根据数据源,有关数据类型和列名的信息可能或可能不会显式提供。 OData REST API 通常使用 $metadata定义来处理此问题,Power Query OData.Feed 方法会自动处理分析此信息并将其应用于从 OData 源返回的数据。
许多 REST API 无法以编程方式确定其架构。 在这些情况下,需要在连接器中包含架构定义。
简单的硬编码方法
最简单的方法是将架构定义硬编码到连接器中。 这足以用于大多数用例。
总的来说,对连接器返回的数据强制实施架构具有多种优势,例如:
- 设置正确的数据类型。
- 删除不需要向最终用户显示的列(例如内部 ID 或状态信息)。
- 通过添加响应中可能缺少的任何列(REST API 通常通过省略字段来指示字段应为 null),确保每个数据页具有相同的形状。
使用 Table.Schema 查看现有架构
请考虑以下代码,该代码从 TripPin OData 示例服务返回一个简单的表:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
asTable
注释
TripPin 是一个 OData 源,因此,只需使用 OData.Feed 函数的自动架构处理就更有意义了。 在此示例中,你将将源视为典型的 REST API,并用于 Web.Contents 演示手动硬编码架构的技术。
此表是结果:
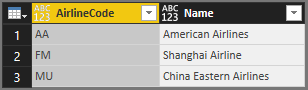
可以使用方便 Table.Schema 的函数检查列的数据类型:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
Table.Schema(asTable)

AirlineCode 和 Name 都是 any 类型。
Table.Schema 返回有关表中列的大量元数据,包括名称、位置、类型信息和许多高级属性,例如 Precision、Scale 和 MaxLength。 现在,你只应该关注所写类型(TypeName)、基元类型(Kind)以及列值是否为 null(IsNullable)。
定义简单架构表
架构表由两列组成:
| 列 | 详细信息 |
|---|---|
| Name | 列的名称。 这必须与服务返回的结果中的名称匹配。 |
| 类型 | 要设置的 M 数据类型。 这可以是基元类型(文本、数字、日期/时间等),也可以是已订阅的类型(Int64.Type、Currency.Type 等)。 |
硬编码的Airlines表的架构表将把AirlineCode和Name列设置为text,其结构如下所示:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})
查看其他一些终结点时,请考虑以下架构表:
此 Airports 表有四个字段您可能需要保留,(其中包括一个类型为 record 的字段):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})
该 People 个表包含七个字段,包括 lists(Emails、AddressInfo),一个 可为空值的 列(Gender),以及一个 特定类型的 列(Concurrency):
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
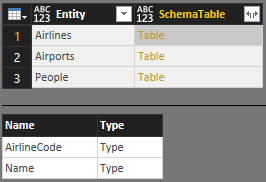
可以将所有这些表放入单个主架构表中 SchemaTable:
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", Airlines},
{"Airports", Airports},
{"People", People}
})
SchemaTransformTable 辅助函数
SchemaTransformTable下面介绍的帮助程序函数将用于对数据强制实施架构。 它采用以下参数:
| 参数 | 类型 | Description |
|---|---|---|
| 表 | 表 | 要在其中强制实施架构的数据表。 |
| 架构 | 表 | 要从中读取列信息的架构表,类型如下: type table [Name = text, Type = type] |
| enforceSchema | 数字 | (可选)控制函数行为的枚举。 默认值 ( EnforceSchema.Strict = 1) 可确保输出表与通过添加任何缺失列和删除额外列提供的架构表匹配。 该 EnforceSchema.IgnoreExtraColumns = 2 选项可用于保留结果中的额外列。 使用时 EnforceSchema.IgnoreMissingColumns = 3 ,将忽略缺少的列和额外的列。 |
此函数的逻辑如下所示:
- 确定源表中是否存在任何缺失的列。
- 确定是否有任何额外的列。
- 忽略结构化列(类型
listrecord,和table),并将列设置为类型any。 - 使用
Table.TransformColumnTypes设置每个列类型。 - 根据在架构表中显示的顺序重新排序列。
- 使用
Value.ReplaceType. 设置表本身上的类型。
注释
在查询编辑器中查看结果时,设置表类型的最后一步将消除 Power Query UI 推断类型信息的需求,这有时可能会导致对 API 进行双重调用。
汇总
在更大的完整扩展上下文中,当从 API 返回表时,会进行架构处理。 通常,此功能发生在分页功能的最低级别(如果存在的话),其中实体信息通过导航表传递。
由于分页和导航表的大部分实现都是特定于上下文的,因此不会在此处显示实现硬编码架构处理机制的完整示例。 此 TripPin 示例 演示端到端解决方案的外观。
精密方法
上面讨论的硬编码实现可以很好地确保架构对于简单的 JSON 响应保持一致,但仅限于分析第一级别的响应。 深度嵌套数据集将受益于以下方法,该方法利用 M 类型。
下面是 M 语言在语言规范中的类型的快速回顾:
类型值是一个对其他值进行分类的值 。 认为按类型分类的值符合该类型。 M 类型系统由以下类型组成:
- 原始类型用于对原始值(
binary、date、datetime、datetimezone、duration、list、logical、null、number、record、text、time、type)进行分类,并且还包括一些抽象类型(function、table、any和none)。- 记录类型,根据字段名称和值类型对记录值进行分类。
- 列表类型,使用单个项基类型对列表进行分类。
- 函数类型,根据函数值的参数类型和返回值的类型对函数值进行分类。
- 表类型,根据列名、列类型和键对表值进行分类。
- 可以为 null 的类型,除基类型分类的所有值外,还对值 null 进行分类。
- 类型类型,用于对属于类型的值进行分类。
使用获取的原始 JSON 输出(以及/或通过查找 服务$metadata中的定义),可以定义以下记录类型来表示 OData 复杂类型:
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
请注意如何 LocationType 引用 CityType 和 LocType 表示其结构化列。
对于要表示为表的顶级实体,可以定义 表类型:
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency Int64.Type
];
然后,可以更新 SchemaTable 变量(可用于实体到类型映射的查阅表),以使用这些新类型定义:
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType},
{"Airports", AirportsType},
{"People", PeopleType}
});
可以依赖通用函数(Table.ChangeType)为数据强加一个架构,就像你在前面的练习中使用SchemaTransformTable那样。 与SchemaTransformTable不同,Table.ChangeType以实际的 M 表类型作为参数,并为所有嵌套类型递归应用您的架构。 其签名为:
Table.ChangeType = (table, tableType as type) as nullable table => ...
注释
为提高灵活性,函数可用于表和记录列表(即如何在 JSON 文档中表示表)。
然后,需要更新连接器代码,将schema参数从table更改为type,并添加一个对Table.ChangeType的调用。 同样,此类细节与具体实现密切相关,因此在此不值得详细讨论。
此扩展的 TripPin 连接器示例 演示了一个端到端解决方案,该解决方案实现此更复杂的处理架构方法。