可以在 Power BI Desktop Power Query 编辑器中使用 Python,这是统计员、数据科学家和数据分析师广泛使用的编程语言。 通过 Python 与 Power Query 编辑器 的集成,可以使用 Python 执行数据清理,并在数据集中执行高级数据整形和分析,包括完成缺失的数据、预测和聚类分析,仅举几例。 Python 是一种功能强大的语言,可用于 Power Query 编辑器 来准备数据模型和创建报表。
先决条件
在开始之前,需要安装 Python 和 pandas。
安装 Python - 若要在 Power BI Desktop 的 Power Query 编辑器中使用 Python,需要在本地计算机上安装 Python。 可以从许多位置免费下载并安装 Python,包括 官方 Python 下载页和 Anaconda。
安装 pandas - 若要将 Python 与 Power Query 编辑器配合使用,还需要安装 pandas。 Pandas 用于在 Power BI 和 Python 环境之间移动数据。
将 Python 与 Power Query 编辑器配合使用
若要演示如何在 Power Query 编辑器中使用 Python,请根据可从 此处下载 的 CSV 文件从股市数据集中获取此示例,然后继续学习。 此示例的步骤如下:
首先,将数据加载到 Power BI Desktop 中。 在此示例中,加载 EuStockMarkets_NA.csv 文件,并从 Power BI Desktop 中的>”功能区选择“获取数据文本/CSV”。
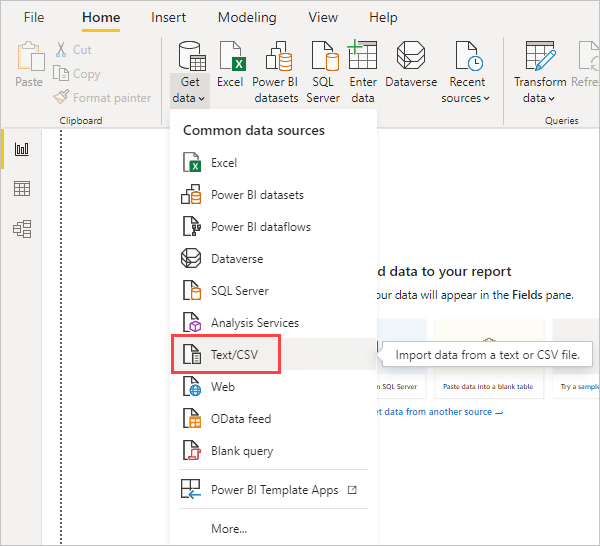
选择该文件并选择 “打开”,CSV 将显示在 “CSV 文件 ”对话框中。

加载数据后,可在 Power BI Desktop 的“字段”窗格中看到数据。
通过从 Power BI Desktop 中的“开始”选项卡选择“转换数据”打开 Power Query 编辑器。

在 “转换 ”选项卡中,选择“ 运行 Python 脚本 ”,并显示 “运行 Python 脚本 ”编辑器,如下一步所示。 第 15 行和 20 行因缺少数据而受到影响,正如你无法在下图中看到的其他行一样。 以下步骤演示 Python 如何为你完成这些行。

对于此示例,请输入以下脚本代码:
import pandas as pd completedData = dataset.fillna(method='backfill', inplace=False) dataset["completedValues"] = completedData["SMI missing values"]注释
需要在 Python 环境中安装 pandas 库,以便以前的脚本代码正常工作。 若要安装 pandas,请在 Python 安装中运行以下命令:
pip install pandas放入 “运行 Python 脚本 ”对话框时,代码如以下示例所示:

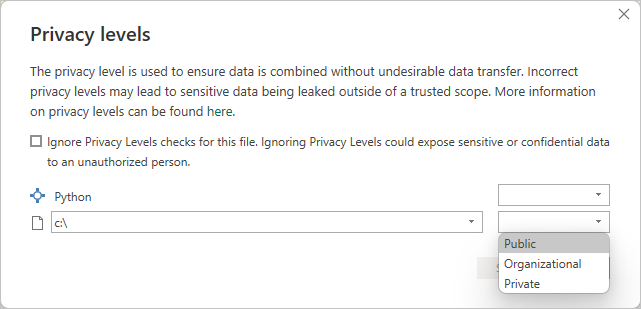
选择 “确定”后, Power Query 编辑器 会显示有关数据隐私的警告。

若要使 Python 脚本在 Power BI 服务中正常工作,所有数据源都需要设置为 公共。 有关隐私设置及其含义的详细信息,请参阅 隐私级别。
请注意字段窗格中名为completedValues的新列。 请注意,有一些缺失的数据元素,例如第 15 行和第 18 行。 查看 Python 在下一部分中如何处理它。
只有三行 Python 脚本, Power Query 编辑器 使用预测模型填充了缺失的值。
从 Python 脚本数据创建视觉对象
现在,我们可以创建视觉对象以查看如何使用 pandas 库的 Python 脚本代码完成缺失值,如下图所示:
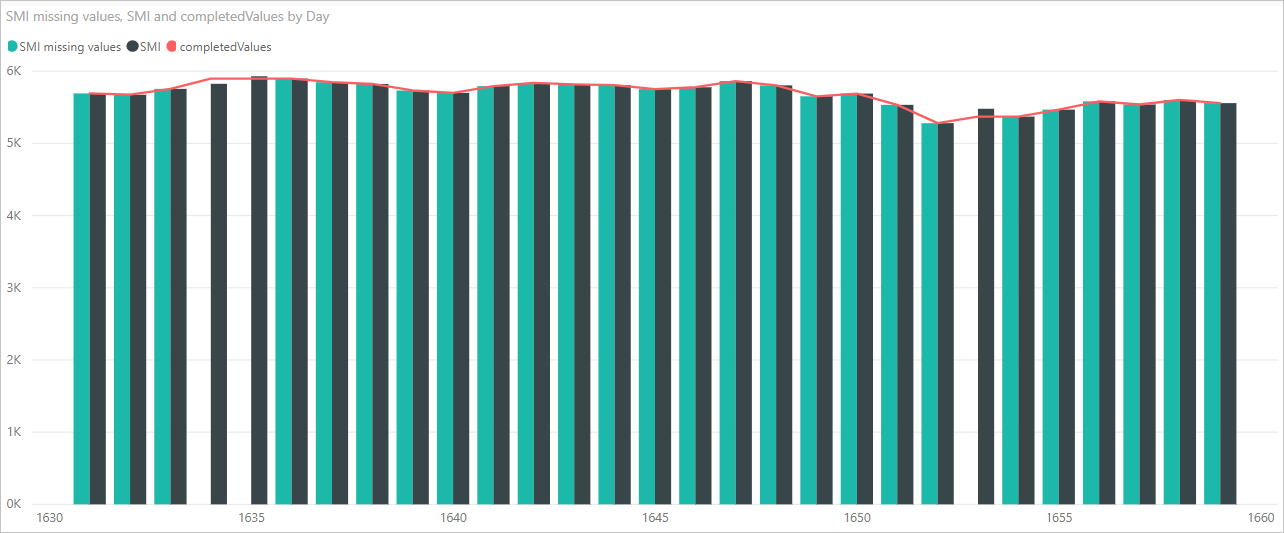
该视觉对象完成后,以及你可能想要使用 Power BI Desktop 创建的任何其他视觉对象后,可以保存 Power BI Desktop 文件。 使用 .pbix 文件扩展名保存 Power BI Desktop 文件。 然后,在 Power BI 服务中使用数据模型,包括其中一部分的 Python 脚本。
注释
想要查看已完成这些步骤的 .pbix 文件吗? 你运气好。 可以在此处下载这些示例中使用的已完成的 Power BI Desktop 文件。
将 .pbix 文件上传到 Power BI 服务后,还需要执行几个步骤才能使数据在服务中刷新,并使视觉对象能够在服务中更新。 数据需要访问 Python 才能更新视觉对象。 其他步骤是以下步骤:
- 为数据集启用计划刷新。 若要使用 Python 脚本为包含数据集的工作簿启用 计划刷新,请参阅“配置计划刷新”,其中包括有关 个人网关的信息。
- 安装个人网关。 需要在文件所在的计算机上安装 个人网关 ,以及安装 Python 的位置。 Power BI 服务必须访问该工作簿并重新呈现任何更新的视觉对象。 有关详细信息,请参阅 安装和配置个人网关。
注意事项和限制
有关包含在 Power Query 编辑器中创建的 Python 脚本的查询存在一些限制:
所有 Python 数据源设置都必须设置为 “公共”,并且 Power Query 编辑器 中创建的查询中的所有其他步骤也必须是公共的。 若要访问数据源设置,请在 Power BI Desktop 中选择 “文件 > 选项”和“设置 > 数据源设置”。
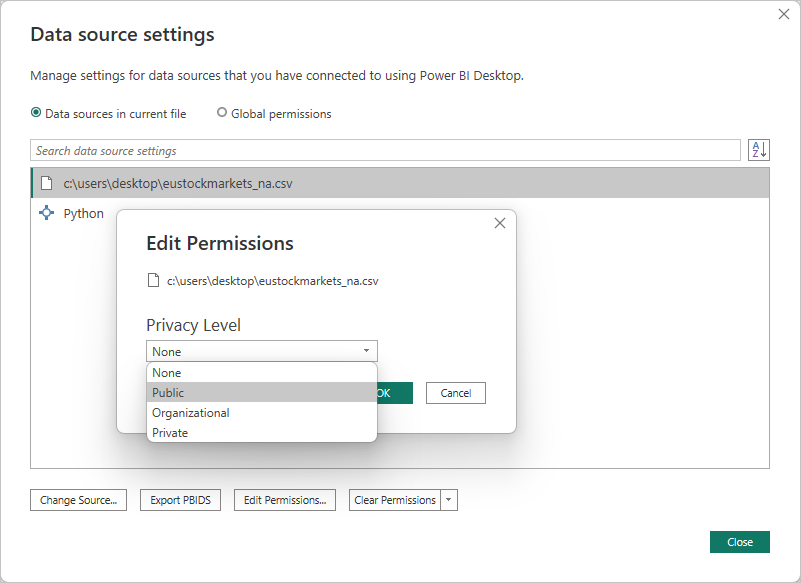
在 “数据源设置” 对话框中,选择数据源,然后选择“ 编辑权限 ...”,并确保 隐私级别 设置为 “公共”。
若要启用 Python 视觉对象或数据集的计划刷新,需要启用 计划刷新 ,并在装有工作簿和 Python 安装的计算机上安装个人网关。 有关这两者的详细信息,请参阅本文中的上一部分,其中提供了有关每个内容的详细信息的链接。
目前不支持嵌套表格(即表格中的表格)。
可以使用 Python 和自定义查询来执行各种操作,从而探索和调整数据,使其按照您的期望显示。