使用文本数据有时可能会麻烦。 例如,城市名称“Redmond”可以使用不同的大小写(“Redmond”、“redmond”和“REDMOND”)在数据库中表示。 这可能会导致在 Power Query 中转换数据时出现问题,因为 Power Query M 公式语言区分大小写。
值得庆幸的是,Power Query M 提供用于清理和规范文本数据事例的函数。 有函数可将文本转换为小写(abc)、大写(ABC)或正确大小写(Abc)。 此外,Power Query M 还提供了几种完全忽略大小写的方法。
本文介绍如何更改文本、列表和表中单词的大小写。 它还介绍了在文本、列表和表中处理数据时忽略大小写的多种方法。 此外,本文还讨论如何根据案例进行排序。
更改文本中的大小写
有三个函数可将文本转换为小写、大写和正确大小写。 函数是 Text.Lower, Text.Upper和 Text.Proper。 以下简单示例演示如何在文本中使用这些函数。
将文本中的所有字符转换为小写
以下示例演示如何将字符串中的所有字符转换为小写。
let
Source = Text.Lower("The quick brown fox jumps over the lazy dog.")
in
Source
此代码生成以下输出:
the quick brown fox jumps over the lazy dog.
将文本中的所有字母转换为大写
以下示例演示如何将文本字符串中的所有字符转换为大写。
let
Source = Text.Upper("The quick brown fox jumps over the lazy dog.")
in
Source
此代码生成以下输出:
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG.
将所有单词转换为首字母大写
下面的示例演示如何将句子中的所有单词转换为初始大写。
let
Source = Text.Proper("The quick brown fox jumps over the lazy dog.")
in
Source
此代码生成以下输出:
The Quick Brown Fox Jumps Over The Lazy Dog.
更改列表中的大小写
在列表中更改大小写时,要使用的最常见函数是 List.Transform。 以下简单示例演示了如何在列表中使用此函数。
将所有项转换为小写
以下示例演示如何将列表中的所有项更改为小写。
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Lower Case" = List.Transform(Source, Text.Lower)
in
#"Lower Case"
此代码生成以下输出:
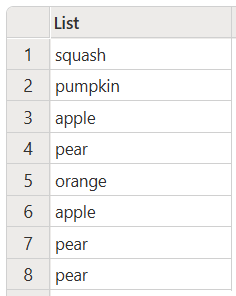
将所有项转换为大写
以下示例演示如何将列表中的所有项更改为大写。
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Upper Case" = List.Transform(Source, Text.Upper)
in
#"Upper Case"
此代码生成以下输出:
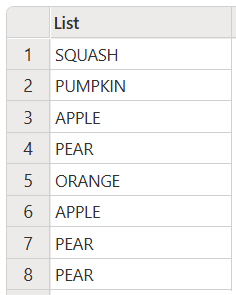
将所有项转换为正确的字母大小写
下面是一个示例,演示如何将列表中的所有项更改为正确的格式。
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Proper Case" = List.Transform(Source, Text.Proper)
in
#"Proper Case"
此代码生成以下输出:
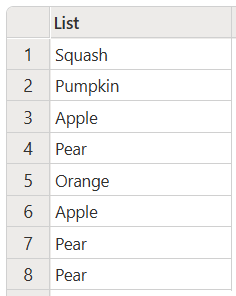
更改表中的事例
在表中更改大小写时,要使用的最常见函数是 Table.TransformColumns。 还有一个函数可用于更改行中包含的文本大小写,称为 Table.TransformRows。 但是,此函数不常使用。
以下简单示例演示了如何使用 Table.TransformColumns 函数来更改表中的情况。
将表格列中的所有项转换为小写
以下示例演示如何将表列中的所有项更改为小写(在本例中为客户名称)。
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Lower Case" = Table.TransformColumns(Source, {"CUSTOMER", Text.Lower})
in
#"Lower Case"
此代码生成以下输出:
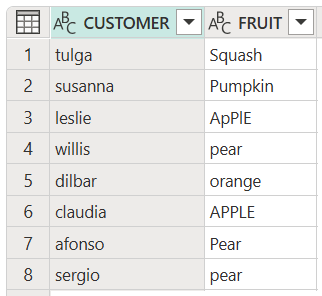
将表格列中的所有项转换为大写
以下示例演示如何将表列中的所有项更改为大写,在本例中,将水果名称更改为大写。
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Upper Case" = Table.TransformColumns(Source, {"FRUIT", Text.Upper})
in
#"Upper Case"
此代码生成以下输出:
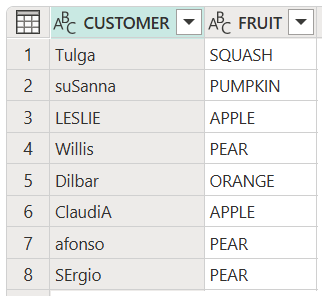
将表中的所有项转换为正确的大小写
以下示例演示如何将这两个表列中的所有项更改为适当的大小写。
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Customer Case" = Table.TransformColumns(Source, {"CUSTOMER", Text.Proper}),
#"Proper Case" = Table.TransformColumns(#"Customer Case", {"FRUIT", Text.Proper})
in
#"Proper Case"
此代码生成以下输出:
忽略大小写
在许多情况下,在搜索或替换项目时,可能需要忽略要查找的项目大小写。 因为 Power Query M 公式语言区分大小写,所以即使项内容相同,但由于大小写不同,比较时也会被识别为不同项,而不是相同项。 忽略大小写的一种方法是,在包含 equationCriteria 参数或 comparer 参数的函数中使用 Comparer.OrdinalIgnoreCase 函数。 忽略事例的另一种方法涉及在包含options参数的函数中使用IgnoreCase选项(如果可用)。
忽略文本中的大小写
在文本中搜索时有时需要忽略大小写,以便找到所有匹配的实例。在测试相等性时,文本函数通常在 comparer 参数中使用 Comparer.OrdinalIgnoreCase 函数来忽略大小写。
以下示例演示如何在确定句子是否包含特定单词时忽略大小写,而不考虑大小写。
let
Source = Text.Contains(
"The rain in spain falls mainly on the plain.",
"Spain",
Comparer.OrdinalIgnoreCase
)
in
Source
此代码生成以下输出:
true
以下示例演示如何检索句子中“the”一词最后一次出现的初始位置,忽略大小写。
let
Source = Text.PositionOf(
"THE RAIN IN SPAIN FALLS MAINLY ON THE PLAIN.",
"the",
Occurrence.Last,
Comparer.OrdinalIgnoreCase
)
in
Source
此代码生成以下输出:
34
忽略列表中的大小写
包含可选 equationCriteria 参数的任何列表函数都可以使用 Comparer.OrdinalIgnoreCase 函数来忽略列表中的大小写。
以下示例检查列表是否包含特定项,同时忽略大小写。 在此示例中, List.Contains 只能比较列表中的一项,不能将列表与列表进行比较。 为此,需要使用 List.ContainsAny。
let
Source = List.Contains(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
"apple",
Comparer.OrdinalIgnoreCase
)
in
Source
此代码生成以下输出:
true
以下示例检查列表是否包含所有在第二个参数(value)中指定的项,同时忽略大小写。 如果列表中不包含任何项(如 cucumber 第二个示例中),该函数将返回 FALSE。
let
Source = List.ContainsAll(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
{"apple", "pear", "squash", "pumpkin"},
Comparer.OrdinalIgnoreCase
)
in
Source
此代码生成以下输出:
true
let
Source = List.ContainsAll(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
{"apple", "pear", "squash", "pumpkin", "cucumber"},
Comparer.OrdinalIgnoreCase
)
in
Source
此代码生成以下输出:
false
以下示例检查列表中的任何一项是否为苹果或梨,同时忽略大小写。
let
Source = List.ContainsAny(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
{"apple","pear"},
Comparer.OrdinalIgnoreCase
)
in
Source
此代码生成以下输出:
true
以下示例仅保留唯一项,同时忽略大小写。
let
Source = List.Distinct(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
Comparer.OrdinalIgnoreCase
)
in
Source
此代码生成以下输出:
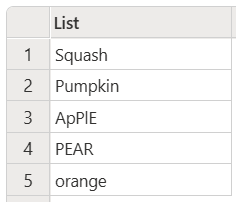
在上一示例中,输出显示列表中找到的第一个唯一项的情况。 因此,虽然有两个苹果(ApPlE 和 APPLE),但只显示第一个示例。
以下示例仅保留唯一项,同时忽略大小写,但也返回所有小写结果。
let
Source = List.Distinct(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
Comparer.OrdinalIgnoreCase
),
#"Lower Case" = List.Transform(Source, Text.Lower)
in
#"Lower Case"
此代码生成以下输出:
忽略表中的事例
表有多种方法可以忽略大小写。 表函数,例如 Table.Contains, Table.Distinct和 Table.PositionOf 所有包含 equationCriteria 参数。 这些参数可以使用 Comparer.OrdinalIgnoreCase 函数在表中忽略大小写,这与上一节中的列表大致相同。 表函数,例如包含condition参数的Table.MatchesAnyRows,还可以使用Comparer.OrdinalIgnoreCase将其包装在其他表函数中来忽略大小写。 其他表函数(特别是用于模糊匹配)可以使用 IgnoreCase 该选项。
以下示例演示如何选择包含单词“pear”的特定行,同时忽略大小写。 此示例使用 condition 的参数Table.SelectRows,并将 Text.Contains 作为条件来进行比较,同时忽略大小写。
let
Source = #table(type table[CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Select Rows" = Table.SelectRows(
Source, each Text.Contains([FRUIT], "pear", Comparer.OrdinalIgnoreCase))
in
#"Select Rows"
此代码生成以下输出:

下面的示例演示如何确定表中的任何行是否包含 pear 列中的 FRUIT 行。 此示例在Comparer.OrdinalIgnoreCase函数condition中使用Text.Contains函数的参数Table.MatchesAnyRows。
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "PEAR"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "peAR"}
}),
#"Select Rows" = Table.MatchesAnyRows(Source,
each Text.Contains([FRUIT], "pear", Comparer.OrdinalIgnoreCase))
in
#"Select Rows"
此代码生成以下输出:
true
以下示例演示如何处理由用户输入的包含他们最喜欢水果的列且没有设定格式的表格。 此列通过模糊匹配提取出最喜爱的水果名称,然后在一个名为Cluster的独立列中显示出来。 然后检查 “聚类” 列,以确定列中的不同水果。 确定唯一水果后,最后一步是将所有水果名称更改为小写。
let
// Load a table of user's favorite fruits into Source
Source = #table(type table [Fruit = text], {{"blueberries"},
{"Blue berries are simply the best"}, {"strawberries"}, {"Strawberries = <3"},
{"Apples"}, {"'sples"}, {"4ppl3s"}, {"Bananas"}, {"fav fruit is bananas"},
{"Banas"}, {"My favorite fruit, by far, is Apples. I simply love them!"}}
),
// Create a Cluster column and fuzzy match the fruits into that column
#"Cluster fuzzy match" = Table.AddFuzzyClusterColumn(
Source, "Fruit", "Cluster",
[IgnoreCase = true, IgnoreSpace = true, Threshold = 0.5]
),
// Find the distinct fruits from the Cluster column
#"Ignore cluster case" = Table.Distinct(
Table.SelectColumns(#"Cluster fuzzy match", "Cluster"),
Comparer.OrdinalIgnoreCase
),
// Set all of the distinct fruit names to lower case
#"Set lower case" = Table.TransformColumns(#"Ignore cluster case",
{"Cluster", Text.Lower}
)
in
#"Set lower case"
此代码生成以下输出:

大小写和排序
列表和表格可以分别使用List.Sort或Table.Sort来排序。 但是,排序文本取决于列表或表中关联项的情况,以确定实际排序顺序(升序或降序)。
排序的最常见形式使用所有小写、全部大写或正确大小写的文本。 如果存在这些情况的组合,升序排序顺序如下所示:
- 以大写字母开头的列表或表列中的任何文本都是第一个。
- 如果有匹配的文本,但一个是首字母大写,另一个是全大写,全大写版本优先。
- 然后对小写进行排序。
对于降序,按照相反顺序处理之前列出的步骤。
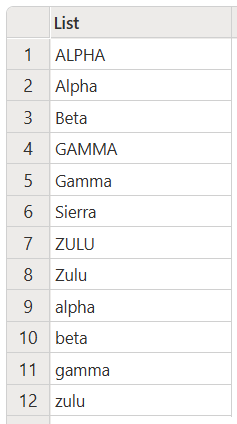
例如,下面的示例混合使用所有小写、所有大写和正确的大小写文本,以升序排序。
let
Source = { "Alpha", "Beta", "Zulu", "ALPHA", "gamma", "alpha",
"beta", "Gamma", "Sierra", "zulu", "GAMMA", "ZULU" },
SortedList = List.Sort(Source, Order.Ascending)
in
SortedList
此代码生成以下输出:
虽然不常见,但文本中可能混合使用大写字母和小写字母进行排序。 在这种情况下,升序排序顺序为:
- 以大写字母开头的列表或表列中的任何文本都是第一个。
- 如果有匹配的文本,则接下来将处理左侧包含最多大写字母的文本。
- 然后对小写字母进行排序,首先将最多的大写字母排列在右侧。
在任何情况下,在排序之前,将文本转换为一致的大小写可能更方便。
Power BI Desktop 规范化
Power Query M 区分大小写,并区分相同文本的不同大小写形式。 例如,“Foo”、“foo”和“FOO”被视为不同的事物。 但是,将数据加载到 Power BI Desktop 中时,文本值将规范化,这意味着无论其大小写如何,Power BI Desktop 都会将它们视为相同的值。 因此,如果需要在保持数据中区分大小写的同时转换数据,则应在将数据加载到 Power BI Desktop 之前在 Power Query 中处理数据转换。
例如,Power Query 中的下表显示了表中每一行的不同情况。
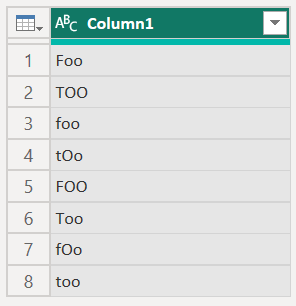
将此表加载到 Power BI Desktop 中时,文本值将规范化,从而导致下表。
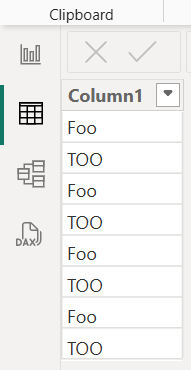
“foo”的第一个实例和“too”的第一个实例决定了 Power BI Desktop 表中其余行中“foo”和“too”的情况。 在此示例中,“foo”的所有实例都规范化为值“Foo”,“too”的所有实例都规范化为值“TOO”。