概要
| 条目 | DESCRIPTION |
|---|---|
| 发布状态 | 一般可用性 |
| 产品 | Excel Power BI (语义模型) Power BI (数据流) Fabric(Dataflow Gen2) Power Apps(数据流) Dynamics 365 Customer Insights Analysis Services |
| 功能参考文档 |
File.Contents Lines.FromBinary Csv.Document |
注释
由于部署计划和主机特定的功能,某些功能可能存在于一个产品中,但不是其他功能。
支持的功能
- 进口
从 Power Query Desktop 连接到本地文本/CSV 文件
加载本地文本或 CSV 文件:
在“获取数据”中选择“文本/CSV”选项。 此作将启动本地文件浏览器,可在其中选择文本文件。
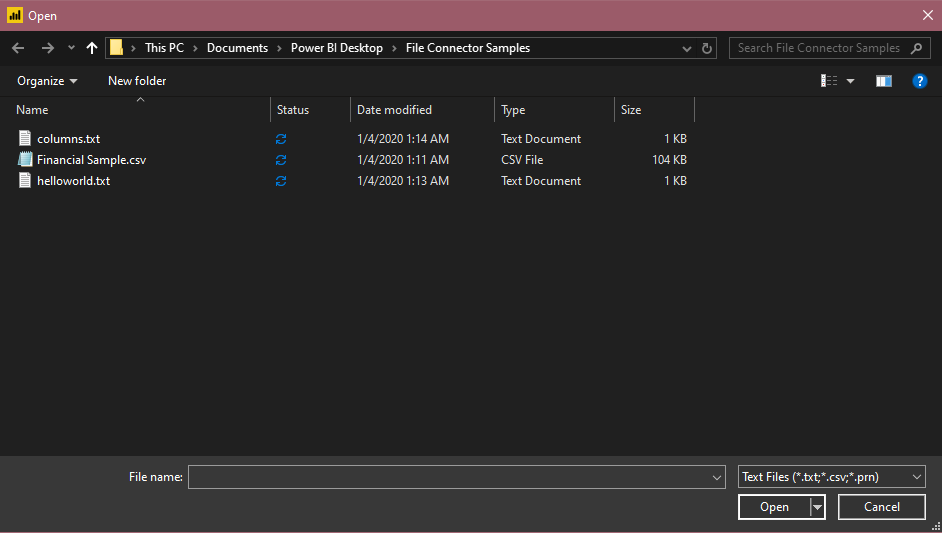
选择“打开”以打开该文件。
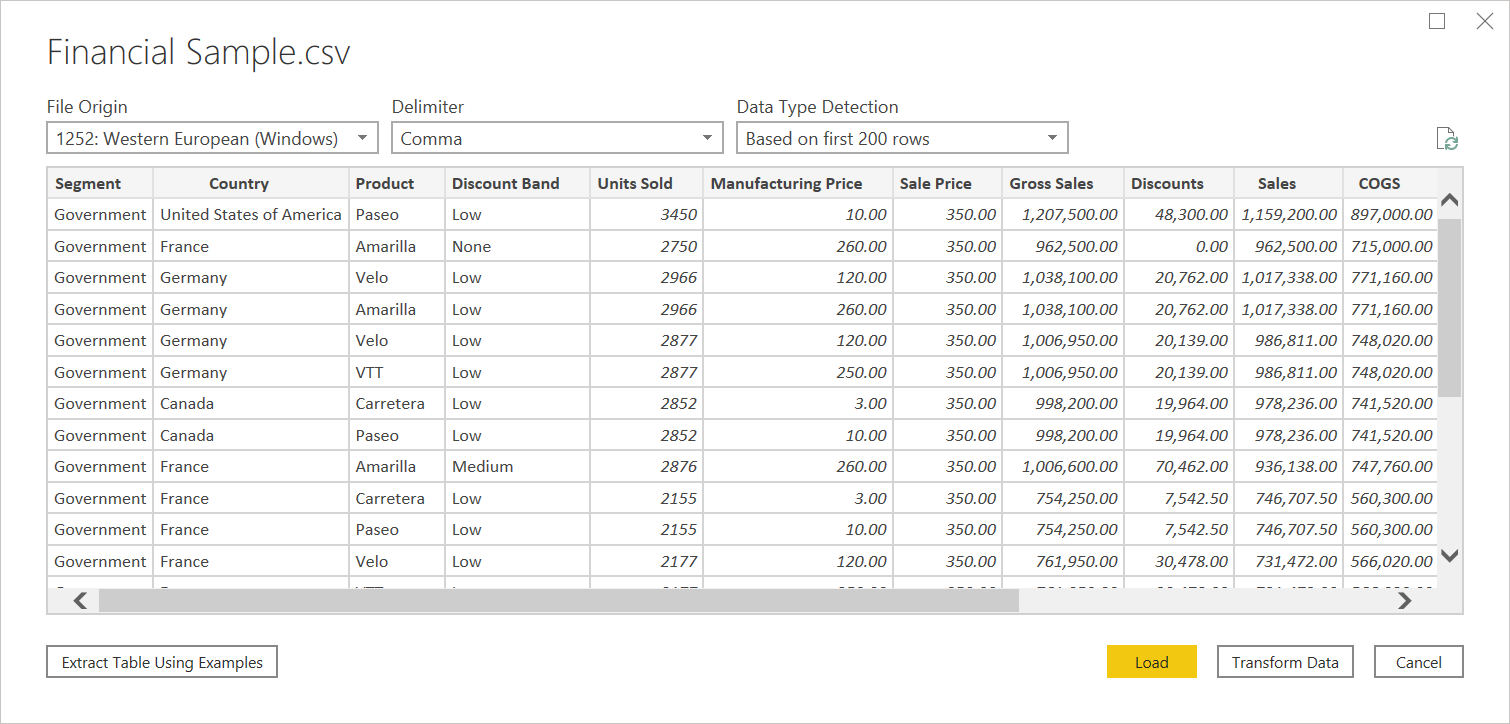
在 导航器中,可以通过选择“ 转换数据”来转换 Power Query 编辑器中的数据,也可以 通过选择“加载”来加载数据。

从 Power Query Online 连接到文本/CSV 文件
加载本地文本或 CSV 文件:
在 “数据源 ”页中,选择 “文本/CSV”。
在 “连接”设置中,上传文件或输入文件路径到所需的本地文本或 CSV 文件。
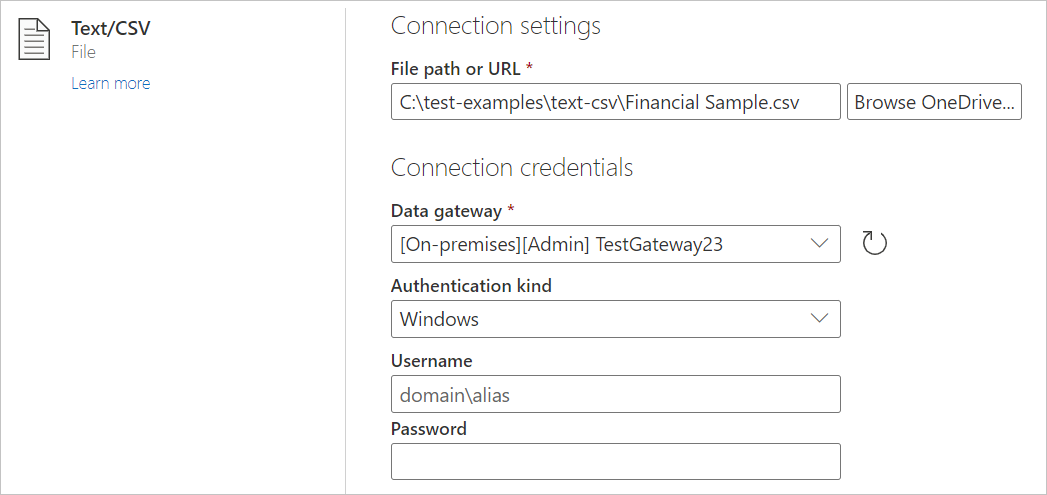
从 数据网关选择本地数据网关。
输入用户名和密码。
选择“下一步”。
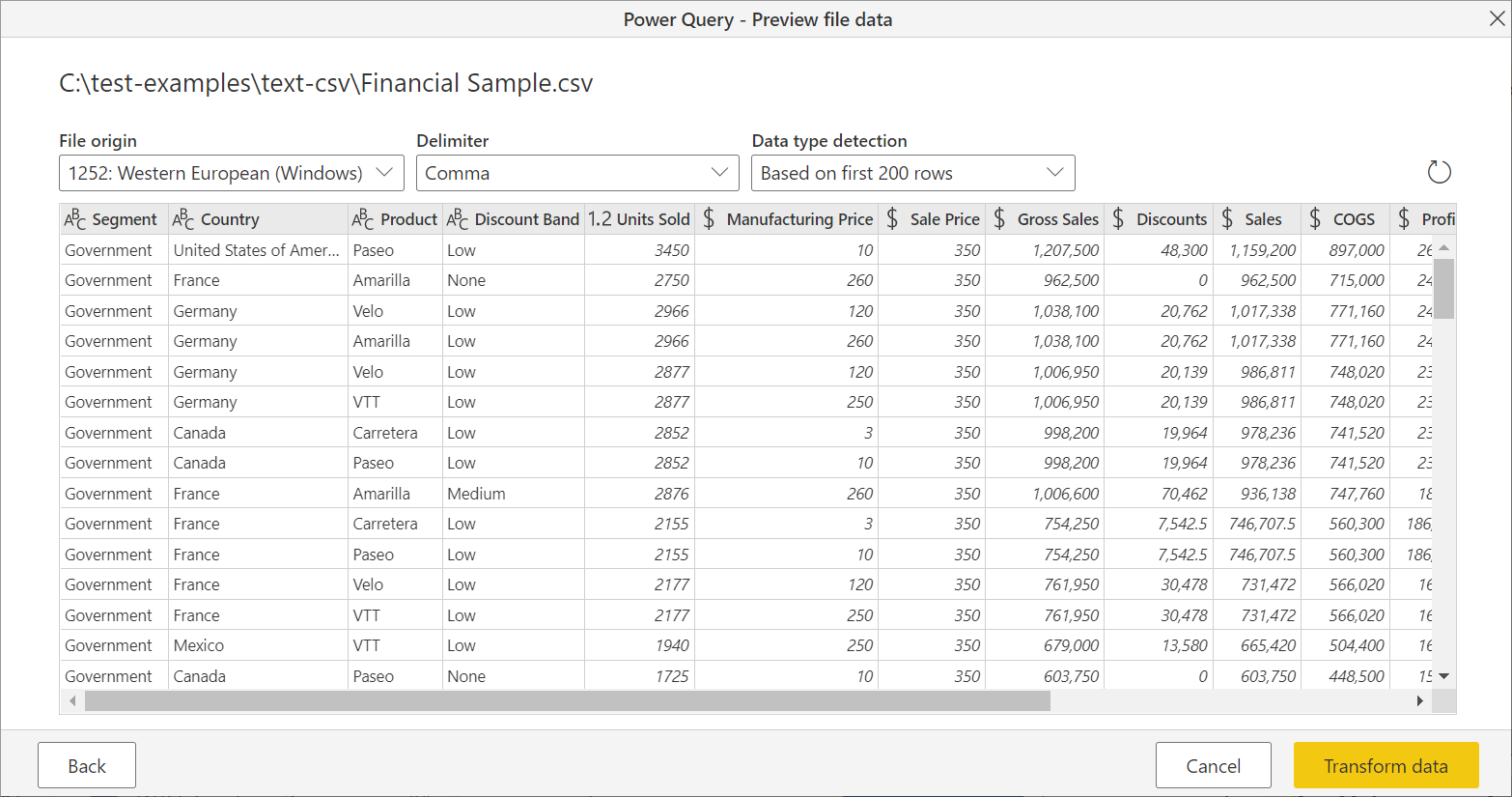
在 导航器中,选择“ 转换数据 ”以开始在 Power Query 编辑器中转换数据。

从网页加载
若要从 Web 加载文本或 CSV 文件,请选择 Web 连接器,输入文件的 Web 地址,并按照任何凭据提示进行作。
文本/CSV 分隔符
Power Query 将 CSV 视为带逗号的结构化文件,这是文本文件的特殊情况。 如果选择文本文件,Power Query 会自动尝试确定它是否具有分隔符分隔值,以及该分隔符是什么。 如果它可以推断分隔符,它会自动将其视为结构化数据源。
非结构化文本
如果您的文本文件没有结构,将导致生成一个单列,每行的新行被编码成为源文本中的一行。 作为非结构化文本的示例,可以考虑包含以下内容的记事本文件:
Hello world.
This is sample data.
加载时,会显示一个导航屏幕,其中每一行都加载到自己的行中。

在此对话框中只能配置一项内容,即“ 文件源 ”下拉列表。 通过此下拉列表,可以选择用于生成文件的 字符集 。 目前,不会推断字符集,仅当 以 UTF-8 BOM 开头时才会推断为 UTF-8。
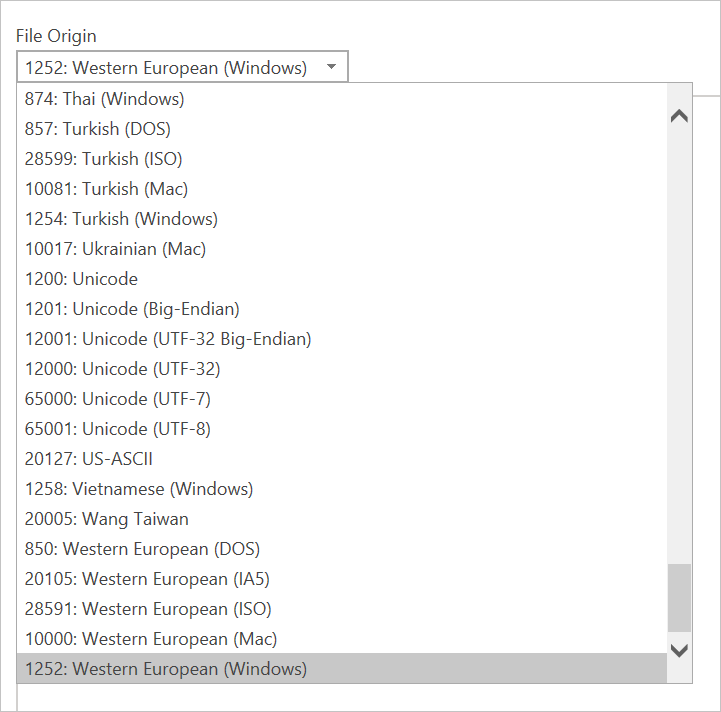
CSV
可 在此处找到示例 CSV 文件。
除了文件源,CSV 还支持指定分隔符以及如何处理数据类型检测。

可用的分隔符包括冒号、逗号、等号、分号、空格、制表符、自定义分隔符(可以是任意字符串)和固定宽度(按某些标准字符数拆分文本)。
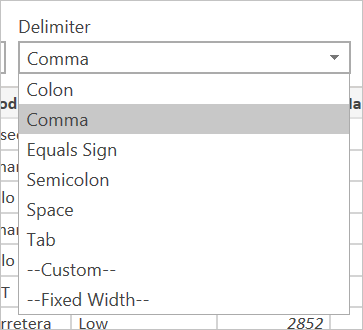
最后一个下拉列表允许你选择如何处理数据类型检测。 它可以基于前 200 行或整个数据集来完成。 此外,可以选择不执行自动数据类型检测,而是让所有列默认为“Text”。 警告:如果在整个数据集上执行此作,可能会导致编辑器中数据的初始加载速度变慢。

由于推理可能不正确,因此在加载之前需要仔细检查设置。
结构化文本
当 Power Query 可以检测文本文件的结构时,它将文本文件视为分隔符分隔值文件,并在打开 CSV 时提供相同的选项,这实质上是一个扩展名指示分隔符类型的文件。
例如,如果将以下示例保存为文本文件,它将读取为具有制表符分隔符而不是非结构化文本。
Column 1 Column 2 Column 3
This is a string. 1 ABC123
This is also a string. 2 DEF456

此结构可用于任何类型的基于分隔符的文件。
编辑源
在编辑源步骤时(在 Power Query Desktop 的 “已应用步骤” 窗格中),会出现一个与最初加载时稍有不同的对话框。 根据你当前将文件视为(即文本或 csv)的内容,你会看到带有各种下拉列表的屏幕。
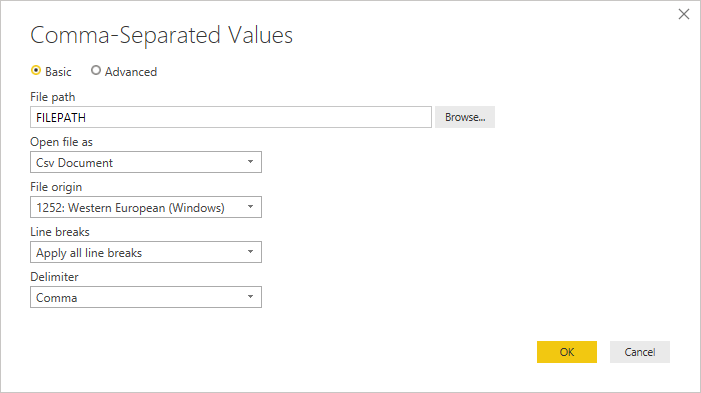
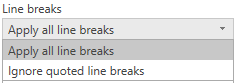
通过“ 换行符 ”下拉列表,可以选择是否要应用引号内的换行符。
例如,如果您编辑先前提供的“结构化”示例,您可以添加一个换行符。
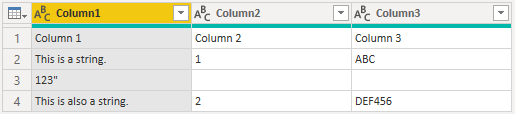
Column 1 Column 2 Column 3
This is a string. 1 "ABC
123"
This is also a string. 2 "DEF456"
如果 换行符 设置为 “忽略带引号的换行符”,则此示例将加载同一列中前半部分中字符串的下半部分。

如果 换行符 设置为 应用所有换行符,则此示例将加载一额外的一行,其内容是换行符后的唯一内容(确切输出可能取决于文件内容的结构)。
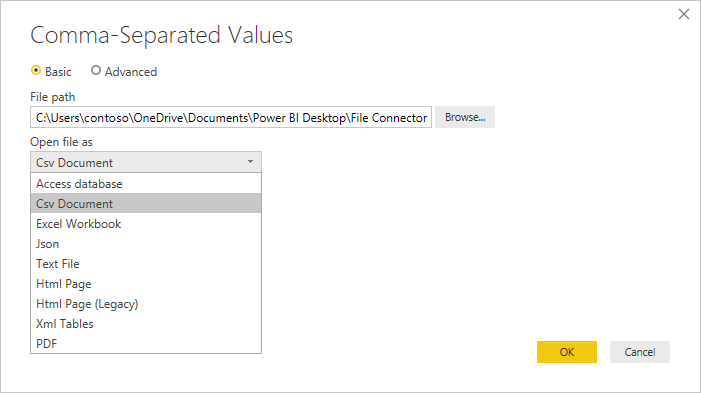
使用 “打开文件” 下拉列表,可以编辑要加载文件的内容,这一点对于故障排除非常重要。 对于技术上不是 CSV 的结构化文件(如保存为文本文件的制表符分隔值文件),仍应将 “打开”文件 设置为 CSV。 此设置还确定对话的其余部分提供了哪些下拉列表。
文本/CSV(按示例)
Power Query 中的文本/CSV 示例法是 Power BI Desktop 和 Power Query Online 中已普遍推出的功能。 您在使用文本/CSV 连接器时,会在导航器的左下角看到一个名为使用示例提取表的选项。
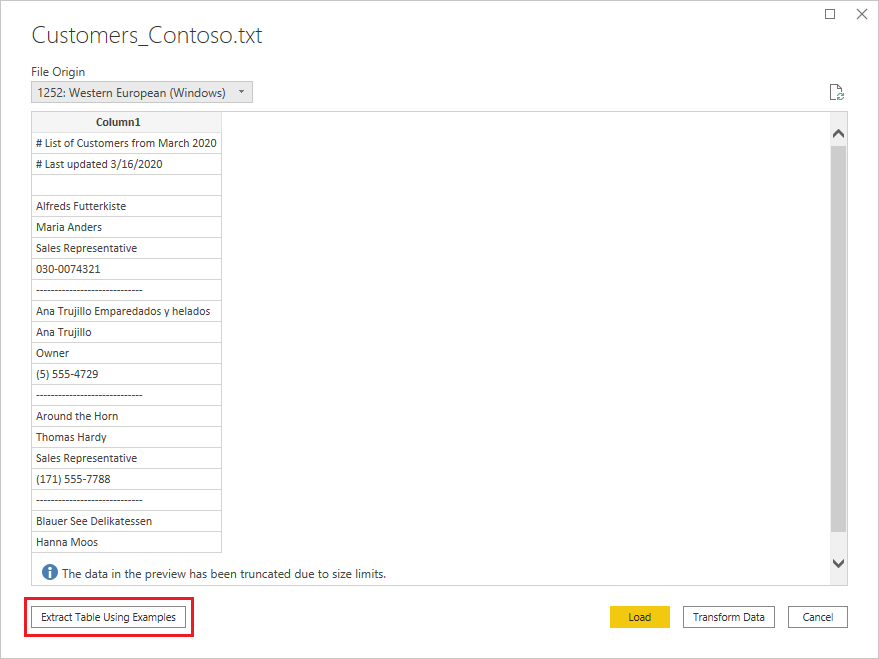
选择该按钮时,将进入“使用示例提取表”页。 在此页上,为要从 Text/CSV 文件中提取的数据指定示例输出值。 输入列的第一个单元格后,列中的其他单元格将填写。若要正确提取数据,可能需要在列中输入多个单元格。 如果列中的某些单元格不正确,可以修复第一个不正确的单元格,并再次提取数据。 若要确保成功提取的数据,请检查前几个单元格中的数据。
注释
建议按列顺序输入示例。 成功填写列后,创建一个新列并开始在新列中输入示例。

构造该表后,可以选择加载或转换数据。 请注意,生成的查询如何包含为数据提取推断的所有步骤的详细细目。 这些步骤是可以根据需要自定义的常规查询步骤。

故障排除
从 Web 加载文件
如果您正在通过Web请求文本/CSV文件,并处理标头,同时检索足够多的文件以需要考虑潜在的限速问题,那么应考虑使用Web.Contents来包装Binary.Buffer()调用。 在这种情况下,在推广标头之前缓存文件会导致文件仅请求一次。
使用大型 CSV 文件进行处理
如果在 Power Query Online 编辑器中处理大型 CSV 文件,可能会收到内部错误。 建议先使用较小的 CSV 文件,应用编辑器中的步骤,完成后,将路径更改为更大的 CSV 文件。 此方法使你能够更高效地工作,并减少在联机编辑器中遇到超时的可能性。 在刷新时间期间,我们不预计您会遇到此错误,因为我们设置了较长的超时期限。
将非结构化文本解释为结构化文件
在极少数情况下,在段落中具有类似逗号的文档可能会被解释为 CSV。 如果发生此问题,请在 Power Query 编辑器中编辑“源”步骤,然后在“打开文件作为”下拉列表中选择“文本”而不是 CSV。
Power BI Desktop 中的列
导入 CSV 文件时,Power BI Desktop 会在 Power Query 编辑器中生成 列=x (其中 x 是初始导入期间 CSV 文件中的列数)作为步骤。 如果以后添加更多列,并且数据源设置为刷新,则不会刷新超出初始 x 列计数的任何列。
错误:连接被主机关闭
从 Web 源加载文本/CSV 文件并提升标头时,有时可能会遇到以下错误: "An existing connection was forcibly closed by the remote host" 或者 "Received an unexpected EOF or 0 bytes from the transport stream." 主机可能会通过采用保护措施并关闭可能暂时暂停的连接(例如,等待其他数据源连接进行联接或追加作时)来导致这些错误。 若要解决这些错误,请尝试添加 Binary.Buffer (建议)或 Table.Buffer 调用,该调用会下载文件,将其加载到内存中,并立即关闭连接。 此作应在下载过程中阻止任何暂停,并防止主机在检索内容之前强行关闭连接。
以下示例演示了此解决方法。 在将生成的表传递给 Table.PromoteHeaders 之前,需要完成此缓冲。
- 原始内容:
Csv.Document(Web.Contents("https://.../MyFile.csv"))
- 使用
Binary.Buffer:
Csv.Document(Binary.Buffer(Web.Contents("https://.../MyFile.csv")))
- 使用
Table.Buffer:
Table.Buffer(Csv.Document(Web.Contents("https://.../MyFile.csv")))