
计算范围是公式本身要定义的第一部分。 我们使用视图中的所有案例查找单个全局结果。 这可以通过为上下文定义选择 ViewCases 值轻松实现。 使用聚合结果的其他类型(如每个案例或每个属性值)在此示例中没有使用。
核心计算完全通过包含四个元素的表达式完成:
转换为浮点 ("1.0 *")
属性规范 ("InvoiceTotalAmountWithoutVAT")
(案例)持续时间转换为时间单位“小时”(TOTALHOURS)
计算比值使用的除法