本文为查询折叠的三个可能结果中的每一个提供了一些示例方案。 它还包括有关如何充分利用查询折叠机制以及它在查询中可能具有的效果的一些建议。
情景
假设使用 适用于 Azure Synapse Analytics SQL 数据库的 Wide World Importers 数据库,你将负责在 Power Query 中创建一个连接到 fact_Sale 表的查询,并仅检索具有以下字段的最后 10 个销售额:
- 销售密钥
- 客户密钥
- 发票日期密钥
- Description
- 数量
注释
出于演示目的,本文使用本教程中概述的数据库,介绍如何将 Wide World Importers 数据库加载到 Azure Synapse Analytics 中。 本文的主要区别是 fact_Sale 表仅保存 2000 年的数据,总共 3,644,356 行。
虽然结果可能不会与按照 Azure Synapse Analytics 文档中的教程获得的结果完全一致,但本文的目标是展示查询折叠在您的查询中可能产生的核心概念和影响。

本文展示了使用不同级别的查询折叠实现相同输出的三种方法:
- 无查询折叠
- 部分查询折叠
- 完整查询折叠
无查询折叠示例
重要
仅依赖于非结构化数据源或没有计算引擎(如 CSV 或 Excel 文件)的查询没有查询折叠功能。 这意味着 Power Query 使用 Power Query 引擎评估所有必需的数据转换。
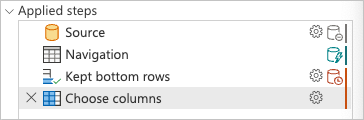
连接到数据库并导航到fact_Sale表后,选择“开始”选项卡的“减少行”组中的“保留底部行”转换。
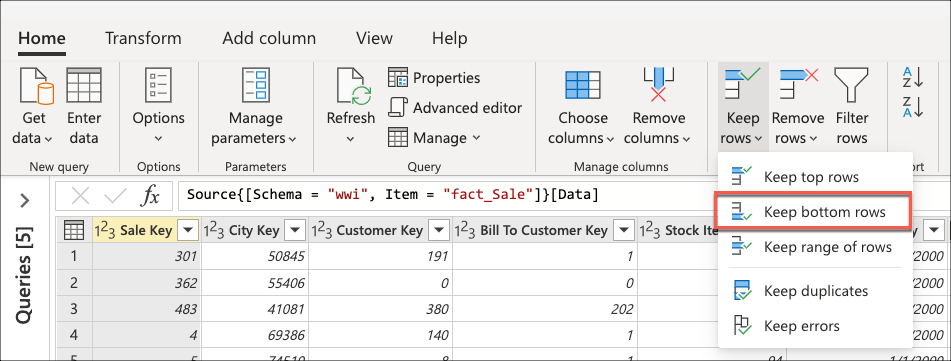
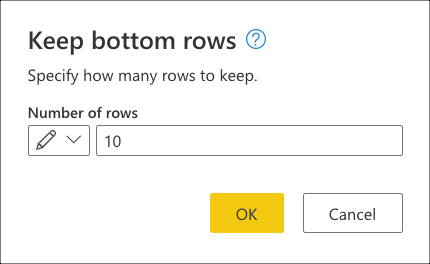
选择此转换后,将显示一个新对话框。 在此新对话框中,可以输入要保留的行数。 对于这种情况,请输入值 10,然后选择“ 确定”。
小窍门
对于这种情况,执行此操作将得出最近 10 次销售的结果。 在大多数情况下,我们建议你提供一个更明确的逻辑,该逻辑定义哪些行被视为最后的,方法是对表应用排序操作。
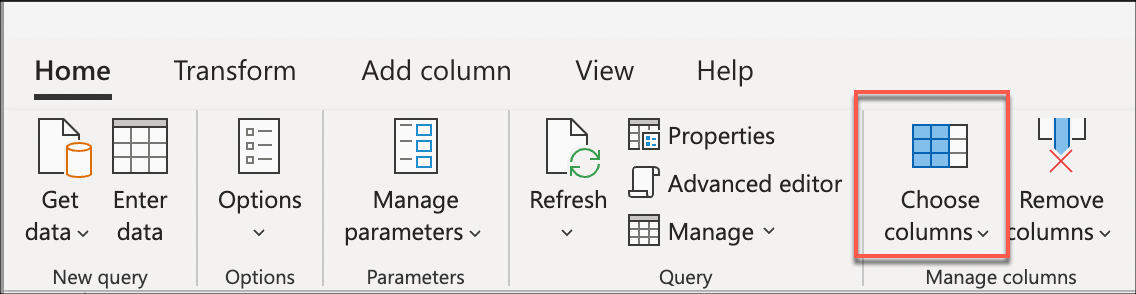
接下来,选择“选择列”转换,此转换位于“管理列”组中的“开始”选项卡下。然后,您可以选择要在表中保留的列并删除其余的列。
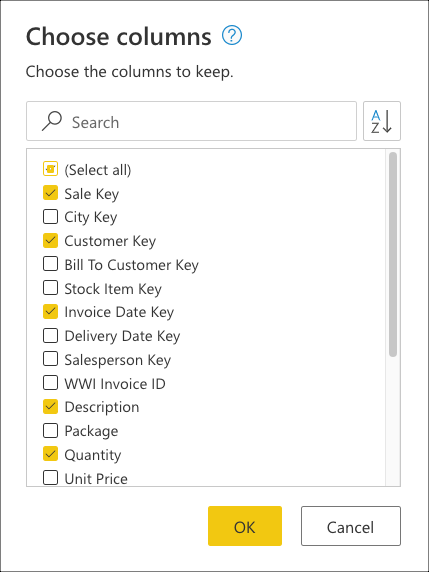
最后,在选择列对话框中,选择Sale Key、Customer Key、Invoice Date Key、Description和Quantity列,然后选择确定。
以下代码示例是所创建的查询的完整 M 脚本:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(
#"Kept bottom rows",
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
)
in
#"Choose columns""
无查询折叠:了解查询评估
在 Power Query 编辑器中的 已应用步骤 下,请注意,保留底部行和选择列 的查询折叠指示器被标记为在数据源外部评估的步骤,或者换句话说,是由 Power Query 引擎评估的步骤。
可以右键单击查询的最后一步,即名为“选择列”的步骤,然后选择“查看查询计划”选项。 查询计划的目标是提供查询运行方式的详细视图。 若要了解有关此功能的详细信息,请转到 查询计划。

上一个映像中的每个框称为 节点。 节点表示用于执行此查询的操作分解。 表示数据源的节点,如上一示例中的 SQL Server 和 Value.NativeQuery 节点,表示将查询的哪个部分卸载到数据源。 在本例中,Power Query 引擎评估其余节点,即上图矩形中突出显示的 Table.LastN 和 Table.SelectColumns。 这两个节点表示添加的两个转换: “保留底部行 ”和 “选择列”。 其余节点表示在数据源级别发生的操作。
若要查看发送到数据源的确切请求,请选择节点中的Value.NativeQuery”。

此数据源请求采用数据源的本机语言。 在这种情况下,该语言为 SQL,此语句表示对表中所有行和字段 fact_Sale 的请求。
咨询此数据源请求可帮助你更好地了解查询计划尝试传达的故事:
-
Sql.Database:此节点表示数据源访问权限。 连接到数据库并发送元数据请求以了解其功能。 -
Value.NativeQuery:表示 Power Query 为完成查询而生成的请求。 Power Query 将本机 SQL 语句中的数据请求提交到数据源。 在这种情况下,表示来自fact_Sale表的所有记录和字段(列)。 对于此方案,这种情况是不可取的,因为该表包含数百万行,并且兴趣仅在最后 10 行中。 -
Table.LastN:Power Query 从fact_Sale表中接收所有记录后,它使用 Power Query 引擎筛选表,并仅保留最后 10 行。 -
Table.SelectColumns:Power Query 使用Table.LastN节点的输出,并应用一个名为Table.SelectColumns的新转换,该转换选择要从表中保留的特定列。
为了进行评估,此查询必须从 fact_Sale 表中下载所有行和字段。 此查询在 Power BI 数据流的标准实例中平均处理了 6 分钟和 1 秒(这考虑到了数据流的计算和加载)。
部分查询折叠示例
连接到数据库并导航到 fact_Sale 表后,首先选择要从表中保留的列。 在“开始”选项卡的“管理列”组中,选择“选择列”转换。此转换功能可以帮助您明确选择要在表中保留的列,并删除其他列。
在主页功能区中选择“选择列转换”以进行部分查询折叠示例的屏幕截图。
在选择列对话框中,选择Sale Key、Customer Key、Invoice Date Key、Description和Quantity列,然后选择确定。
现在,您可以创建一个逻辑来对表进行排序,以便将最新的销售记录置于表格的底部。 选择列 Sale Key ,该列是表的主键和增量序列或索引。 仅使用该字段,通过列的上下文菜单,以升序对表进行排序。
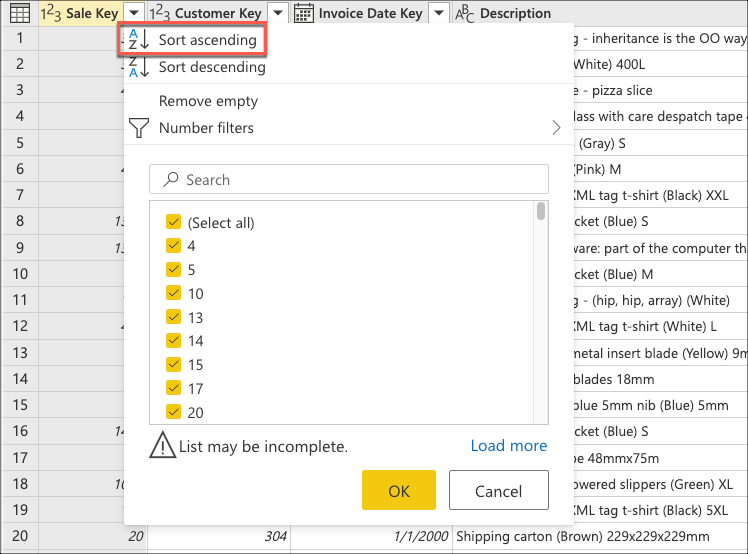
接下来,选择表上下文菜单,然后选择 “保留底部行 ”转换。
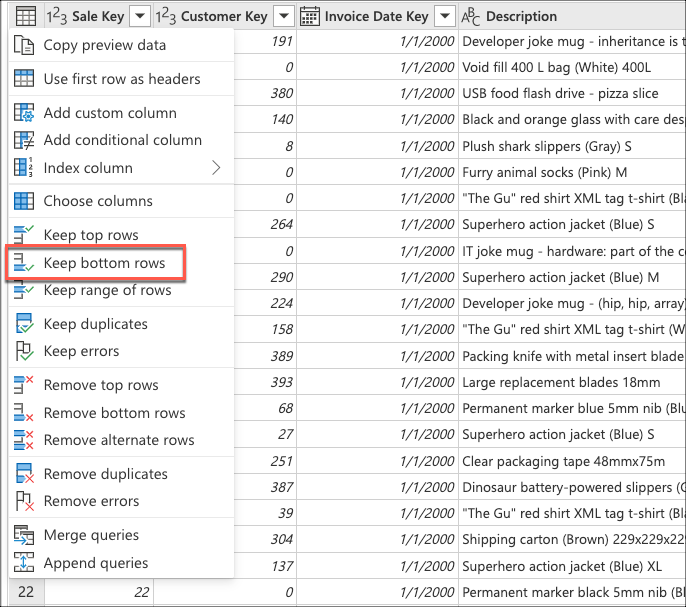
在 “保留底部行”中,输入值 10,然后选择“ 确定”。
以下代码示例是所创建的查询的完整 M 脚本:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
部分查询折叠示例:了解查询评估
检查已应用的步骤窗格时,你会注意到查询折叠指示器显示,你添加的最后一个转换 Kept bottom rows 被标记为由 Power Query 引擎在数据源外部评估的步骤。
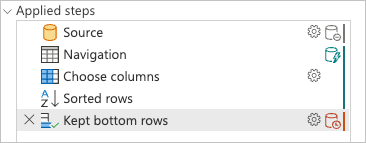
可以右键单击查询的最后一步(名为 Kept bottom rows查询)并选择 “查询计划 ”选项,以更好地了解查询的评估方式。

上一个映像中的每个框称为 节点。 节点表示需要从左到右执行的每个过程,以便于评估您的查询。 其中一些节点可以在数据源中进行评估,而其他节点(如“Table.LastN步骤所表示的节点)则使用 Power Query 引擎进行评估。
若要查看发送到数据源的确切请求,请选择节点中的Value.NativeQuery”。

此请求采用数据源的本机语言。 对于这种情况,该语言是 SQL,该语句表示请求 fact_Sale 表中的所有行,并仅选择请求的字段,然后按照 Sale Key 字段进行排序。
咨询此数据源请求可帮助你更好地了解完整查询计划尝试传达的故事。 节点的顺序是从从数据源请求数据开始的一个顺序过程:
-
Sql.Database:连接到数据库并发送元数据请求以了解其功能。 -
Value.NativeQuery:表示 Power Query 生成的用于完成查询的请求。 Power Query 将本机 SQL 语句中的数据请求提交到数据源。 对于这种情况,表示所有记录,其中仅包含数据库中表fact_Sale的请求字段,并按Sales Key字段升序排序。 -
Table.LastN:Power Query 从fact_Sale表中接收所有记录后,它使用 Power Query 引擎筛选表,并仅保留最后 10 行。
为了进行评估,此查询必须下载所有行,并且只下载表中的必填字段 fact_Sale 。 在 Power BI 数据流的标准实例中,平均需要 3 分 4 秒(这考虑到了数据流的评估和加载)。
完整查询折叠示例
连接到数据库并导航到 fact_Sale 表后,首先选择要从表中保留的列。 在“开始”选项卡的“管理列”组中,选择“选择列”转换。此转换功能可以帮助您明确选择要在表中保留的列,并删除其他列。
在选择列中,选择Sale Key、Customer Key、Invoice Date Key、Description和Quantity列,然后选择确定。
现在,您可以创建逻辑来对表进行排序,以便在表的顶部展示最近的销售记录。 选择列 Sale Key ,该列是表的主键和增量序列或索引。 从列的上下文菜单中仅使用此字段以降序对表格进行排序。
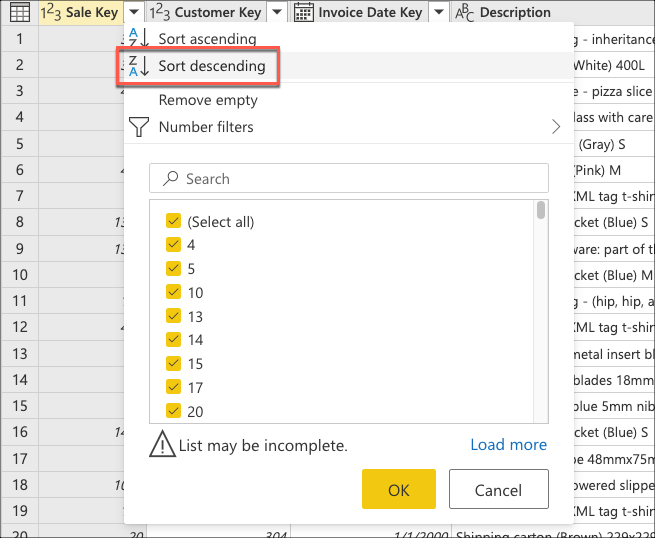
接下来,选择表上下文菜单,然后选择 “保留顶部行 ”转换。
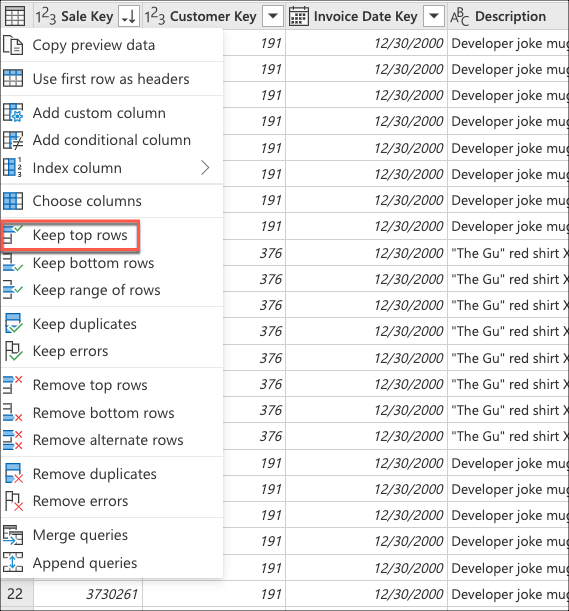
在 “保留前几行”中,输入值 10,然后选择“ 确定”。
以下代码示例是所创建的查询的完整 M 脚本:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
完整查询折叠示例:了解查询评估
检查已应用的步骤窗格时,请注意,查询折叠指示器显示您添加的转换,选择列、排序的行和保留前几行,已被标记为在数据源中评估的步骤。

可以右键单击查询的最后一步,即名为 “保留前几行”的查询,然后选择读取 查询计划的选项。

此请求采用数据源的本机语言。 在这种情况下,该语言为 SQL,此语句表示对表中所有行和字段 fact_Sale 的请求。
咨询此数据源查询可帮助你更好地了解完整查询计划尝试传达的故事:
-
Sql.Database:连接到数据库并发送元数据请求以了解其功能。 -
Value.NativeQuery:表示 Power Query 生成的用于完成查询的请求。 Power Query 将本机 SQL 语句中的数据请求提交到数据源。 对于这种情况,这表示请求只获取表fact_Sale的前 10 条记录,并且在使用字段Sale Key按降序排序后,只返回所需的字段。
注释
虽然没有可用于在 T-SQL 语言中选择表的底部行的子句,但有一个 TOP 子句可以检索表的顶部行。
在评估时,此查询仅从 fact_Sale 表中下载您请求的字段,并且仅限于 10 行。 此查询在 Power BI 数据流的标准实例中平均需要 31 秒(这考虑到了数据流的计算和加载)。
性能比较
为了更好地了解查询折叠在这些查询中的效果,可以刷新查询,记录完全刷新每个查询所需的时间,并对其进行比较。 为简单起见,本文提供了使用 Power BI 数据流刷新机制捕获的平均刷新计时,同时将 DW2000c 作为服务级别连接到专用的 Azure Synapse Analytics 环境。
每个查询的刷新时间如下所示:
| Example | 标签 | 时间 (秒) |
|---|---|---|
| 无查询折叠 | None | 361 |
| 部分查询折叠 | 部分的 | 184 |
| 完整查询折叠 | 完整 | 31 |
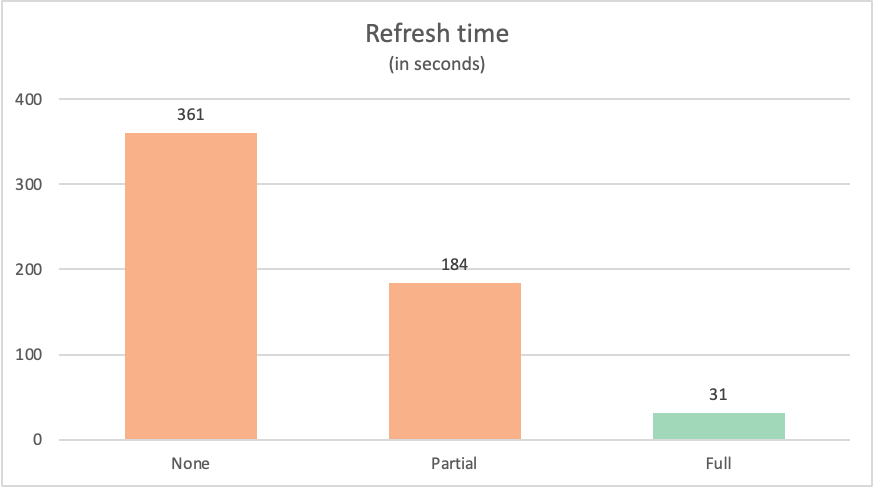
通常,完全折叠回数据源的查询优于不完全折叠回数据源的类似查询。 原因可能有很多。 这些原因包括查询执行的转换的复杂性,以及数据源中实现的查询优化,例如索引、专用计算和网络资源。 不过,查询折叠试图利用两个特定的关键过程来最大程度地减少这两个过程对 Power Query 的影响。
- 传输中的数据
- Power Query 引擎执行的转换
以下各节说明了这两个进程在前面提到的查询中的效果。
传输中的数据
执行查询时,它会尝试从数据源中提取数据作为其第一个步骤之一。 从数据源提取的数据由查询折叠机制定义。 此机制识别出查询中可以卸载到数据源的步骤。
下表列出了从 fact_Sale 数据库表请求的行数。 该表还包括对 SQL 语句的简要说明,该语句用于向数据源请求此类数据。
| Example | 标签 | 请求的行 | Description |
|---|---|---|---|
| 无查询折叠 | None | 3644356 | 获取fact_Sale表中的所有字段和所有记录 |
| 部分查询折叠 | 部分的 | 3644356 | 请求所有记录,但在按字段排序fact_Sale后仅请求Sale Key表中的必填字段 |
| 完整查询折叠 | 完整 | 10 | 仅请求必需的字段,并在按字段fact_Sale降序排序后,获取表Sale Key的前10条记录。 |
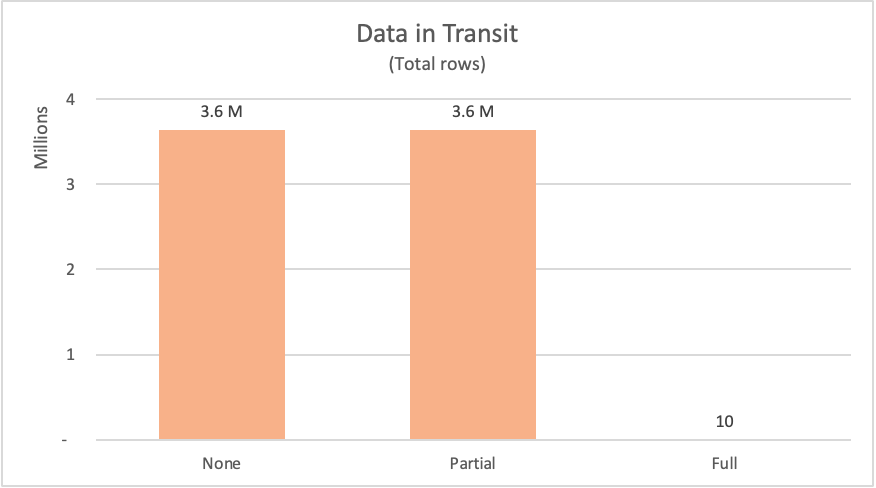
从数据源请求数据时,数据源需要计算请求的结果,然后将数据发送到请求者。 虽然已经提到计算资源,但将数据从数据源移动到 Power Query 的网络资源,然后让 Power Query 能够有效地接收数据,并为本地发生的转换做好准备可能需要一些时间,具体取决于数据的大小。
对于展示的示例,Power Query 必须从数据源请求超过 360 万行,以获取无查询折叠和部分查询折叠示例。 对于完整的查询折叠示例,它只请求了 10 行。 对于请求的字段,未启用查询折叠的示例请求了表中的所有可用字段。 部分查询折叠和完整查询折叠的示例仅提交了对确切所需字段的请求。
注意
我们建议您实现增量刷新解决方案,使用查询折叠技术来处理包含大量数据的查询或表。 Power Query 的不同产品集成实现超时以终止长时间运行的查询。 某些数据源会在长时间运行的会话上实现超时,并尝试对其服务器执行消耗资源的查询。 详细信息: 对数据流使用增量刷新 和 语义模型的增量刷新
Power Query 引擎执行的转换
本文展示了如何使用 查询计划 更好地了解查询的评估方式。 在查询计划中,你可以看到由 Power Query 引擎执行的转换操作的确切节点。
下表展示了由 Power Query 引擎评估的先前查询的查询计划中的节点。
| Example | 标签 | Power Query 引擎转换节点 |
|---|---|---|
| 无查询折叠 | None |
Table.LastN、Table.SelectColumns |
| 部分查询折叠 | 部分的 | Table.LastN |
| 完整查询折叠 | 完整 | — |
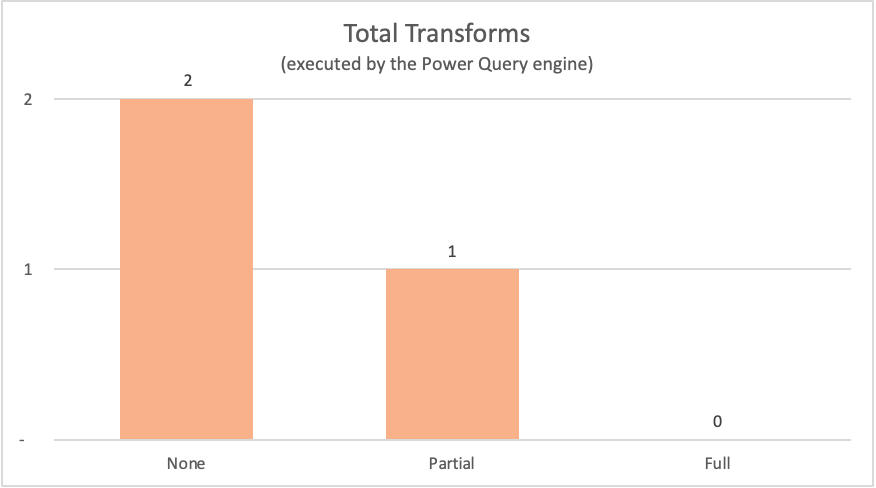
对于本文中展示的示例,完整的查询折叠示例不需要在 Power Query 引擎中进行任何转换,因为所需的输出表直接来自数据源。 相比之下,其他两个查询要求在 Power Query 引擎中进行一些计算。 由于这两个查询需要处理的数据量,因此这些示例的过程比完整查询折叠示例花费的时间要长。
转换可以分为以下几类:
| 运算符的类型 | Description |
|---|---|
| 远程 | 数据源节点的运算符。 这些运算符的评估发生在 Power Query 之外。 |
| 流式处理 | 运算符是透传运算符。 例如,Table.SelectRows 使用简单的筛选器通常可以在结果通过运算符时直接进行筛选,而不需要在移动数据之前先收集所有行。
Table.SelectColumns 以及 Table.ReorderColumns 此类运算符的其他示例。 |
| 完全扫描 | 需要收集所有行的运算符,然后数据才能继续移动到链中的下一个运算符。 例如,若要对数据进行排序,Power Query 需要收集所有数据。 完整扫描运算符的其他示例包括 Table.Group, Table.NestedJoin以及 Table.Pivot。 |
小窍门
虽然从性能的角度来看,并非每个转换都是相同的,但在大多数情况下,转换较少通常更好。
注意事项和建议
- 请按照Power Query 中的最佳做法,在创建新查询时遵循这些准则。
- 使用 查询折叠指示器 检查哪些步骤阻止查询折叠。 如有必要,请对它们重新排序以增加折叠。
- 使用查询执行计划来确定在特定步骤中 Power Query 引擎所发生的转换。 请考虑通过重新排列步骤来调整您的现有查询。 然后再次检查查询的最后一步的查询计划,并查看查询计划是否比上一步好。 例如,新查询计划的节点数比上一个节点少,大多数节点是“流式处理”节点,而不是“完全扫描”。 对于支持折叠的数据源,查询计划中除了
Value.NativeQuery和数据源访问节点之外的任何节点都表示未折叠的转换。 - 如果可用,可以使用 查看本机查询 (或 查看数据源查询)选项来确保可以将查询折叠回数据源。 如果为步骤禁用了此选项,并且你使用的源通常启用了此功能,那么你就创建了一个停止查询折叠功能的步骤。 如果使用不支持此选项的源,则可以依赖于查询折叠指示器和查询计划。
- 使用查询诊断工具,当连接器支持查询折叠功能时,可以更好地了解发送到数据源的请求。
- 组合使用多个连接器的数据源时,Power Query 会尝试尽可能多地将工作推送到两个数据源,同时符合为每个数据源定义的隐私级别。
- 阅读有关 隐私级别的 文章,以保护查询免受数据隐私防火墙错误的影响。
- 使用其他工具从数据源收到的请求的角度检查查询折叠。 根据本文中的示例,你可以使用 Microsoft SQL Server Profiler 以检查由 Power Query 发送并由 Microsoft SQL Server 接收的请求。
- 如果将新步骤添加到完全折叠的查询,并且新步骤也会折叠,Power Query 可能会向数据源发送新请求,而不是使用上一个结果的缓存版本。 实际上,此过程可能导致对少量数据执行看似简单的操作在预览中刷新所需的时间比预期要长。 此较长的刷新是由于 Power Query 重新查询数据源,而不是关闭数据的本地副本。