新的优化的 DirectLake 语义模型可以更快、更节省内存地分析流程。 通过节省内存,您可以分析较大的流程,并通过使用较小的 Fabric 容量来执行分析来节省成本。 此外,还使用了更直观的 Power BI 语义模型数据结构,可以让您花更少的时间和精力更深入地挖掘见解。
语义模型说明
将流程发布到 Fabric 工作区时,它会创建新的语义模型和相应的报表。 语义模型是在 Fabric 湖屋增量表之上创建的。
以下屏幕截图是发布到 Fabric 的语义模型结构的示例。

列命名
语义模型列的命名对应于引入数据集中列的命名,包括空格和其他特殊字符。 命名受 Power BI 语义模型限制。 然而,Fabric Lakehouse 增量表的命名限制更为严格(例如不允许空格),因此 Power Automate Process Mining 会在触发“导出到 Fabric 工作区”前进行验证和清理。
允许的字符包括:
-
a-z→ 小写英文字母 -
A-Z→ 大写英文字母 -
0-9→ 数字 -
_→ 下划线
作为清理过程的一部分,所有其他字符都将替换为下划线(_)。
这可能导致极少数情况下导出不成功,因为摄入的数据源包含两列在清理后产生相同名称的列—— Customer_Name 和 Customer Name。 导出将被中断,用户将收到特定错误消息的通知。
Lakehouse 增量表列因此使用清理后的列名,而语义模型列使用原始列名。
关系
视觉效果的过滤和互连所需的关系在发布的数据模型中预定义。 除非连接了其他数据源,否则不需要手动创建更多关系。 对于这个场景,使用 Power BI 复合语义模型,并在该模型之上构建关系。
数据模型摘要
从逻辑角度来看,数据模型由许多实体子集组成,如本节第一段所述。
- 流程数据:所有与流程相关的数据,没有经过过滤和计算
- 视觉数据:提供流程挖掘自定义视觉效果显示所需的预计算数据的实体
- 帮助实体:由 Power BI 需要的其他实体
以下是子集和包含的实体的简要说明。
流程数据
流程数据实体的内容在特定场景中会发生变化。
- 刷新流程模型数据时
- 创建新视图时
- 创建新的自定义度量时
- 用户更改任何流程视图中的过滤定义时
通过使用这些实体,您可以:
- 访问原始流程数据
- 受应用的筛选器影响的流程数据
- 访问根据应用的筛选器计算的度量值
| Entity | Description |
|---|---|
| 服务案例 | 流程中所有案例及其属性的列表。 每个案例都包含一个唯一的案例 ID 显示,以及每个案例属性的值,如映射设置步骤中所定义。 与 CaseMetrics 实体结合使用,以获得完整的案例信息。 |
| 活动 | 流程中所有事件属性的列表。 每个事件都有一个唯一的事件标识符索引,以及事件属性中每个属性的值,如映射设置步骤中所定义。 结合按 Is_Node 列筛选的 ProcessMapMetrics 实体,获得完整的事件信息。 |
| CaseMetrics | 实体包含与案例和视图的特定组合相关的所有案例级别指标。 Power Automate Process Mining 桌面应用程序中定义的案例级自定义指标将添加到此实体中。 |
| AttributesMetadata | 实体保存将事件日志数据导入流程模型时定义的所有案例/事件级属性的定义。 它包括数据类型、属性类型和属性级别(案例或事件)。 |
| MiningAttributes | 保存可用挖掘属性的值。 可以建立一个流程视图,根据所选的挖掘属性从不同的角度查看流程。 如果没有其他可用的挖掘属性,则实体保存 Activity 属性的值。 |
| 视图 | 在 Power Automate Process Mining 桌面应用程序中创建的可用(已发布)视图列表。 只有公共流程视图才会发布到数据集中。 条目可用于过滤报告、报告页面和视觉效果,以便只可视化特定流程视图中的数据。 |
| 变体 | 实体保存变体和流程视图之间的关系。 在考虑了过滤标准后,如果视图中包含特定变体,则会包含一条记录。 |
可视化数据
可视化数据实体只有在流程模型数据刷新时才会重新计算。
| Entity | Description |
|---|---|
| ProcessMapMetrics | 流程模型中所有节点和转换的汇总度量,需要在流程图自定义可视化中进行可视化。 该实体结合了事件(节点)信息和边缘(过渡)信息——要在其他视觉效果中使用事件或边缘,请按 Is_Node 列中的值进行过滤。 Power Automate Process Mining 桌面应用程序中定义的事件级自定义指标将添加到此实体中。 |
其他实体
| Entity | Description |
|---|---|
| LocalizationTable | 用于本地化目的的内部表格。 |
Power BI 复合模型
我们建议您在由 Power Automate Process Mining 发布的语义模型之上使用 Power BI 复合模型,并为这些场景创建必要的修改:
- 您需要创建更多数据源
- 您需要创建更多实体
- 您需要建立更多的关系
- 您需要创建更多自定义 DAX(数据分析表达式)查询
重要提示
语义模型是在 DirectLake 访问模式下创建的,但其选项设置为自动。 此设置意味着使用非最优 DAX 查询或错误地设置复合模型可能会导致回退到 DirectQuery 模式。 这意味着您的报表不会中断,但您可能会遇到性能降低的问题。
要了解有关在 DirectLake 语义模型上创建 Power BI 复合数据模型的更多信息,请访问:在语义模型或模型上构建复合模型。
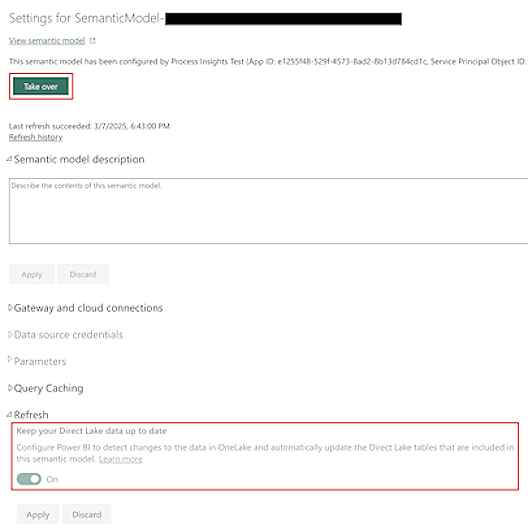
语义模型刷新
默认情况下,由 Power Automate Process Mining 提供的语义模型会自动保持最新。
对于大型数据集,OneLake 中基础表的数据刷新可能需要更长的时间。 这可能会导致报告中可能出现不一致。 尽管在数据刷新结束时存在最终一致性(语义模型会显式刷新),但您可能希望通过在语义模型的设置屏幕中关闭保持 Direct Lake 数据最新选项来消除潜在的中间不一致性。
在更新此屏幕之前,您需要通过在设置屏幕顶部选择接管来获取语义模型的所有权。