Power BI 语义模型可以在高度压缩的内存中缓存中存储数据,以便优化查询性能,从而实现快速的用户交互性。 默认大小限制为 1 GB。 使用 Fabric 容量时,如果启用了 大型语义模型存储格式 设置,语义模型可能会超出默认大小限制。 使用大型存储格式时,大小限制等于 Fabric 容量 大小或容量管理员设置 的最大大小 。 对于分配给 预留容量 的 Pro 工作区,其语义模型的大小限制为 1 GB。
可以为所有的 Fabric F SKU、高级 P SKU 和嵌入式 A SKU 启用 大型语义模型存储格式 设置,并将 Premium Per User(PPU)和 Pro 工作区分配到Pro 工作区预留容量。
要使语义模型的规模超过 10 GB,需要启用 大型语义模型存储格式,而且这样做还有其他好处。 如果您计划使用基于 XMLA 的工具来进行语义模型写入操作,请务必启用此设置。即使是那些您不一定会认为是大型的语义模型,因为大型存储格式可以提高 XMLA 的写入性能。 Pro 工作区中的语义模型不支持基于 XMLA 的写入操作。
服务中的大型语义模型不会影响 Power BI Desktop 模型上传大小,该大小仍限制为 10 GB。 然而刷新后,服务中的语义模型可超过该限制。
重要
Power BI Premium 支持大型语义模型。 启用“大型语义模型存储格式”选项,以在 Power BI Premium 中使用大于默认限制的语义模型。
注意
Power BI Premium 中的大型语义模型在美国政府 DoD 客户 Power BI 服务中不可用。 有关哪些功能可用以及哪些功能不可用的详细信息,请参阅 美国政府客户的 Power BI 功能可用性。
启用大型语义模型
此处所列步骤介绍了如何为发布到服务的新模型启用大型语义模型。 对于现有语义模型,只需要步骤 3。
在 Power BI Desktop 中创建模型。 如果语义模型变大且逐渐消耗更多内存,请确保配置 增量刷新。
将模型作为语义模型发布到服务。
在“服务”>“语义模型”>“设置”中,展开“大型语义模型存储格式”,将滑块设置为“启用”,然后选择“应用”。

调用刷新以加载基于增量刷新策略的历史记录数据。 第一次刷新可能需要一些时间来加载历史记录。 后续刷新速度应会更快,具体取决于增量刷新策略。
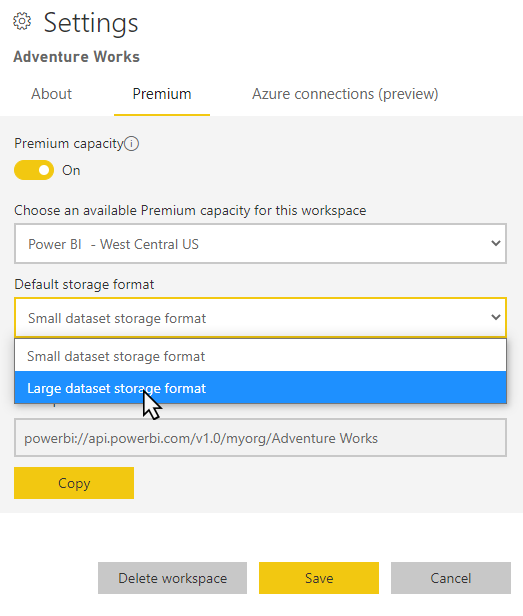
设置默认存储格式
在受支持的区域,对于在分配给高级容量的工作区中创建的所有新语义模型,默认情况下都可以启用大型语义模型存储格式。 如果区域不支持大型语义模型,则会禁用“大型语义模型存储格式”选项。 可以在区域可用性部分查看哪些区域受支持。
在工作区中,选择“设置”“高级”>。
在“默认存储格式”中,选择“大型语义模型存储格式”,然后选择“保存”。
使用 PowerShell 启用
还可以使用 PowerShell 启用大型语义模型存储格式。 若要运行 PowerShell cmdlet,必须拥有容量管理员和工作区管理员权限。
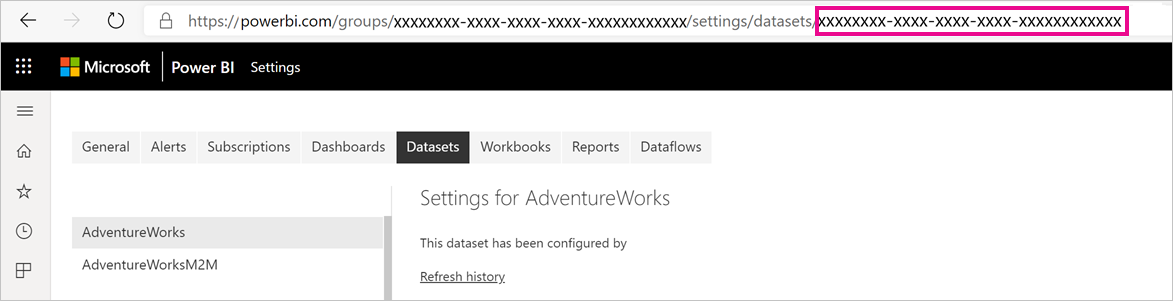
查找语义模型 ID (GUID)。 在工作区的“语义模型”选项卡上的语义模型设置下,可以看到 URL 中的 ID。
从 PowerShell 管理员提示符,安装 MicrosoftPowerBIMgmt 模块。
Install-Module -Name MicrosoftPowerBIMgmt运行以下 cmdlet 以登录并检查语义模型存储模式。
Login-PowerBIServiceAccount (Get-PowerBIDataset -Scope Organization -Id <Semantic model ID> -Include actualStorage).ActualStorage响应应如下所示。 存储模式为 ABF(Analysis Services 备份文件),这是默认设置。
Id StorageMode -- ----------- <Semantic model ID> Abf运行以下 cmdlet 以设置存储模式。 转换为“高级文件”可能需要几秒钟。
Set-PowerBIDataset -Id <Semantic model ID> -TargetStorageMode PremiumFiles (Get-PowerBIDataset -Scope Organization -Id <Semantic model ID> -Include actualStorage).ActualStorage响应应如下所示。 现在,存储模式已设置为“高级文件”。
Id StorageMode -- ----------- <Semantic model ID> PremiumFiles
可以使用 Get-PowerBIWorkspaceMigrationStatus cmdlet 检查语义模型转换的状态。
语义模型逐出
语义模型逐出是一项高级版功能,它允许语义模型大小之和明显大于容量购买的 SKU 大小的可用内存。 单个语义模型仍受 SKU 内存限制。 Power BI 使用动态内存管理从内存中逐出不活动的语义模型。 逐出语义模型,以便 Power BI 可以加载其他语义模型来处理用户查询。
注意
如果必须等待逐出语义模型重新加载,可能会遇到明显的延迟。
按需加载
默认情况下,对大型语义模型启用按需加载可显著缩短逐出语义模型的加载时间。 通过按需加载,你可在后续查询和刷新期间获得以下好处:
相关数据页按需进行加载(分页到内存中)。
逐出的语义模型可快速用于查询。
按需加载可显示附加的动态管理视图 (DMV) 信息,可用于识别使用模式和了解模型的状态。 例如,可通过从 SQL Server Management Studio (SSMS) 运行以下 DMV 查询来检查语义模型中每一列的“Temperature”和“Last Accessed”统计信息:
Select * from SYSTEMRESTRICTSCHEMA ($System.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS, [DATABASE_NAME] = '<Semantic model Name>')
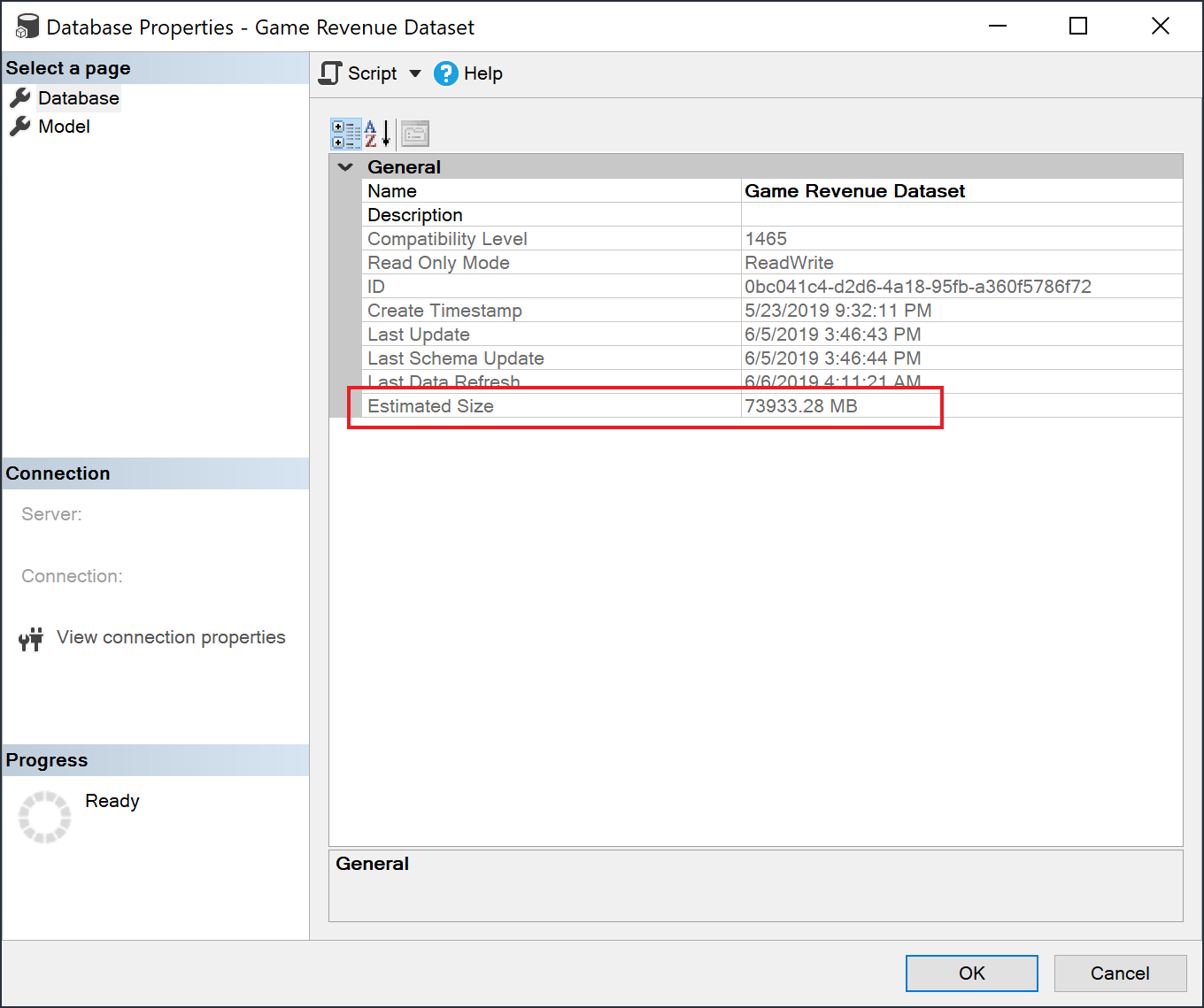
检查语义模型大小
加载历史记录数据后,可以通过 XMLA 终结点使用 SSMS 在模型属性窗口中检查估计的语义模型大小。
还可以从 SSMS 运行以下 DMV 查询来检查语义模型大小。 对输出中的 DDICTIONARY_SIZE 和 USED_SIZE 列求和,得出以字节为单位的语义模型大小。
SELECT * FROM SYSTEMRESTRICTSCHEMA
($System.DISCOVER_STORAGE_TABLE_COLUMNS,
[DATABASE_NAME] = '<Semantic model Name>') //Sum DICTIONARY_SIZE (bytes)
SELECT * FROM SYSTEMRESTRICTSCHEMA
($System.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS,
[DATABASE_NAME] = '<Semantic model Name>') //Sum USED_SIZE (bytes)
默认段大小
对于使用大型语义模型存储格式的语义模型,Power BI 会自动将默认段大小设置为 8,000,000 行,以便在大型表的内存需求和查询性能之间取得良好的平衡。 这与 Azure Analysis Services 中的段大小相同。 在将大型数据模型从 Azure Analysis Services 迁移到 Power BI 时,保持段大小一致有助于确保具有同等的性能特征。
注意事项和限制
使用大型语义模型时,记住以下限制:
支持的区域:大型语义模型在支持 Azure 高级文件存储的 Azure 区域中可用。 查看区域可用性中的表,以查看所有受支持区域的列表。
设置最大语义模型大小:管理员可以设置最大语义模型大小。 有关详细信息,请参阅数据集中的最大内存。
刷新大型语义模型:接近容量大小一半的语义模型(例如,25 GB 容量大小的 12 GB 语义模型)可能会在刷新期间超过可用内存。 使用增强型刷新 REST API 或 XMLA 终结点可以执行细化的数据刷新,从而能够最大程度减少刷新所需内存,以适应容量大小。
推送语义模型:推送语义模型不支持大型语义模型存储格式。
默认情况下,无法使用 REST API 更改工作区的设置以允许新语义模型使用大型语义模型存储格式。
区域可用性
Power BI 中的大型语义模型仅在支持 Azure 高级文件存储的 Azure 区域中提供。
以下列表提供了可以使用 Power BI 中的大型语义模型的区域。 未在以下列表中列出的区域不支持使用大型模型。
注意
在工作区中创建大型语义模型后,该模型必须留在该区域内。 不能将具有大型语义模型的工作区重新分配到其他区域的高级功能容量中。
| Azure 云区域 | Azure 区域缩写 |
|---|---|
| 澳大利亚东部 | australiaeast |
| 澳大利亚东南部 | 澳大利亚东南部 |
| 奥地利东部 | austriaeast |
| 巴西南部 | 巴西南部 |
| 巴西南部 B | brazilsouthb |
| 加拿大中部 | canadacentral |
| 加拿大东部 | 加拿大东部 |
| 印度中部 | centralindia |
| 美国中部 | centralus |
| 智利中部 | 智利中部 |
| 东亚 | eastasia |
| 美国东部 | eastus |
| 美国东部 2 | eastus2 |
| 法国中部 | francecentral |
| 法国南部 | francesouth |
| 德国北部 | germanynorth |
| 德国中西部 | 德国西中部 |
| 印度尼西亚中部 | indonesiacentral |
| 以色列中部 | 以色列中心 |
| 意大利北部 | 意大利北部 |
| 日本东部 | 日本东部 |
| 日本西部 | 日本西部 |
| 韩国中部 | koreacentral |
| 韩国南部 | 韩国南方 |
| 马来西亚西部 | 马来西亚西部 |
| 墨西哥中部 | 墨西哥中部 |
| 新西兰北部 | 新西兰北部 |
| 美国中北部 | northcentralus |
| 北欧 | northeurope |
| 挪威东部 | 挪威东部 |
| 挪威西部 | 挪威西部 |
| 波兰中部 | polandcentral |
| 卡塔尔中部 | 卡塔尔中央 |
| 新加坡 | 新加坡 |
| 南非北部 | southafricanorth |
| 南非西部 | 南非西部 |
| 美国中南部 | southcentralus |
| 东南亚 | 东南亚 |
| 印度南部 | 南印度 |
| 西班牙中部 | 西班牙中部 |
| 瑞典中部 | Swedencentral |
| 瑞士北部 | switzerlandnorth |
| 瑞士西部 | 瑞士西部 |
| 台湾北部 | taiwannorth |
| 台湾西北 | 台湾西北 |
| 阿联酋中部 | uaecentral |
| 阿拉伯联合酋长国北部 | uaenorth |
| 英国南部 | uksouth |
| 英国西部 | ukwest |
| 西欧 | 欧洲西部 |
| 印度西部 | westindia |
| 美国西部 | westus |
| 西部美国 2 | westus2 |
| 美国西部 3 | westus3 |
相关内容
以下链接提供了与使用大型模型相关的有用信息: