适用于: 机器学习工作室(经典版)
机器学习工作室(经典版) Azure 机器学习
Azure 机器学习
重要
对机器学习工作室(经典)的支持将于 2024 年 8 月 31 日结束。 建议在该日期之前转换到 Azure 机器学习。
从 2021 年 12 月 1 日开始,你将无法创建新的机器学习工作室(经典)资源。 在 2024 年 8 月 31 日之前,可继续使用现有的机器学习工作室(经典)资源。
ML 工作室(经典)文档即将停用,将来可能不会更新。
本主题介绍如何在 机器学习 Studio(经典)中可视化和解释预测结果。 训练模型并根据它进行预测(“为模型评分”)后,需要了解并解释预测结果。
机器学习 Studio 中有四种主要的机器学习模型(经典):
- 分类
- 群集
- 回归分析
- 推荐系统
用于基于这些模型进行预测的模块包括:
- 用于分类和回归的评分模型模块
- 用于聚类分析的群集分配模块
- 推荐系统中的Matchbox 推荐器评分
了解如何 选择参数以优化 ML Studio(经典)中的算法。
若要了解如何评估模型,请参阅 如何评估模型性能。
如果你不熟悉 ML Studio(经典), 请了解如何创建简单的试验。
分类
分类问题有两个子类别:
- 只有两个类别的问题(二分类或二元分类)
- 多于两个类的问题(多类分类)
机器学习工作室(经典)使用不同的模块来处理其中的每一种分类,但用于解释其预测结果的方法都相似。
双类分类
示例实验
双类分类问题的一个示例是鸢尾花的分类。 任务是根据鸢尾花的特征进行分类。 机器学习工作室(经典)中提供的鸢尾花数据集是流行的鸢尾花数据集的子集,仅包含两种花卉种类(类 0 和类 1)的实例。 每个花卉有四个特征(花萼长度、花萼宽度、花瓣长度和花瓣宽度)。
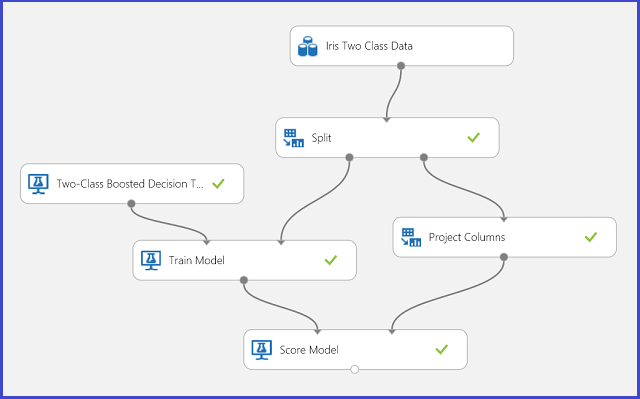
图 1. 鸢尾花二类分类问题实验
已执行实验来解决此问题,如图 1 所示。 已训练并评分双类提升决策树模型。 现在,可以可视化评分模型模块的预测结果,方法是单击评分模型模块的输出端口,并单击“可视化”。
这会显示评分结果,如图 2 所示。
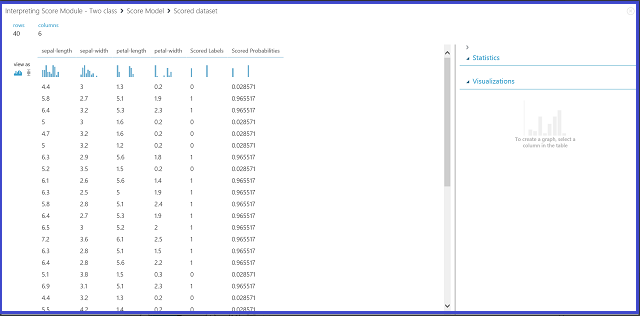
图 2. 在双类分类中可视化评分模型结果
结果解释
结果表中有六列。 左边的四列是这四个特征。 右边的两列“评分标签”和“评分概率”是预测结果。 “评分概率”列显示花卉属于正类(类 1)的概率。 例如,列中的第一个数字 (0.028571) 表示第一个花卉属于类 1 的概率为 0.028571。 “分数标签”列显示每个花卉的预测的类别。 这基于“评分概率”列。 如果花卉的评分概率大于 0.5,则它预测为类别 1。 否则,它预测为类 0。
Web 服务发布
在理解预测结果并确认其合理之后,可以将实验发布为 Web 服务,从而可以在各种应用程序中进行部署,并调用此服务以对任何新的鸢尾花进行分类预测。 若要了解如何将训练实验更改为评分实验并将其发布为 Web 服务,请参阅 教程 3:部署信用风险模型。 此过程给您提供评分实验,如图 3 所示。
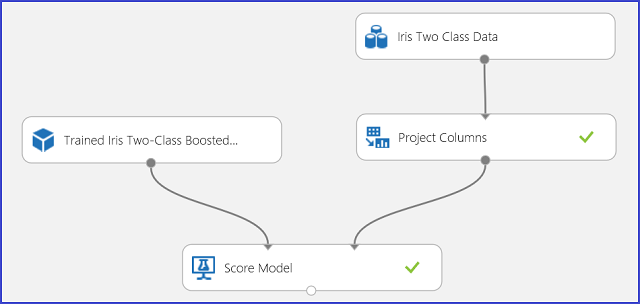
图 3. 对鸢尾花双类分类问题的实验进行评分
现在需要设置 Web 服务的输入和输出。 输入是评分模型的右输入端口,即鸢尾花特征输入。 输出的选择依据于是否对预测的类(评分标签)、评分概率或者两者都感兴趣。 在本示例中,假设用户对两者都感兴趣。 若要选择所需的输出列,请使用选择数据集中的列模块。 单击选择数据集中的列,单击“启动列选择器”,并选择“评分标签”和“评分概率”。 设置选择数据集中的列的输出端口并再次运行它之后,应准备好通过单击“发布 Web 服务”将评分实验发布为 Web 服务。 最终实验类似于图 4。
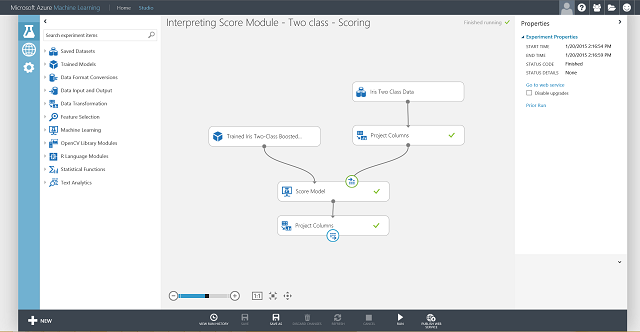
图 4. 鸢尾花双类分类问题的最后评分实验
运行 Web 服务并输入测试实例的某些特征值后,结果返回两个数字。 第一个数字是评分标签,第二个数字是评分概率。 此花卉预测为类 1,概率为 0.9655。
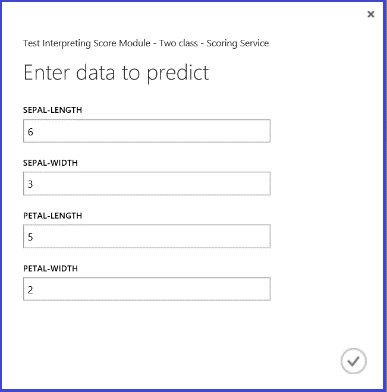

图 5. 鸢尾花双类分类的 Web 服务结果
多类分类
示例实验
在此实验中,执行字母识别任务作为多类分类的示例。 分类器尝试根据从手写图像中提取的一些手写属性值来预测特定字母 %28class%29。
在训练数据中,有 16 个从手写字母图像中提取的特征。 26 个字母组成了 26 个班级。 图 6 显示一个实验,该实验将训练多类分类模型进行字母识别,并对测试数据集上的相同特征集进行预测。
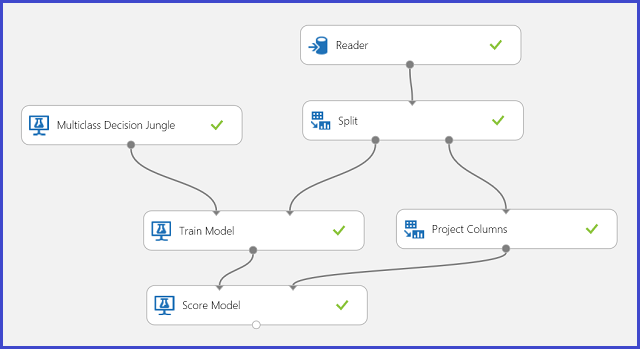
图 6. 字母识别多类分类实验问题
可视化评分模型模块的结果,方法是单击评分模型模块的输出端口,并单击“可视化”,应看到如图 7 所示的内容。
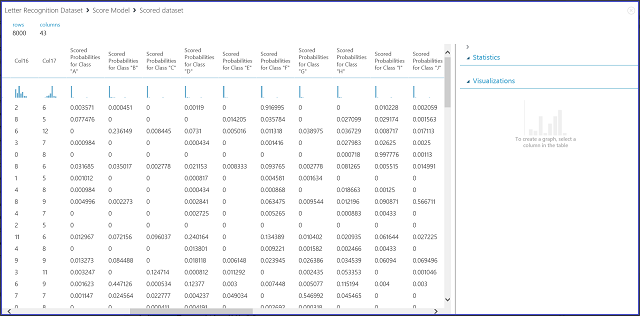
图 7. 可视化多类分类中的评分模型结果
结果解释
左边的 16 个列表示测试集的特征值。 列名为“类‘XX’评分概率”的列与双类情况中的“评分概率”列类似。 它们显示对应的项归入特定类的概率。 例如,对于第一个条目,有 0.003571 概率,即它是“A”,0.000451 概率,它是“B”,依此类推。 最后一列(评分标签)与二分类情况下的评分标签相同。 它选择具有最大评分概率的类作为对应项的预测类。 例如,对于第一个条目,评分标签为“F”,因为它的最大概率为“F”(0.916995)。
Web 服务的发布
还可获取每个项的评分标签和评分标签的概率。 基本逻辑是查找所有评分概率中最大的概率。 若要执行此操作,需要使用执行 R 脚本模块。 R 代码显示在图 8 中,实验结果显示在图 9 中。

图 8. 用于提取评分标签及标签的关联概率的 R 代码
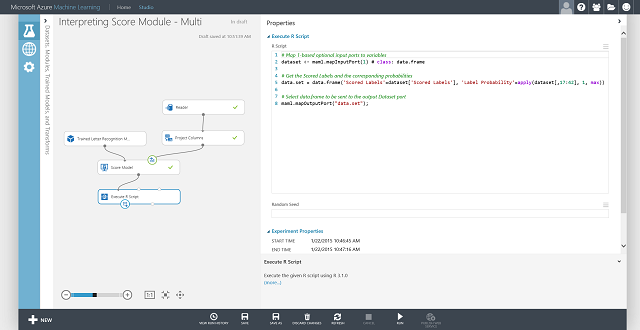
图 9. 字母识别多类分类问题的最终评分实验
发布和运行 Web 服务并输入某些输入特征值后,返回的结果类似于图 10。 这封手写信通过提取的16个特征预测为字母“T”,预测概率为0.9715。
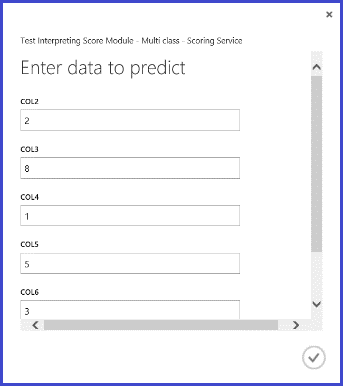

图 10. 多类分类的 Web 服务结果
回归
回归问题不同于分类问题。 在分类问题中,将尝试预测离散类,如鸢尾花所属的类。 但是,正如以下回归问题示例所示,将尝试预测连续变量,如一辆汽车的价格。
示例实验
使用汽车价格预测作为回归的示例。 将尝试根据特征预测汽车的价格,包括型号、燃料类型、车身类型和驱动轮。 实验显示在图 11 中。
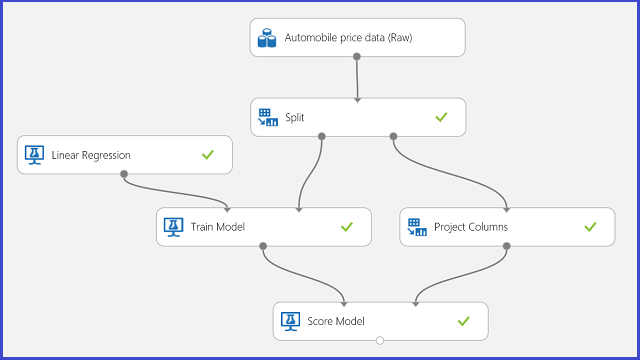
图 11. 汽车价格回归问题实验
可视化评分模型模块,结果类似于图 12。
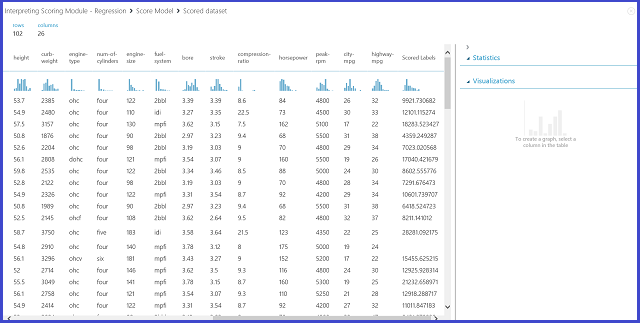
图 12. 汽车价格预测问题的评分结果
结果解释
评分标签是此评分结果中的结果列。 数字是每辆车的预测价格。
Web 服务发布
可将回归实验发布到 Web 服务中,并调用它进行汽车价格预测,与双类分类用例方法相同。
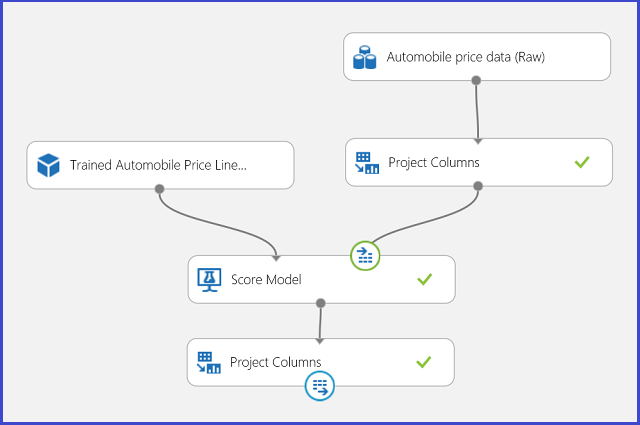
图 13. 汽车价格回归问题的评分实验
运行 Web 服务,返回的结果类似于图 14。 此汽车的预测价格为 15085.52 美元。
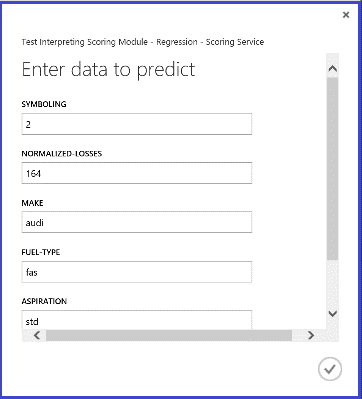

图 14. 汽车价格回归问题的 Web 服务结果
群集
示例实验
让我们再次使用鸢尾花数据集来开展聚类实验。 可在此处筛选出数据集中的类标签,以便它仅具有特征,并且可用于聚类。 在此鸢尾花用例中,在训练过程中将群集的数量指定为二,这意味着将花卉聚类为两个类。 实验显示在图 15 中。
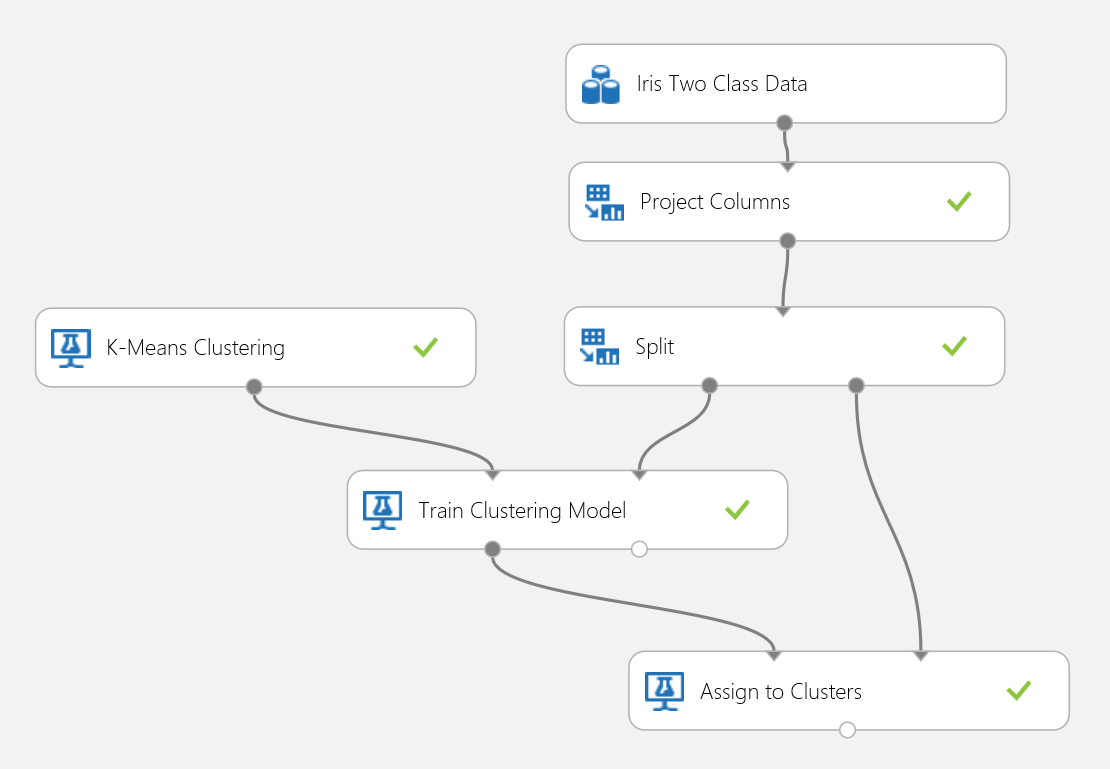
图 15. 鸢尾花聚类问题实验
聚类分析不同于分类,即训练数据集本身没有实数标签。 聚类将训练数据集实例分组为离散群集。 在训练过程中,模型通过学习项特征之间的差异来标记这些项。 在那之后,训练的模型可以用于进一步分类将来的数据。 在聚类问题中,我们对结果的两个部分感兴趣。 第一个部分是标记训练数据集,第二个部分是使用训练的模型对新数据集进行分类。
要可视化结果的第一部分,需要单击训练聚类模型的左输出端口,然后点击可视化。 可视化显示在图 16 中。
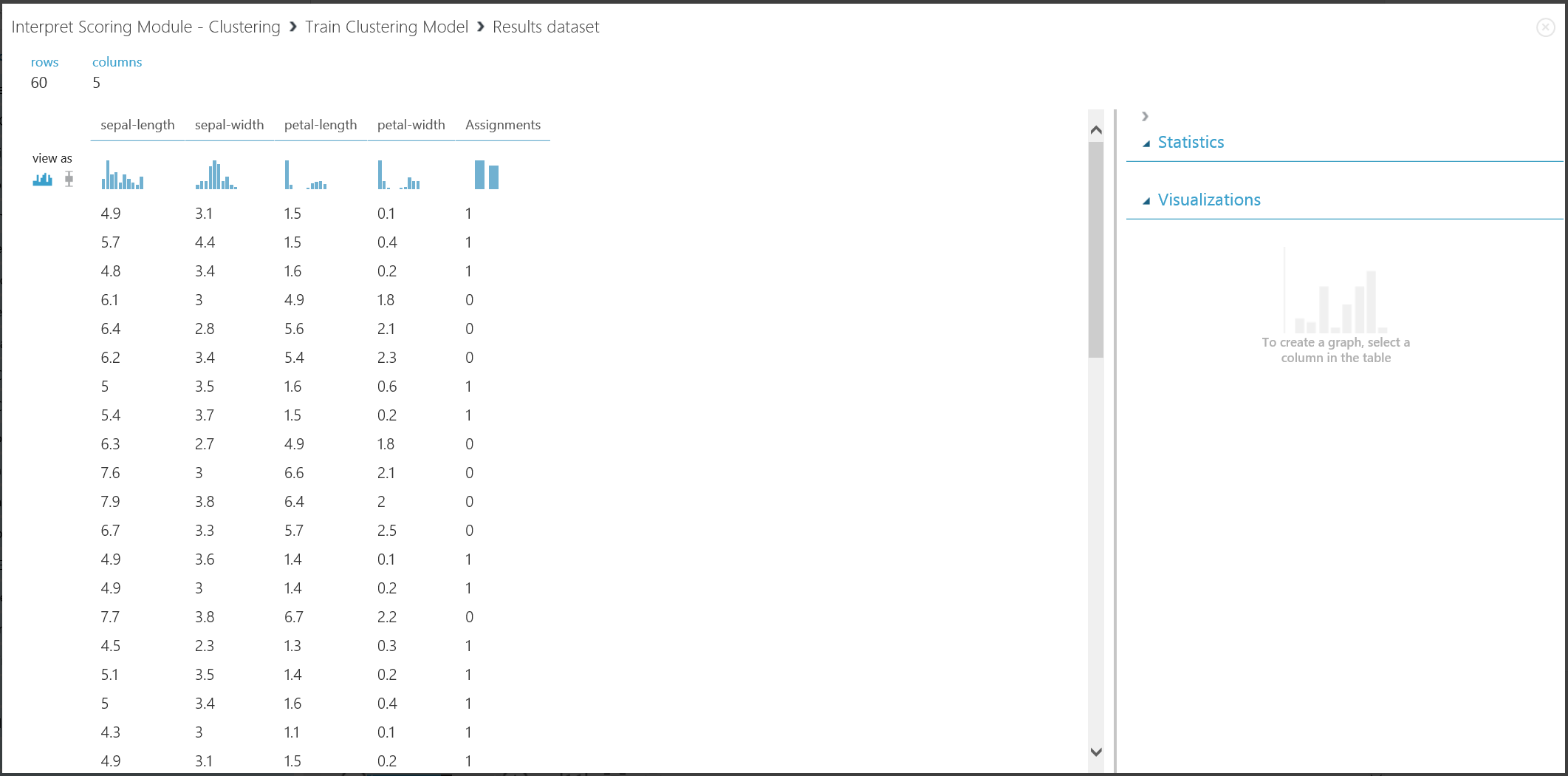
图 16. 可视化训练数据集的聚类结果
使用训练的聚类模型对新项进行聚类的结果显示在图 17 中。
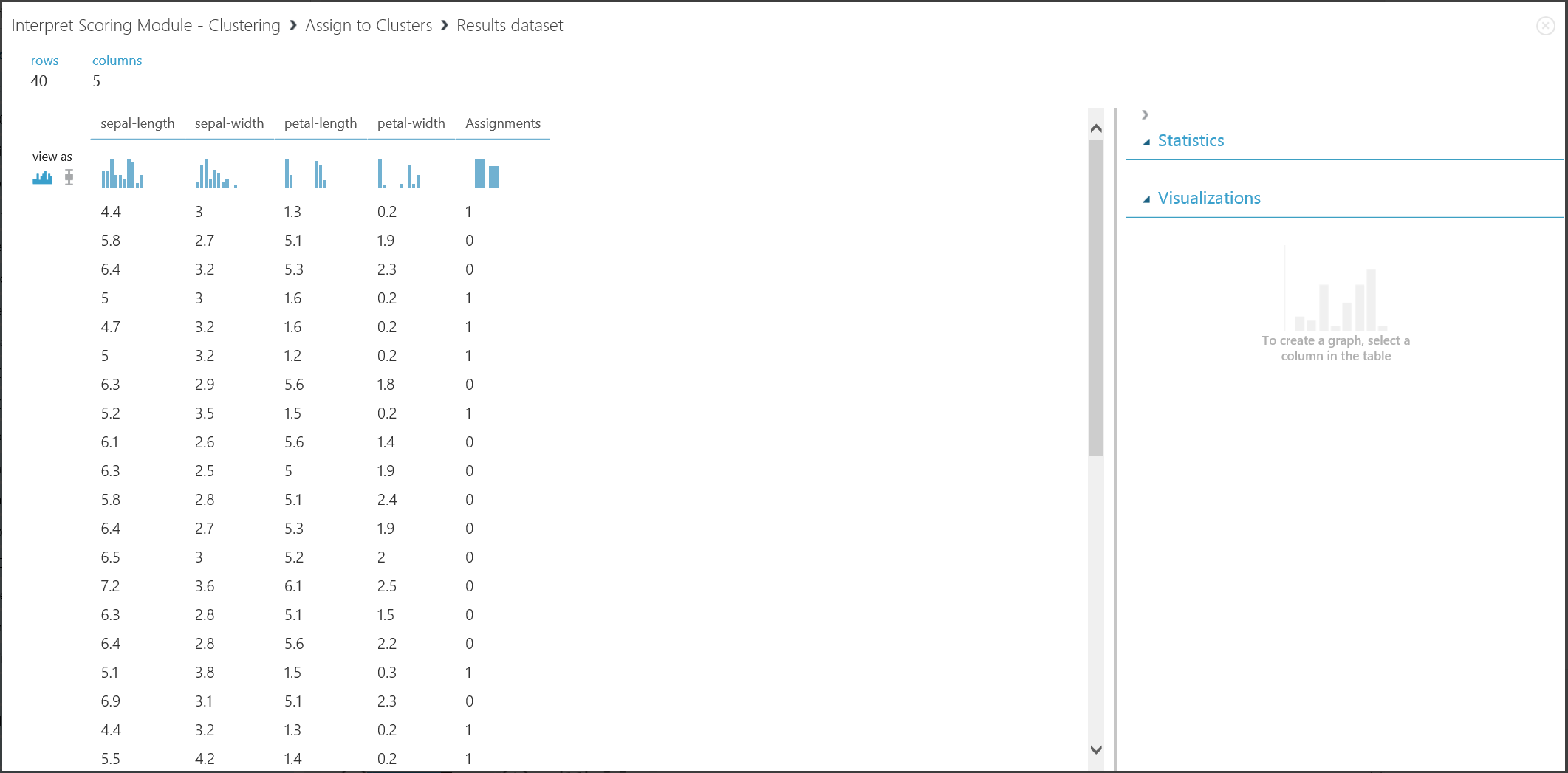
图 17. 可视化新数据集的聚类结果
结果解释
尽管两个部分的结果源于不同实验阶段,但它们看起来相同,并且以相同方式解释。 前四列是功能。 最后一列“分配”是预测结果。 分配有相同数字的项预测为在同一个群集中,即,它们在某些方面具有相似性(此实验使用默认的欧几里德距离度量)。 由于已将群集的数量指定为 2,因此“分配”中的项标记为 0 或 1。
Web 服务发布
可将聚类实验发布到 Web 服务中,并调用它进行聚类预测,与双类分类用例方法相同。
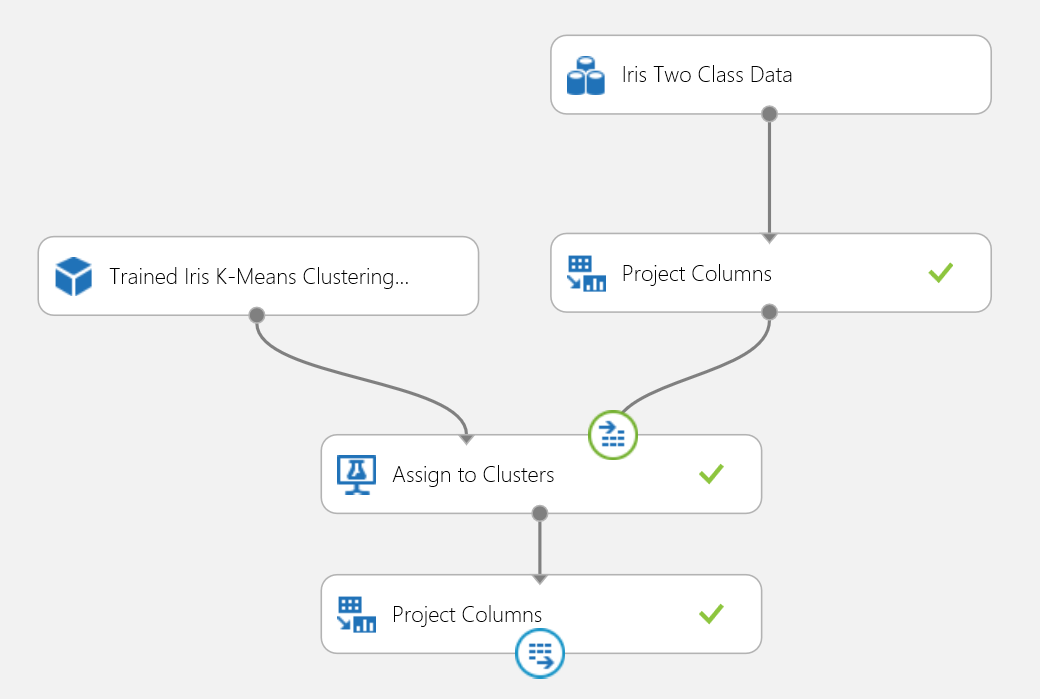
图 18. 鸢尾花聚类问题的评分实验
运行 Web 服务后,返回的结果类似于图 19。 预测此花卉属于群集 0。
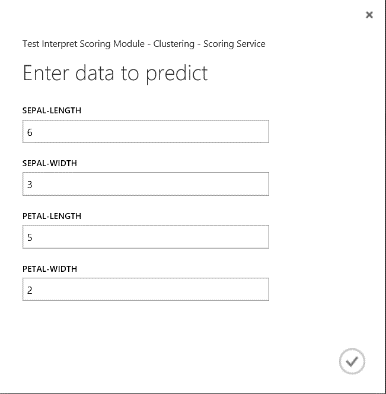

图 19. 鸢尾花双类分类的 Web 服务结果
推荐系统
示例实验
对于推荐器系统,可使用餐厅推荐问题作为示例:可基于评级历史记录为客户推荐餐厅。 输入数据由三部分组成:
- 来自客户的餐厅评级
- 客户特征数据
- 餐馆特色数据
在机器学习工作室(经典版)中的 Matchbox 推荐器 模块,我们可以执行多个操作:
- 预测给定用户和项目的评级
- 向给定用户推荐项目
- 查找与给定用户相关的用户
- 查找与给定项目相关的项目
通过从“推荐器预测类型”菜单中的四种选项中选择,可选择要执行的操作。 这里你可以体验所有四种情境。
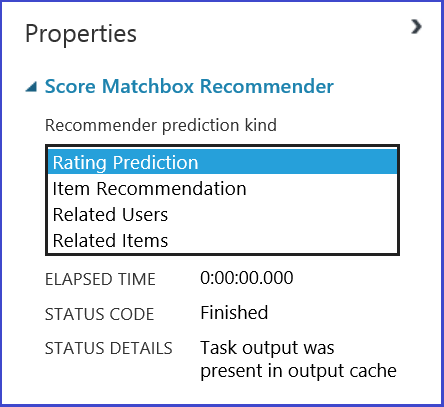
推荐器系统的典型机器学习工作室(经典)试验类似于图 20。 有关如何使用这些推荐系统模块的信息,请参阅 Matchbox 推荐器训练,以及 Matchbox 推荐器评估。
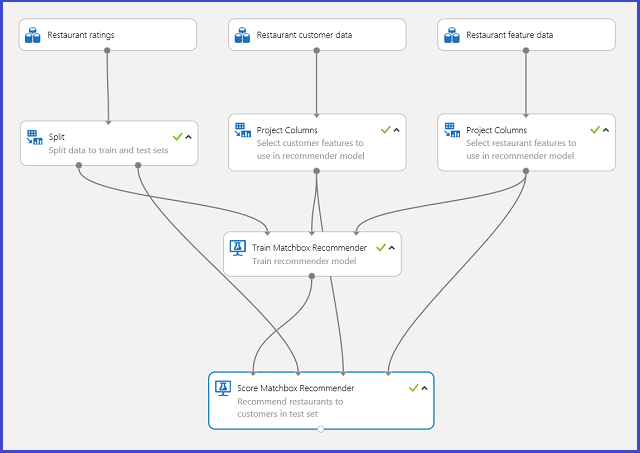
图 20. 推荐系统实验
结果解释
预测给定用户和项目的评级
选择“推荐器预测类型”下的“评分预测”即要求推荐器系统预测给定用户和项目的评级。 Score Matchbox Recommender的输出可视化类似于图 21。
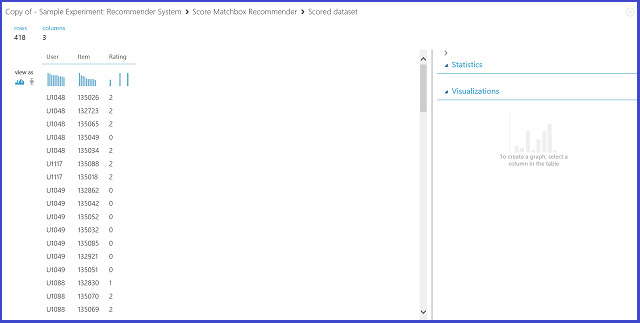
图 21. 可视化推荐器系统的评分结果 - 评级预测
输入数据提供的前两列是用户-项目对。 第三列是用户对特定项目的预测评级。 例如,在第一行中,客户 U1048 被预测将餐厅 135026 评级为 2。
向给定用户推荐项目
选择“推荐器预测类型”下的“项目推荐”即要求推荐器系统向给定用户推荐项目。 此方案中要选择的最后一个参数是推荐项目选择。 选项“来自评级项目(用于模型评估)”主要用于训练过程中对模型的评估。 对于此预测阶段,我们选择从所有项目。 Score Matchbox Recommender 输出的可视化似图 22。
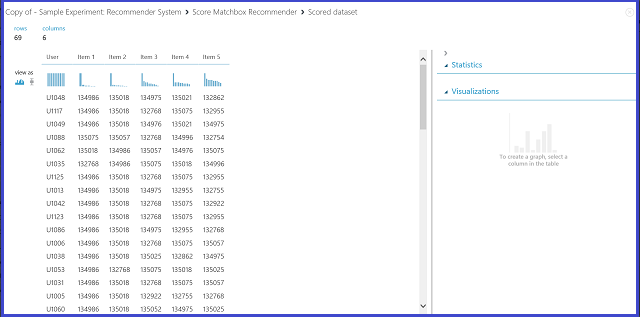
图 22. 可视化推荐器系统的评分结果 - 项目推荐
六列中的第一列代表输入数据提供的用户 ID,这是用于推荐项目的依据。 其他五列表示向该用户推荐的项目,以相关度降序排序。 例如,在第一行中,对客户 U1048 最推荐的餐厅为 134986,然后依次为 135018、134975、135021 和 132862。
查找与给定用户相关的用户
选择“推荐器预测类型”下的“相关用户”即要求推荐器系统查找给定用户的相关用户。 相关用户是具有相似偏好的用户。 此方案中要选择的最后一个参数是相关用户选择。 选项来自对项目进行评级的用户(用于模型评估)主要用于训练过程中的模型评估。 在此预测阶段,选择从所有用户。 Matchbox 推荐器评分输出的可视化类似于图 23。
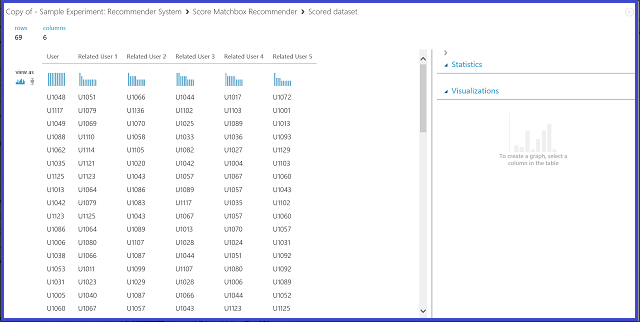
图 23. 可视化推荐器系统的评分结果--相关用户
六列中的第一列显示查找相关用户所需的给定用户 ID,由输入数据提供。 其他五列存储该用户的预测相关用户,以相关度降序排序。 例如,在第一行中,客户 U1048 最相关的客户是 U1051,然后依次为 U1066、U1044、U1017 和 U1072。
查找与给定项目相关的项目
选择“推荐器预测类型”下的“相关项目”即要求推荐器系统查找给定项目的相关项目。 相关项目是同一个用户最有可能喜欢的项目。 此方案中要选择的最后一个参数是相关项目选择。 选项“来自评级项目(用于模型评估)”主要用于训练过程中对模型的评估。 在此预测阶段,我们选择从所有项目。 Score Matchbox 推荐器输出的可视化图像类似于图 24。
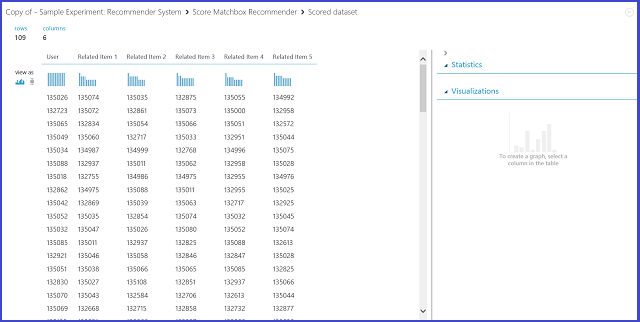
图 24. 可视化推荐器系统的评分结果--相关项目
六列中的第一列表示查找相关项目所需的给定项目 ID,由输入数据提供。 其他五列存储该项目的预测相关项目,以相关度降序排序。 例如,在第一行中,项目 135026 最相关的项目为 135074,然后依次为 135035、132875、135055 和 134992。
Web 服务发布
对于这四个方案中的每一个,将这些实验发布为 Web 服务以获取预测的过程都类似。 此处我们以第二个方案(向给定用户的推荐项目)为例。 对于其他三个方案,可遵循相同的过程。
将训练的推荐器系统保存为训练的模型并根据请求将输入数据筛选到单个用户 ID 列,可挂钩该实验(如图 25 所示)并将其发布为 Web 服务。
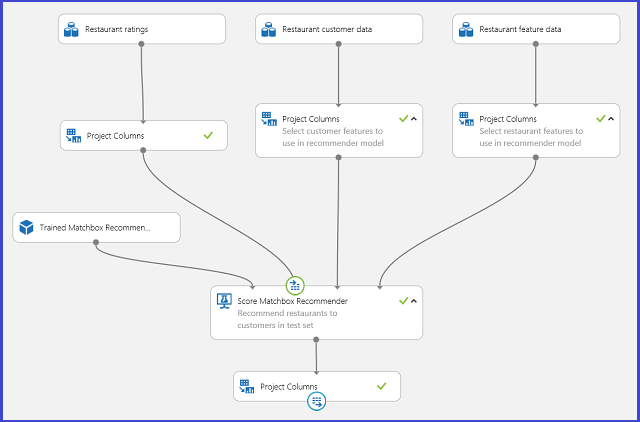
图 25. 餐厅推荐问题的评分实验
运行 Web 服务,返回的结果类似于图 26。 对用户 U1048 最推荐的五个餐厅为 134986、135018、134975、135021 和 132862。
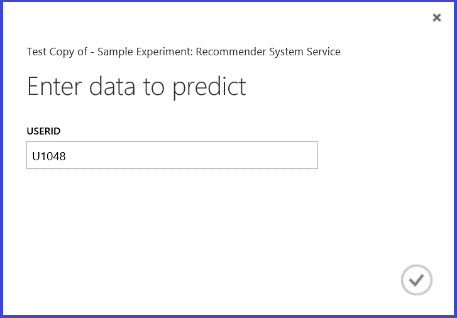

图 26. 餐厅推荐问题的 Web 服务结果