背景
目前,AI 模型正在演变为变得更加实质性,需要对高级硬件的需求不断增加,以及一组计算机进行高效模型训练。 HPC Pack 可以有效地简化模型训练工作。
PyTorch 分布式数据并行 (aka DDP)
若要实现分布式模型训练,必须利用分布式训练框架。 框架的选择取决于用于生成模型的框架。 本文将指导你了解如何在 HPC Pack 中继续使用 PyTorch。
PyTorch 提供了多种分布式训练方法。 其中,分布式数据并行(DDP)由于当前单机训练模型所需的简单性和最少的代码更改,因此被广泛首选。
为 AI 模型训练设置 HPC Pack 群集
可以在 Azure 上使用本地计算机或虚拟机(VM)设置 HPC Pack 群集。 只需确保这些计算机配备了 GPU(在本文中,我们将使用 Nvidia GPU)。
通常,一个 GPU 可以有一个用于分布式训练工作的进程。 因此,如果你有两台计算机(即计算机群集中的节点),每个计算机都配备了四个 GPU,则可以实现 2 * 4,相当于单个模型训练的 8 个并行进程。 与单个进程训练相比,此配置可能会将训练时间减少到大约 1/8,省略了在进程之间同步数据的一些开销。
在 ARM 模板中创建 HPC Pack 群集
为简单起见,可以在 Azure 上,在 GitHub
选择模板“适用于 Linux 工作负荷的单头节点群集”,然后单击“部署到 Azure”
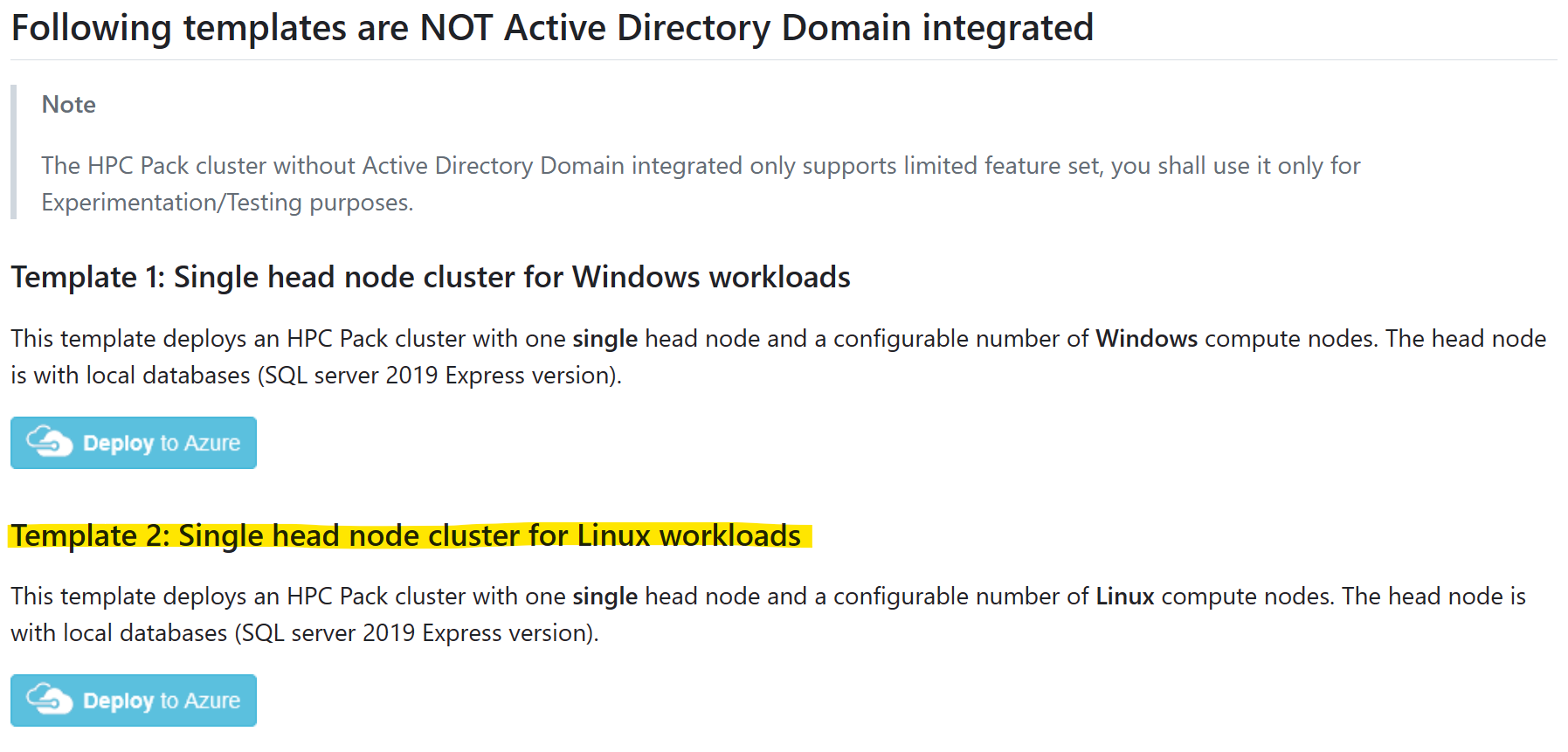
请参阅 先决条件,了解如何创建和上传证书以使用 HPC Pack。
请注意:
应选择标记为“HPC”的计算节点映像。 这表示在映像中预安装了 GPU 驱动程序。 如果未能这样做,需要在更高阶段在计算节点上安装手动 GPU 驱动程序,这可能是一项具有挑战性的任务,因为 GPU 驱动程序安装的复杂性。 有关 HPC 映像的详细信息,请参阅此处
。 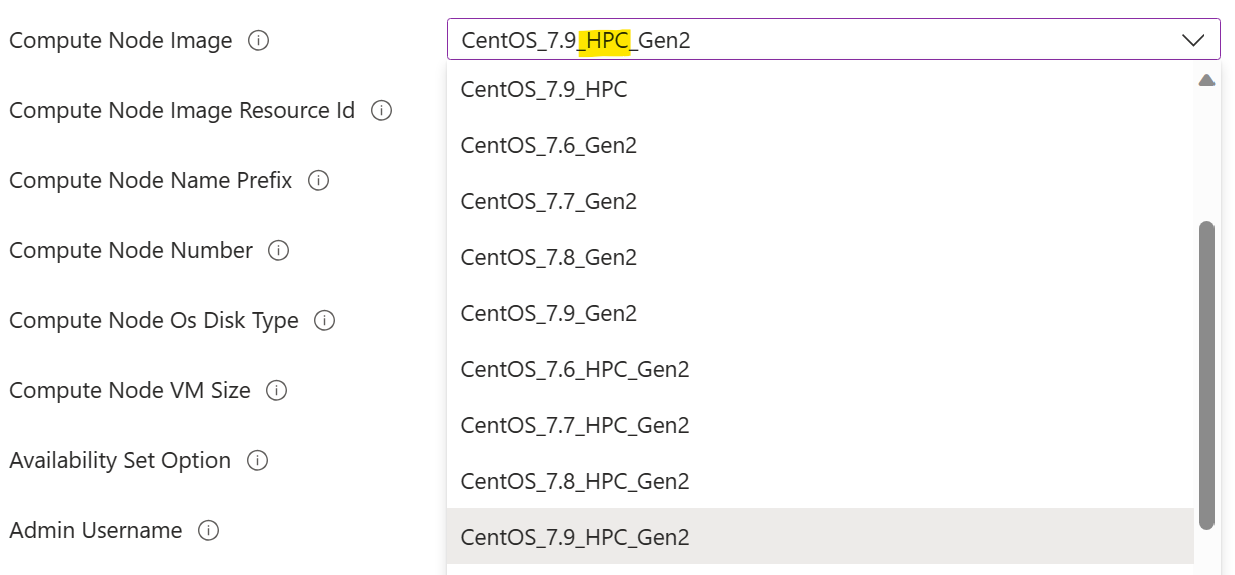
应选择具有 GPU 的计算节点 VM 大小。 这是 N 系列 VM 大小。
 选择 VM 大小
选择 VM 大小
在计算节点上安装 PyTorch
在每个计算节点上,使用命令安装 PyTorch
pip3 install torch torchvision torchaudio
提示:可以利用 HPC Pack“运行命令” 跨一组群集节点并行运行命令。
设置共享目录
在运行训练作业之前,需要一个可供所有计算节点访问的共享目录。 该目录用于训练代码和数据(输入数据集和输出训练模型)。
可以在头节点上设置 SMB 共享目录,然后使用 cifs 在每个计算节点上装载它,如下所示:
在头节点上,在
%CCP_DATA%\SpoolDir下创建一个目录app,默认情况下,该目录已由 HPC Pack 共享为CcpSpoolDir。在计算节点上,装载
app目录,例如sudo mkdir /app sudo mount -t cifs //<your head node name>/CcpSpoolDir/app /app -o vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777注意:
- 可以在交互式 shell 中省略
password选项。 在这种情况下,系统会提示你输入它。 -
dir_mode和file_mode设置为 0777,以便任何 Linux 用户可以读取/写入它。 可以授予受限权限,但要进行混淆会更加复杂。
- 可以在交互式 shell 中省略
(可选)通过在
/etc/fstab中添加一行,使装载永久化,例如//<your head node name>/CcpSpoolDir/app cifs vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777 0 2此处需要
password。
运行训练作业
假设现在有两个 Linux 计算节点,每个节点有四个 NVidia v100 GPU。 我们已在每个节点上安装 PyTorch。 我们还设置了共享目录“app”。 现在我们可以开始我们的培训工作。
在这里,我使用的是基于 PyTorch DDP 构建的简单玩具模型。 可以在 GitHub上
将以下文件下载到头节点上的共享目录 %CCP_DATA%\SpoolDir\app
- neural_network.py
- operations.py
- run_ddp.py
然后,使用 Node 作为资源单元创建作业,并为作业创建两个节点,例如
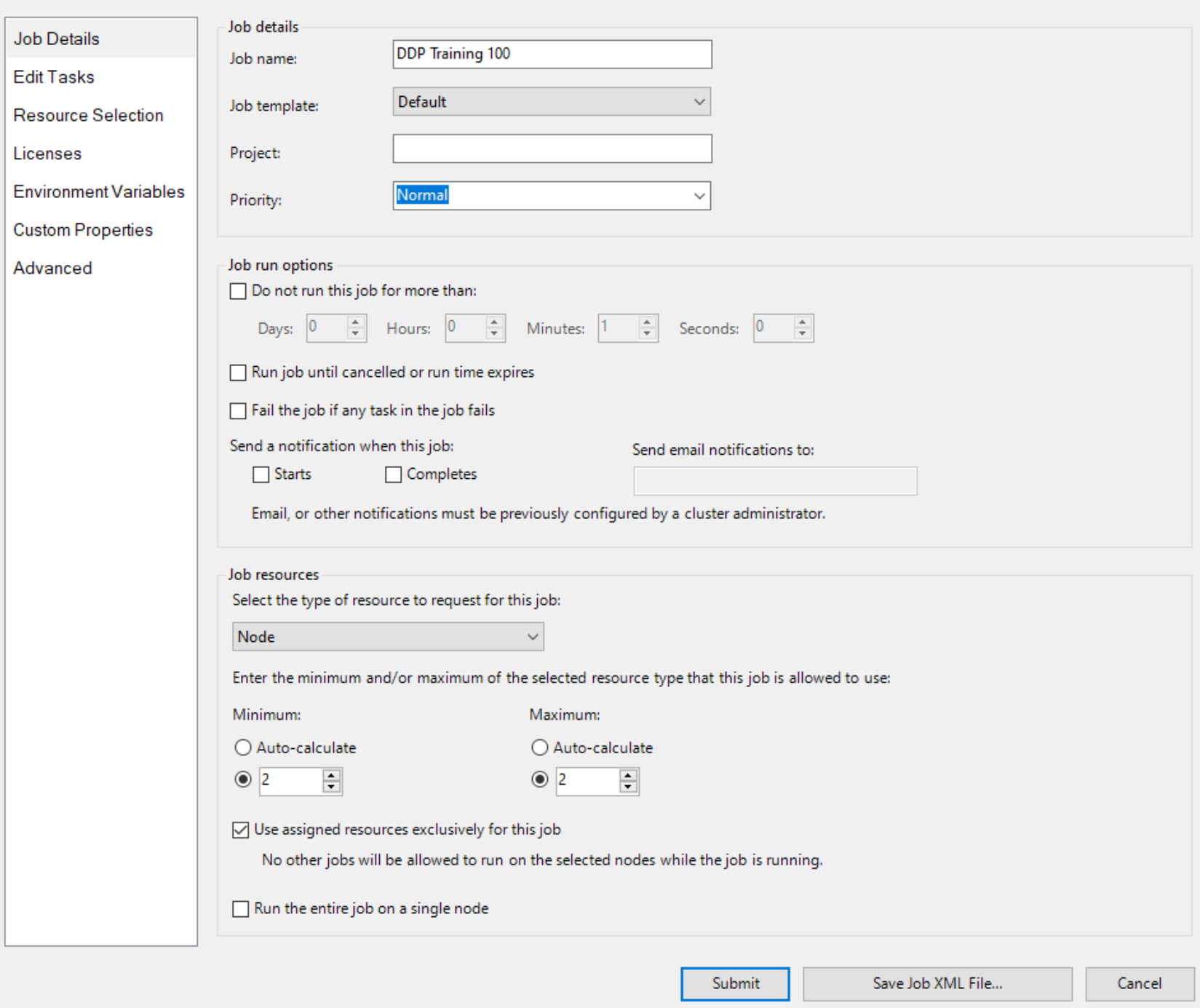
并显式指定两个具有 GPU 的节点,例如
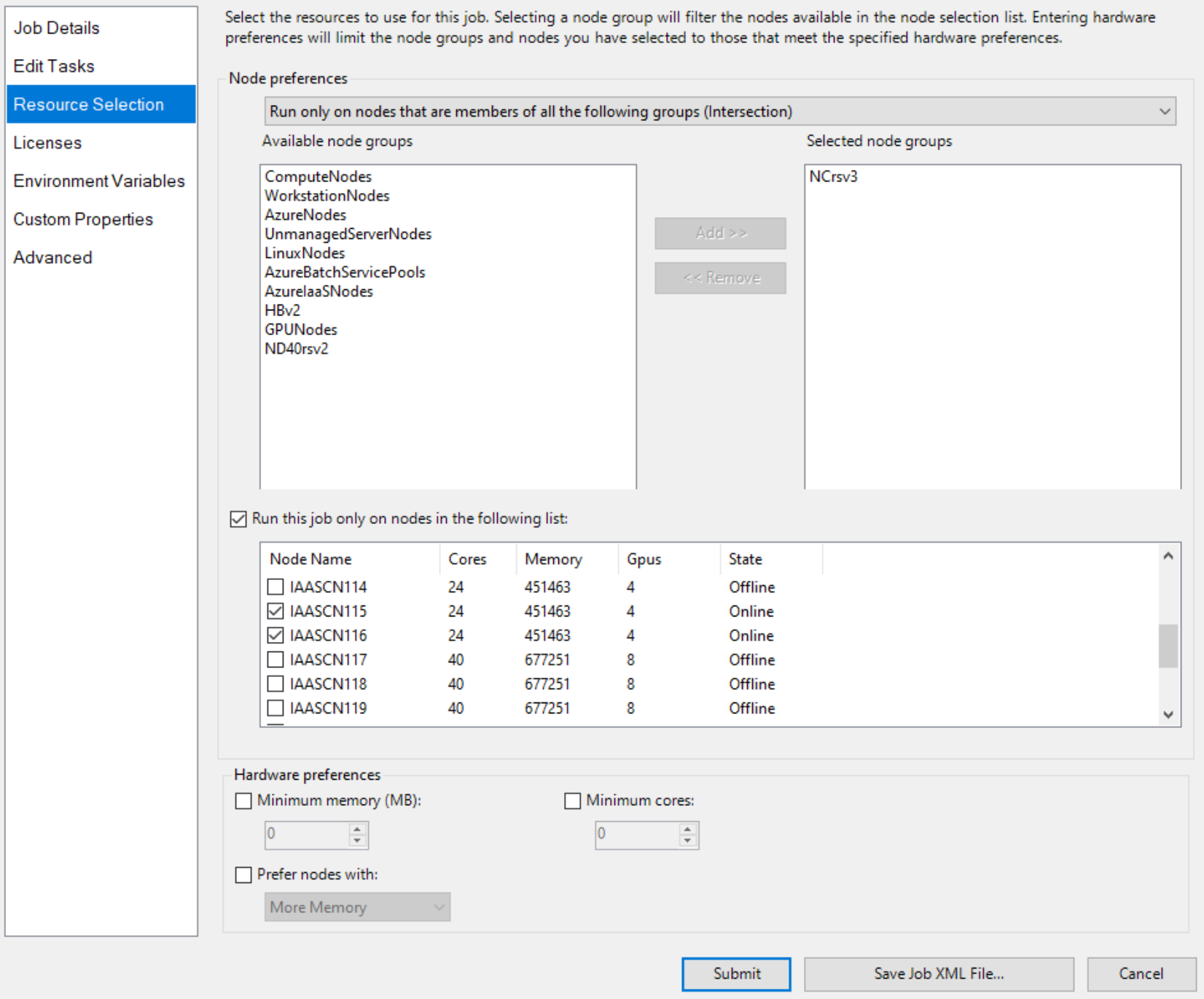
然后添加作业任务,例如
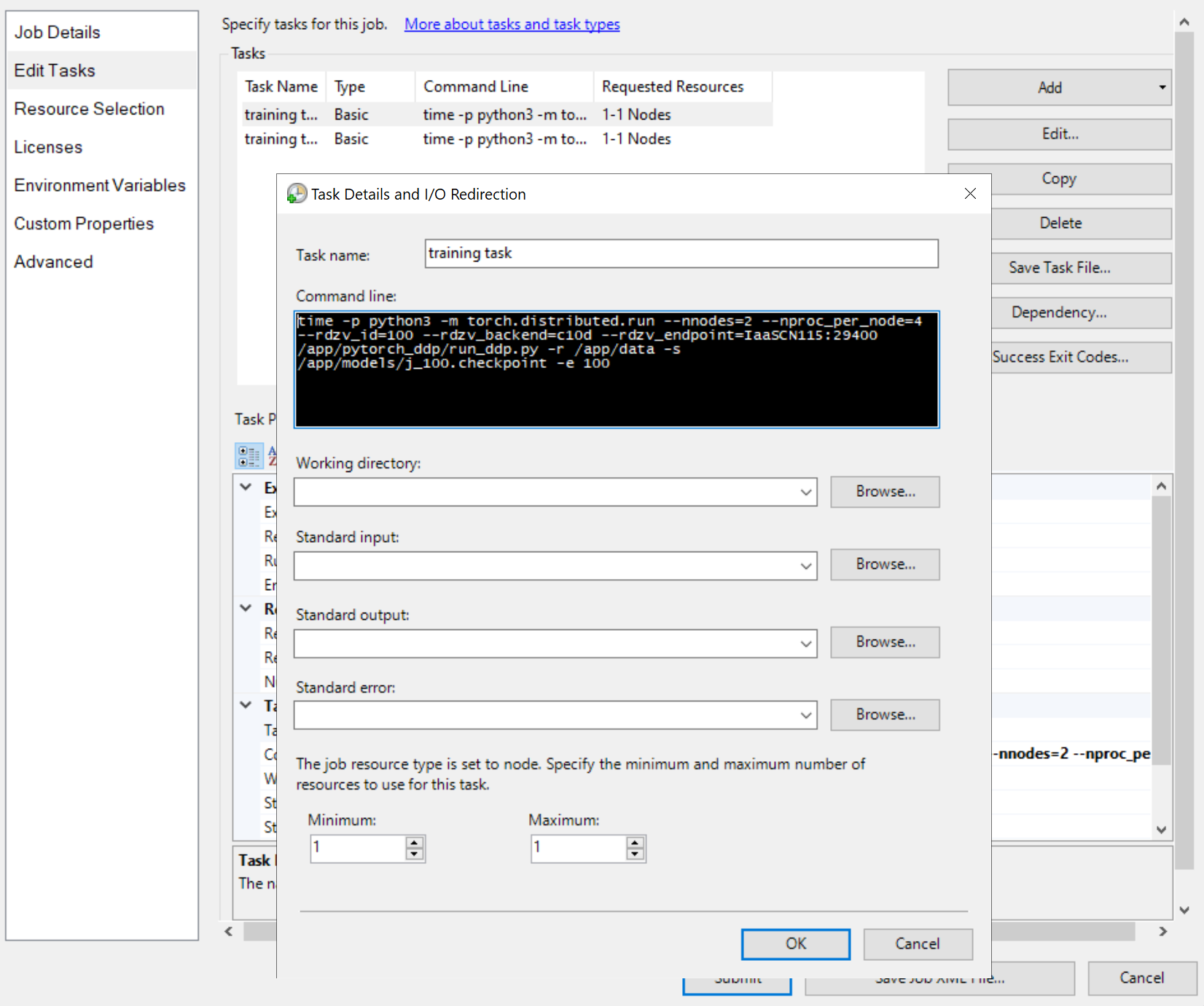
任务的命令行都相同,例如
python3 -m torch.distributed.run --nnodes=<the number of compute nodes> --nproc_per_node=<the processes on each node> --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=<a node name>:29400 /app/run_ddp.py
-
nnodes指定训练作业的计算节点数。 -
nproc_per_node指定每个计算节点上的进程数。 它不能超过节点上的 GPU 数。 也就是说,一个 GPU 最多可以有一个进程。 -
rdzv_endpoint指定充当 Rendezvous 的节点的名称和端口。 训练作业中的任何节点都可以工作。 - “/app/run_ddp.py”是训练代码文件的路径。 请记住,
/app是头节点上的共享目录。
提交作业并等待结果。 可以查看正在运行的任务,例如
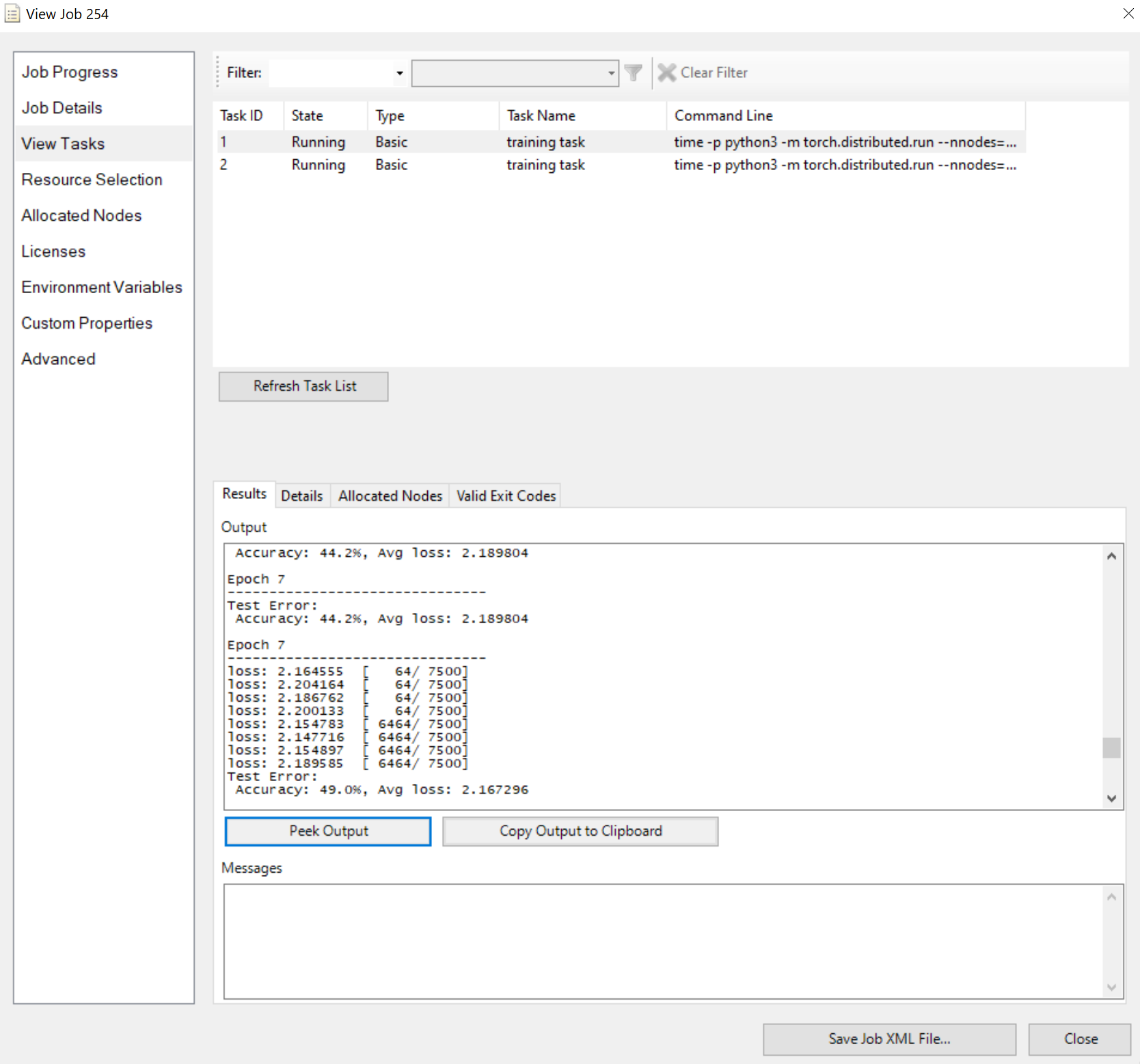
请注意,如果输出太长,“结果”窗格将显示截断的输出。
这一切都是这样。 我希望你获得积分,HPC Pack 可以加快训练工作速度。