Microsoft聚类分析算法是由 Analysis Services 提供的分段算法。 该算法使用迭代技术将数据集中的事例分组到包含类似特征的群集中。 这些分组可用于浏览数据、识别数据中的异常以及创建预测。
聚类分析模型识别数据集中通过粗略观察可能无法逻辑推导出的关系。 例如,从逻辑上讲,你可以辨别出那些骑自行车上下班的人通常住得离工作地点不远。 然而,该算法可以找到自行车通勤者的其他特征,这些特征并不明显。 在下图中,分类 A 表示有关倾向于开车上班的人员的数据,而群集 B 表示有关倾向于骑自行车上班的人员的数据。

聚类分析算法与其他数据挖掘算法(如Microsoft决策树算法)不同,因为不必指定可预测列才能生成聚类分析模型。 聚类分析算法严格地从数据中存在的关系和算法标识的分类中训练模型。
示例:
请考虑一组共享类似人口统计信息的人员,以及从 Adventure Works 公司购买类似产品的人员。 此组人员表示一组数据。 数据库中可能存在多个此类群集。 通过观察构成群集的列,可以更清楚地了解数据集中的记录如何相互关联。
算法的工作原理
Microsoft聚类分析算法首先标识数据集中的关系,并根据这些关系生成一系列分类。 散点图是一种直观地表示算法如何对数据进行分组的有用方法,如下图所示。 散点图表示数据集中的所有事例,每个事例都是图形上的点。 簇将图中的点进行分组,并展示算法所识别的关系。
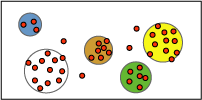
首先定义分类后,该算法将计算分类表示点的分组程度,然后尝试重新定义分组以创建更好地表示数据的分类。 该算法重复执行此过程,直到无法通过重新定义聚类来进一步提高结果。
可以通过选择指定聚类分析技术、限制最大群集数或更改创建群集所需的支持量来自定义算法的工作方式。 有关详细信息,请参阅 Microsoft聚类分析算法技术参考。
聚类分析模型所需的数据
准备用于训练聚类分析模型的数据时,应了解特定算法的要求,包括需要多少数据以及如何使用数据。
聚类分析模型的要求如下:
单个键列 每个模型必须包含一个唯一标识每个记录的数字或文本列。 不允许使用复合键。
输入列 每个模型必须至少包含一个输入列,该列包含用于生成分类的值。 可以根据需要拥有任意数量的输入列,但根据每列中的值数,增加额外列可以增加训练模型所需的时间。
可选的可预测列 该算法不需要可预测列来生成模型,但可以添加几乎任何数据类型的可预测列。 可预测列的值可以视为聚类分析模型的输入,也可以指定它仅用于预测。 例如,如果要通过聚类分析区域或年龄等人口统计数据来预测客户收入,可以指定收入
PredictOnly并添加所有其他列(如区域或年龄)作为输入。
有关聚类分析模型支持的内容类型和数据类型的更多详细信息,请参阅 Microsoft聚类分析算法技术参考的“要求”部分。
查看聚类分析模型
若要浏览模型,可以使用 Microsoft群集查看器。 查看聚类分析模型时,Analysis Services 在关系图中显示分类,并提供每个分类的详细配置文件、区分每个分类的属性列表以及整个训练数据集的特征。 有关详细信息,请参阅 使用Microsoft群集查看器浏览模型。
若要了解更多详细信息,可以在 Microsoft泛型内容树查看器中浏览模型。 为模型存储的内容包括每个节点中所有值的分布、每个分类的概率和其他信息。 有关详细信息,请参阅聚类模型的挖掘模型内容(Analysis Services - 数据挖掘)。
创建预测
训练模型后,结果将存储为一组模式,你可以浏览或使用这些模式进行预测。
可以创建查询来返回有关新数据是否适合已发现的群集的预测,或获取有关群集的描述性统计信息。
有关如何针对数据挖掘模型创建查询的信息,请参阅 数据挖掘查询。 有关如何对聚类分析模型使用查询的示例,请参阅 聚类分析模型查询示例。
注解
支持使用预测模型标记语言(PMML)创建挖掘模型。
支持钻取。
支持使用 OLAP 挖掘模型和创建数据挖掘维度。
另请参阅
数据挖掘算法(Analysis Services - 数据挖掘)Microsoft聚类算法技术参考聚类模型内容挖掘(Analysis Services - 数据挖掘)聚类模型查询示例